论文笔记 SAM 2 Segment Anything in Images and Videos
本文最后更新于:2025年7月18日 下午
论文笔记 SAM 2:Segment Anything in Images and Videos
论文链接:https://arxiv.org/abs/2408.00714
代码链接:https://github.com/facebookresearch/sam2
项目网站:https://ai.meta.com/sam2/
Meta出的SAM的续作,旨在对图像和视频进行Promptable Visual Segmantation(PVS),文章贡献了数据和模型,相较于SAM,SAM2可以对视频进行分割,且提升了图像上的分割速度。
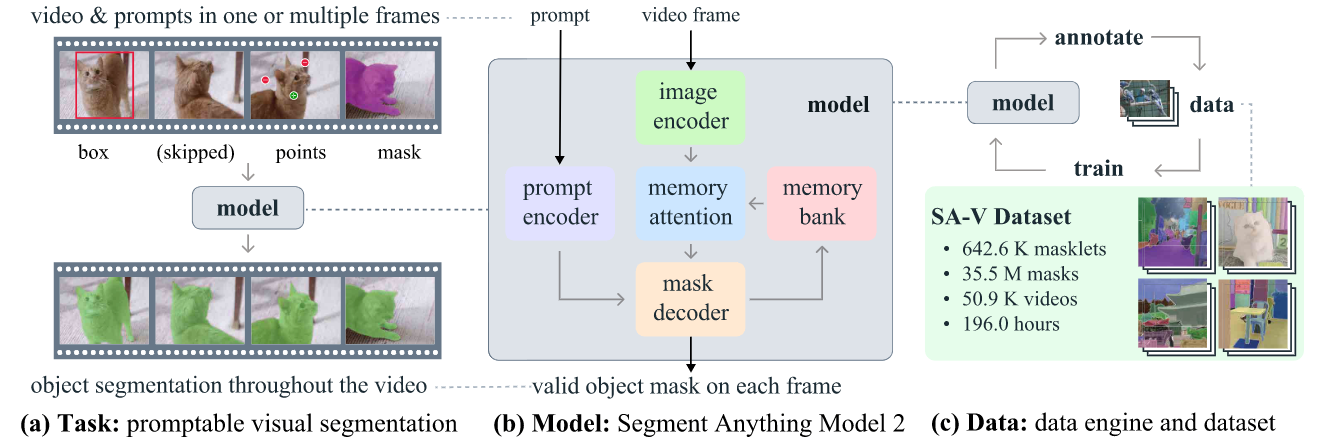
对于PVS任务,如上图(a)所示,用户可以用框、点或者mask作为prompt来进行分割,对于视频,只需要在几帧中进行提示即可,不需要每一帧都提示(甚至可以只标一个点,后续SAM2会自动跟踪)。
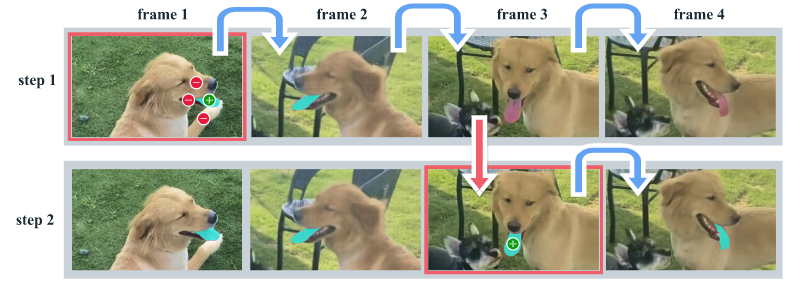
如上图所示,对一帧进行标注可能会遇到后续丢失的情况,这个时候只需要补充一个点就可以,非常适合用户的交互。
在架构上,为了处理视频,添加了Memory的部分,之前的预测存入memory bank中,然后在下一次预测前通过memory attention进行特征融合。
在数据上,延续了前作的风格,使用了渐进式的数据构建,一边训练模型,一边用训练的模型辅助标记数据,再用新的数据训练更好的模型。
模型:SAM 2
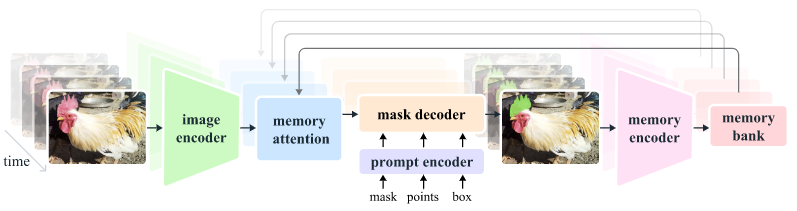
Image Encoder
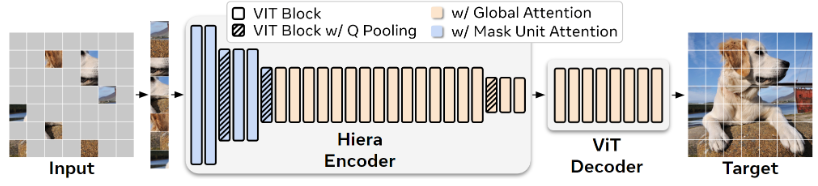
图像编码器使用了Meta自家出的Hiera编码器[1],如上图所示,Hiera采用了MAE的训练方式,架构上使用了Hierarchical的结构,每个Stage后,特征维度翻倍、空间维度减为1/4。
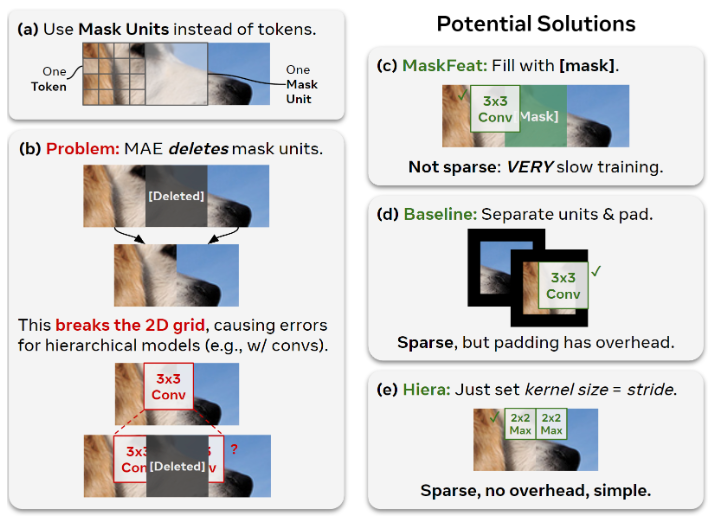
Hiera主要解决MAE破坏2D网格的问题,如上图所示,传统MAE为了实现sparsity,会破坏不同区域之间的相邻性(编码时相邻token不空间相邻),Hiera将图像分成多个Mask Unit,一个Mask Unit包含多个token,在进行mask的时候,删除一整个mask unit,并且在模型设计上避免卷积在不同unit之间进行。此外,在前两个Stage,只在Mask Unit内部进行注意力机制。
Memory Attention
该模块旨在根据以往帧特征、以往预测、新提示来得到当前帧的特征。由L(4)个transformer blocks组成,每个block是一个self-attention(SA)和一个cross-attention(CA),后者的Key/Value是以往帧和object points的memory,这些memory后续保存在一个bank里。
在SA和CA中都使用了2D RoPE。
Prompt Encoder
这部分和SAM一模一样,但是完全去掉了文本模态,允许输入positive和negative的click、boxes、masks。click和boxes的prompt会经过编码,然后加上prompt类别的可学习embedding。mask的prompt则是通过卷积之后与图像特征相加,假如没有mask,则一个特殊的[NoMask]embedding会与embedding相加。
Mask Decoder
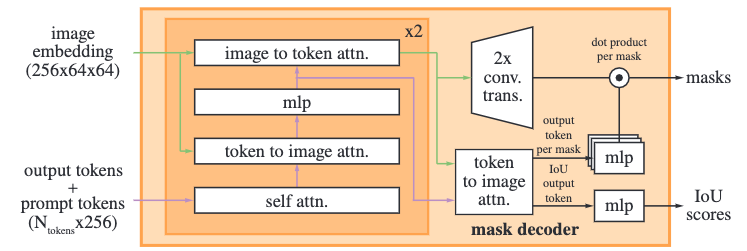
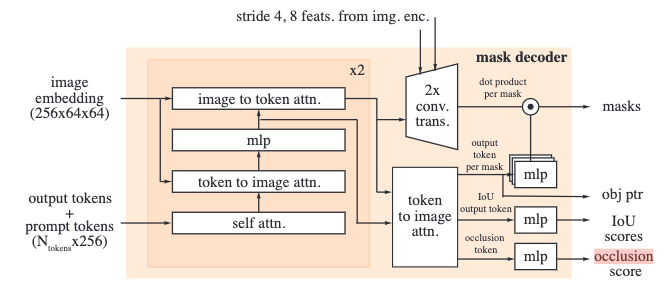
上面两张图分别是SAM1和SAM2的Mask Decoder的架构,大体和前代是一样的,混合了自注意力、交叉注意力和MLP。
对比下来,SAM 2新增了object pointer和occlusion score的输出。object pointer是放在memory bank中的、用来表示所标记的目标的特征。occlusion score则是用来表示当前帧是否包含之前标记的对象的一个二分类概率。此外,SAM 2还在输出阶段添加了两个stride的特征残差连接。
在输入的时候,图中的output tokens就对应了后面的各个输出,比如为了要输出occlusion score,就会在开头添加一个额外的[occlusion] token,然后后面取这个token对应的embedding过MLP进行输出。
SAM 2为了处理视频,还需要面另一个大问题,也就是画面中不存在对应的分割对象的情况。所以会学习一个occlusion score。
Memory Encoder & Memory Bank
Memory Encoder通过将mask进行卷积之后加上原始帧特征来产生memory特征。
Memory Bank包含三部分:
- 一个FIFO队列(First in first out),存放近N帧的特征
- 另一个FIFO队列,存放M帧带有提示的帧特征
- Object Pointers
1、3部分的特征会添加上时序信息。
数据:SA-V
构建方法(数据引擎)
构建数据采用了人机协同的方法,分成3个阶段:
- 使用一代SAM辅助人工标记收集到的图像和视频数据(把视频当作图像标注)。视频中的mask被称为masklet。
- 用所收集数据训练
SAM 2 Mask,这个模型只接收mask作为prompt。使用这个模型继续辅助人工标记数据,此时SAM 2级别一定对视频进行分割的能力,因此会加快。 - 使用之前的数据训练完整版本的SAM 2,训完一轮之后再用它来标,标完再训一个新的,这样重复5次。
此外,还有另一批标注者专门用来验证masklet的质量,假如object没有清晰边界(例如烟雾),那就排除它。
最后,由于人类关注独立的object,为了提升泛化性,作者加进行了auto masklet generation。也就是给SAM 2在第一帧一大堆点,然后得到许多masklet,再经过标注者评价。这一步得到的标注会覆盖很多非中心对象的object。
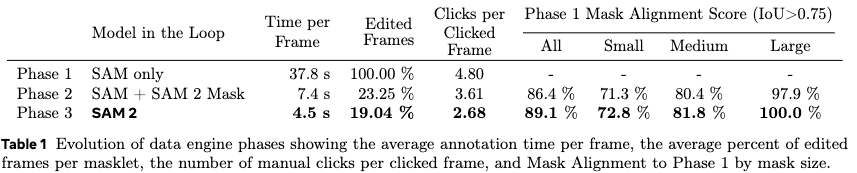
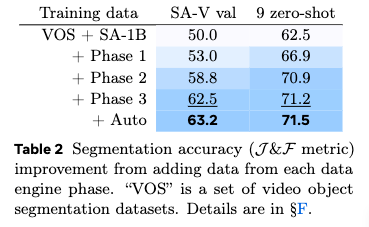
两个表显示了这种数据引擎的强大之处,human-in-the-loop!

这个图展示了Auto的强大之处(这背景是菜鸟驿站么……)。
最终公开的SA-V的数据
包含50.9K视频、642.6K masklets,数据众包获得,所以Meta可以大大方方公开数据!!!
masklets中有190.9K人工标注的和451.7K自动生成的(数据很密集!)。
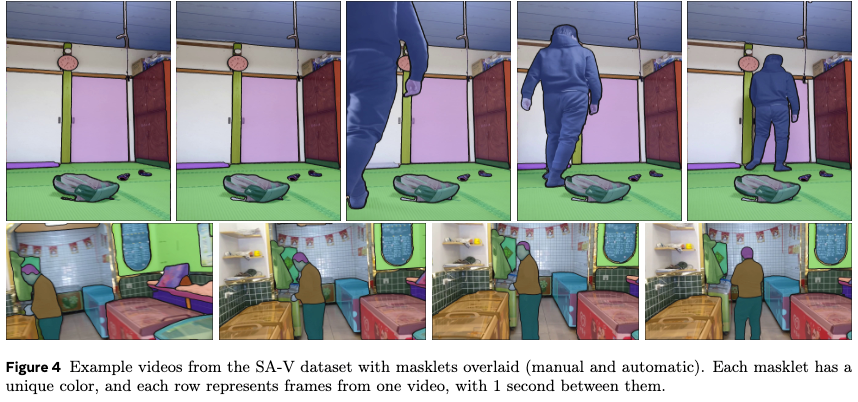
SA-V划分为了训练、验证和测试集,作者根据视频作者和位置,保证验证和测试中会有新的object,并且其中视频上人挑出来的更加困难的视频(包含快速运动的物体、中途消失的物体、消失又出现的物体)。验证测试集不大,验证集是155个视频+293 masklets,测试集则150视频+278 masklets。
Meta作为西方科技公司,有西方的政治正确,会保证数据的公平性,比如性别、年龄、地区等等。👍🏻
实验
对分割研究不深,所以实验给不出什么具体分析,基本就是在各种场景都SOTA。
总结与启发
从SAM 1就对Meta的工程和应用能力很欣赏,他们能够发掘出PVS这种任务,我觉得是十分有价值的。此外,一边标注一边训练的范式很有意思,不知道能不能用到我的研究中来。
- Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles ↩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!