论文笔记 Describe Anything Detailed Localized Image and Video Captioning
本文最后更新于:2025年7月18日 晚上
论文笔记 Describe Anything: Detailed Localized Image and Video Captioning
项目网站:https://describe-anything.github.io/
Nvidia的一篇ICCV 25论文,提出了一个指向性描述图像和视频的模型,结合SAM 2可以根据用户简单的几个点来描述视频中的的对象。文章提出了架构(DAM,Describe Anything Model)、半监督数据Pipeline(DLC-SDP)和benchmark(DLC-Bench)。
任务介绍

DAM旨在进行Detailed Localized Caption(DLC)的任务,用户对图像或视频,可以通过点、框、mask等等方式选择需要描述的区域,然后模型就会输出对应的详细描述。
模型:DAM
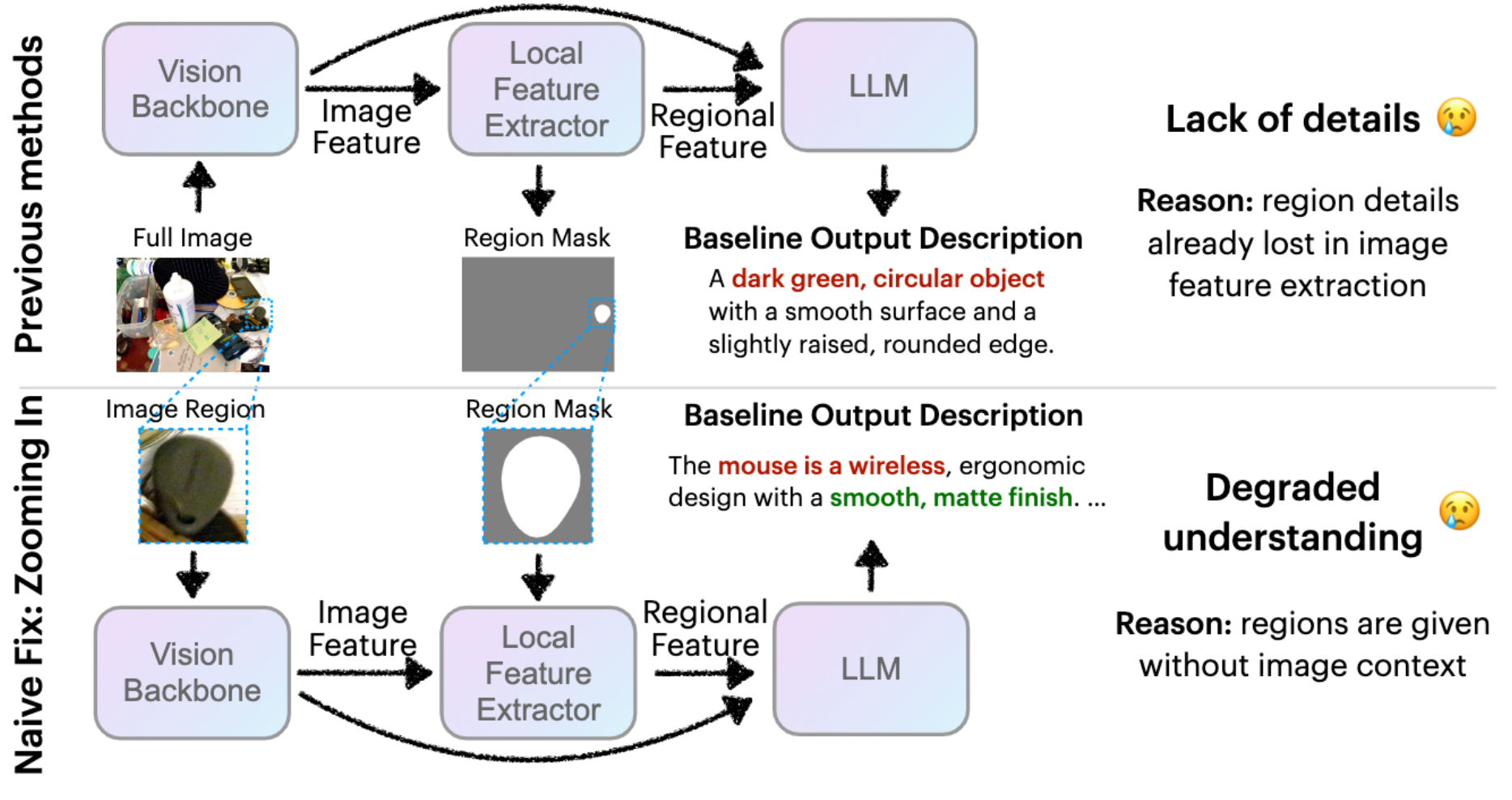
对于类似的需要对某个区域进行描述的模型,最重要的就是如何告诉模型区域信息。现有方法如上所示:
- 传统方法提特征,然后用类似RoI的方式提取局部特征,送进LLM。但是这样在提特征的时候就会丢失小区域的细节信息。
- 简单的改进方法就是把目标区域crop出来,然后提特征,但是这样丢失了空间的context信息
因此,DAM模型提出了一种新方法,从全图中提取整体信息,从局部中使用高token密度提取详细信息。
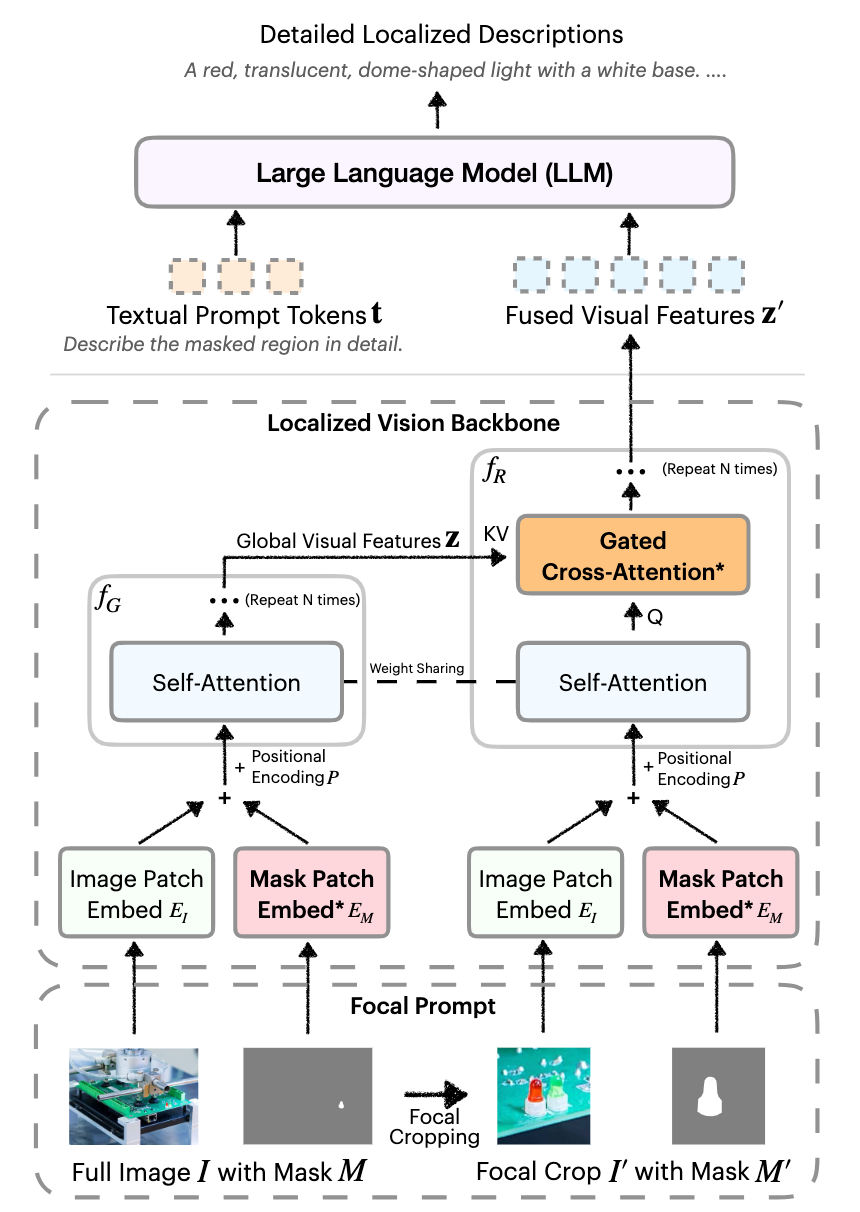
如上图所示,DAM包含了两个重要模块,一个是Focal Prompt,另一个是Localized Vision Backbone。
Focal Prompt
首先是必需的图像和对应的Mask,为了提取高密度的局部特征,crop出局部的图像和对应mask,此时局部crop会稍微远一点,不会完全就是mask的bbox。
Localized Vision Backbone
这个backbone对局部图像进行编码,并融入全图信息。
首先,输入把图像和mask通过卷积分别进行编码然后相加,并加上位置编码。
随后,全图和局部走两条路编码,全图信息使用和原来一样的由Self-Attention组成的backbone,局部信息则加入了Gated Cross-Attention,以全图编码完毕的信息作为K/V。
注意,局部这一路每个block都有一个SA和CA,并不是先SA再CA。
Gated CA很简单,就是普通CA后的特征乘上一个tanh激活的可学习参数,初始化为0来保证刚开始训练的稳定性:
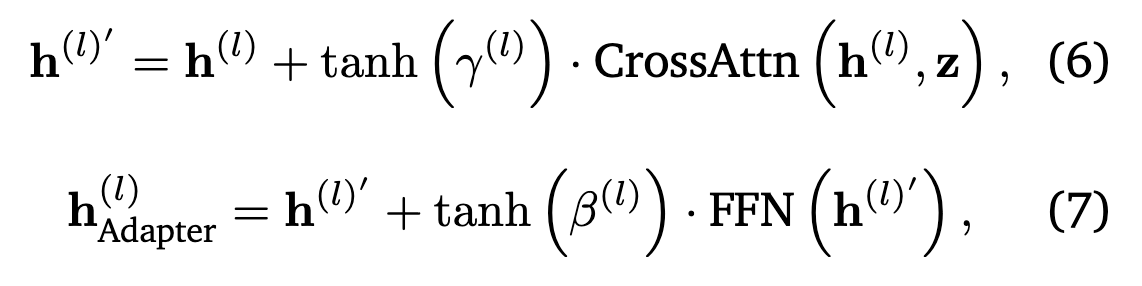
编码好之后,就常规送到LLM里去了。
因为SAM2可以给出视频每一帧的object mask,所以这个模型就很方便了。
数据:DLC-SDP
是一个半监督的数据引擎,分成两个阶段
Stage 1 利用现有标注
使用MLLM对现有的带有局部标注的数据进行扩充,比如一个视频有mask和目标名字,就让MLLM根据这个信息去详细描述。
Stage 2 利用无监督数据
- 使用图像分割模型从图像中提取Mask
- 用Stage 1训练的DAM来生成描述
- 使用CLIP来过滤低置信度数据
评测:DLC-Bench
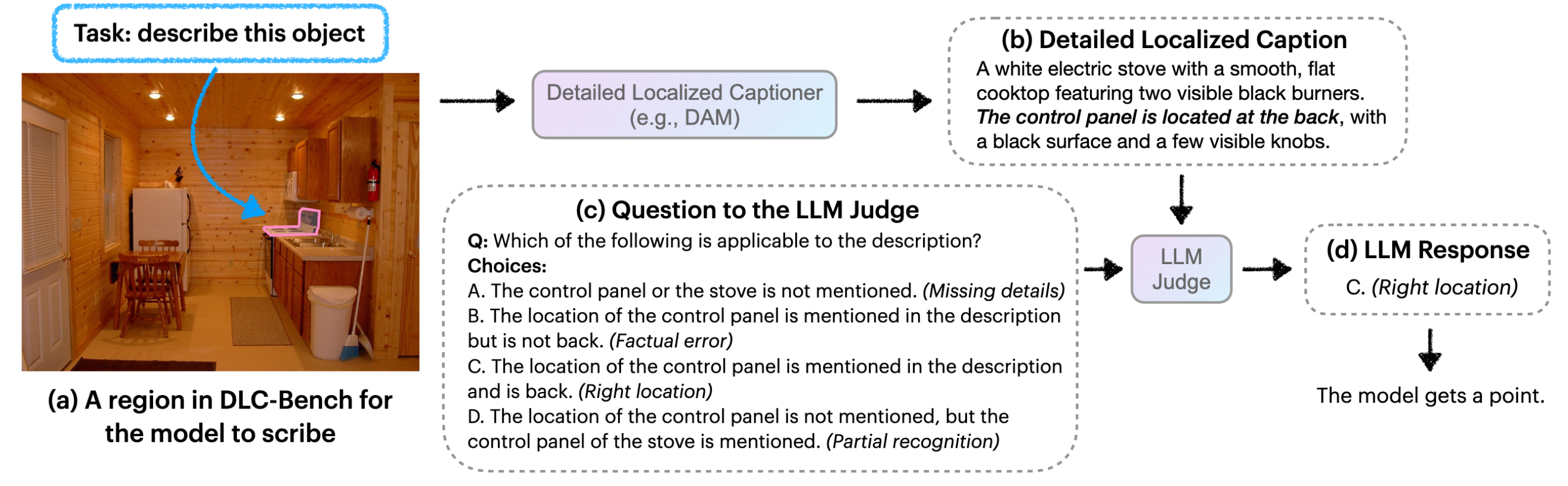
为了专门评价DLC方面的性能,作者构建了一种比较奇怪的Benchmark。
作者设计了一系列的positive和negative的问题,前者主要关注应该出现在描述中的特征;后者主要关注不应该出现的细节。如图所示,问题会对应ABCD四个答案,其中只有一个答案是对的,其他或多或少会有问题。
随后,使用一个LLM来做题(没错,题目是给LLM做的,不是给这篇文章的DAM模型做的),问他DAM输出的caption属于哪个选项,每个选项有-1、0、1三种分数。
最后,对所有题目进行平均得到最终分数。
DLC-Bench的图片数据来自Objects365-v2的验证集,总共有892个人工验证的题目,生成过程稍微使用了LLM。
实验
DAM模型在多个任务中进行了测试:
-
Keyword-level Localized Captioning
要求模型输出对应目标的关键词。其中LVIS是输出类别名,而PACO还要模型判断,假如包含了全部object则输出类别名,假如只包含部分则需要同时数据object的名称和部件的名称。
-
Phrase-level Localized Captioning
要求模型输出短语来描述目标和属性。使用传统的CIDEr、METEOR等指标评价。
-
Detailed Localized Captioning
在Objects365的一个Ref-L4子集上进行,在评价之前会通过GPT来缩句(不清楚这个怎么评测)。除此以外还用了文章提出的DLC-Bench
-
Detailed Localized Video Captioning
在HC-STVG(一个时空video grounding数据集)上评价,使用CIDEr等指标。在VideoRefer-Bench上评价,使用GPT给出1-5分的评价(在Subject Correspondence、Appearance Description、Temporal Description、Hallucination Detection四个维度上评分)。
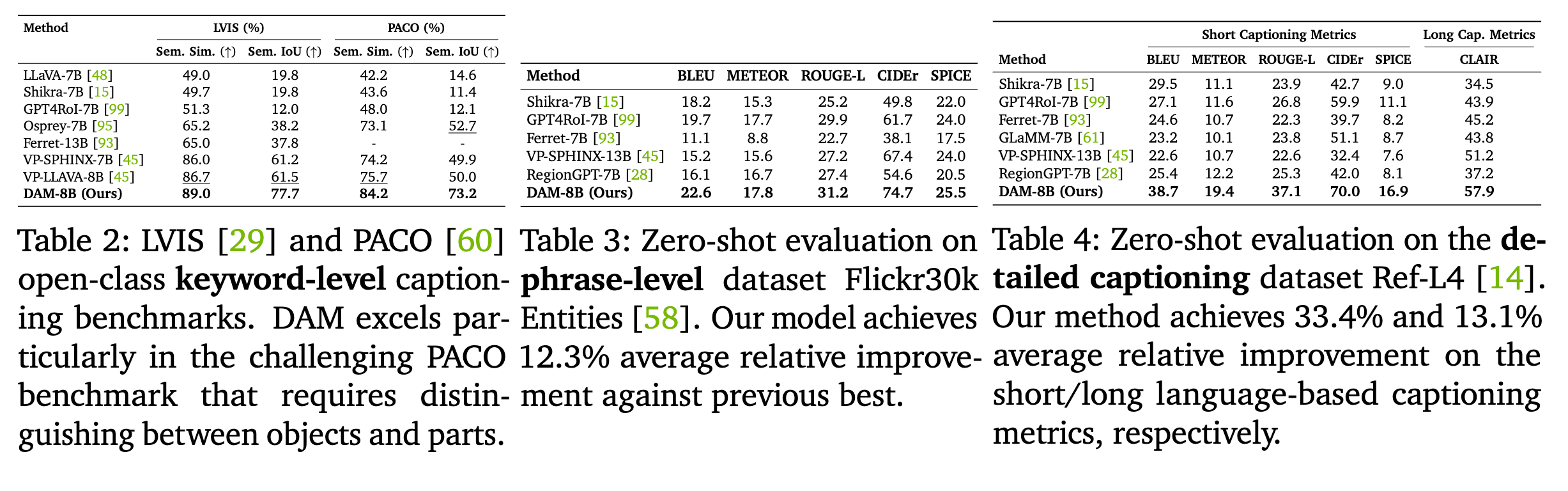
如图所示,在各个数据集上都很SOTA。

这是不同模型的定性比较,DAM模型描述的还是很精确的,但是有点体现不出来考虑了整体特征。
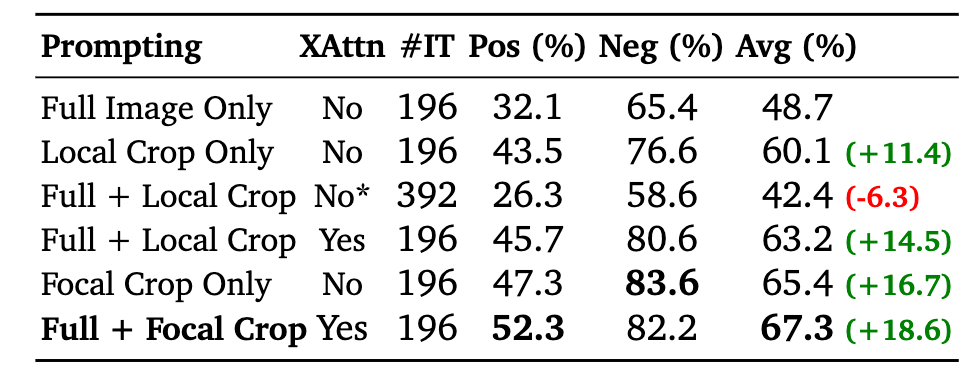
消融实验发现Local Crop很有必要,并且添加上Full的Context信息也很有帮助,文中的这种方法使用Focal Crop+Full的效果最好。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!