论文笔记 Generalized Video Moment Retrieval
本文最后更新于:2025年7月17日 下午
论文笔记 Generalized Video Moment Retrieval
论文链接:https://iclr.cc/virtual/2025/poster/28243
代码链接:暂未开源(但是给了个打不开的链接)
ICLR25的一篇Poster,提出了Generalized Video Moment Retrieval (GVMR)这个任务,也就是在一般VMR的基础上,允许no-target和multi-target。为了实现这个任务,构造了一个新的NExT-VMR数据集,提出了一个BCANet的新模型。
NExT-VMR数据集
作者使用了2014年的YFCC-100M作为数据源
YFCC-100M
Yahoo于2014年发布的多媒体数据集,收集了Flickr平台上CC版权(免费共享)的内容,原始数据100TB,以照片为主,有0.8M个视频,时间跨度为04年-14年。Flickr一般是摄影相关从业人员会去的网站,因此每个数据有详细的元信息(包括拍摄时间、地点、设备等),拍摄水准较高。
作者手动标注了YFCC-100M中视频的subject、predicate、object三元组信息以及对应的开始结束时间,然后将三元组转换为文本句子作为query。
对于no-target数据的生成,作者采用了以下三种方法:
- 对三元组中的元素随机替换成其他单词
- 将现有单词随机替换成语法稍微不正确的形式,增加复杂度
- 将其他视频的query拿过来
对于multi-target数据的生成,作者采用了以下两种方法:
- 通过LLM根据三元组生成one-target的句子的query
- 寻找视频中不同区间有交集的时间段,取它们的交集为新的样本,并连接它们的三元组
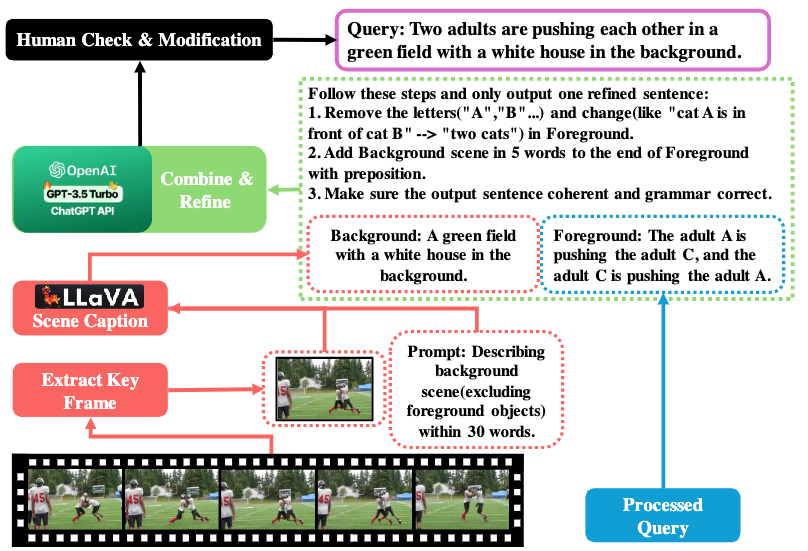
用三元组生成流畅句子的方法如上图所示:
- 通过
LLaVA-v1.5-7B-int8生成背景场景的描述 - 通过三元组简单合成前景句子,若有多个三元组,则通过and连接。
- 用
GPT-3.5 Turbo来合成得到最终query。
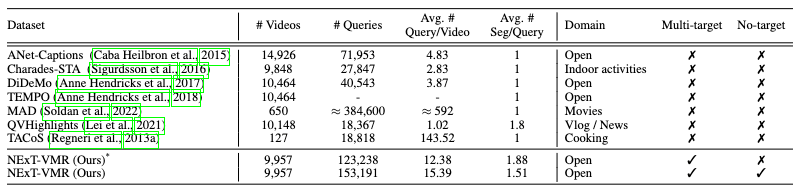
最终是获取了接近10K的视频,153K的query,每个视频高达12-15个query,每个query可能对应多个片段。
BCANet
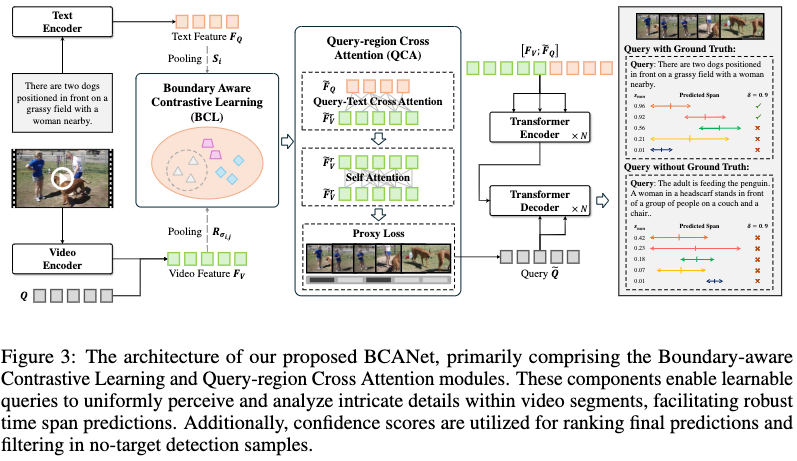
提出模型如上图所示,视频侧经典使用CLIP-ViT-B/32和SlowFast的特征,文本侧使用对应的CLIP文本编码器。使用类似MomentDETR的架构,视觉文本特征拼接在一起之后通过一个带有query的decoder来预测boundary。其中,query是通过Boundary-aware Cross Attention(BCA)生成的,BCA具体包括Boundary-aware Contrastive Learning (BCL)和Query-region Cross Attention (QCA)。
Boundary-aware Contrastive Learning (BCL)
比较常规又无聊的一个loss,对视觉特征,聚合对应片段中的特征作为正样本进行对比学习,对于no-target的样本,则聚合全局特征作为一个负样本。
Query-region Cross Attention (QCA)
query对视频作cross-attention,然后视觉侧自己做self-attention来增强视觉和文本的特征。
然后,设置一批learnable queries(L个),计算这些queries(这里是DETR中的那些queries,不是文本特征)对每一帧的相似度:
其中是GELU,表示query对每一帧的关注度(这里softmax不知道是从哪个维度归一化的,猜测是帧时序维度)。随后根据关注度聚合视觉特征得到对应的L个query()。
此处还使用了一个叫做proxy loss的东西进行监督,本质上是一个BCE loss,当query是有对应target的则为1,否则为0。
其它损失和以往其他方法一样。
推理过程不计算BCL和Proxy预测。
实验
使用传统的R1@IoU和mAP@IoU,另外为了评测no-target的精度,提出N-Accuracy和T-Accuracy,前者对于no-target的视频,计算其Acc;后者则对于有target的视频,计算Acc。
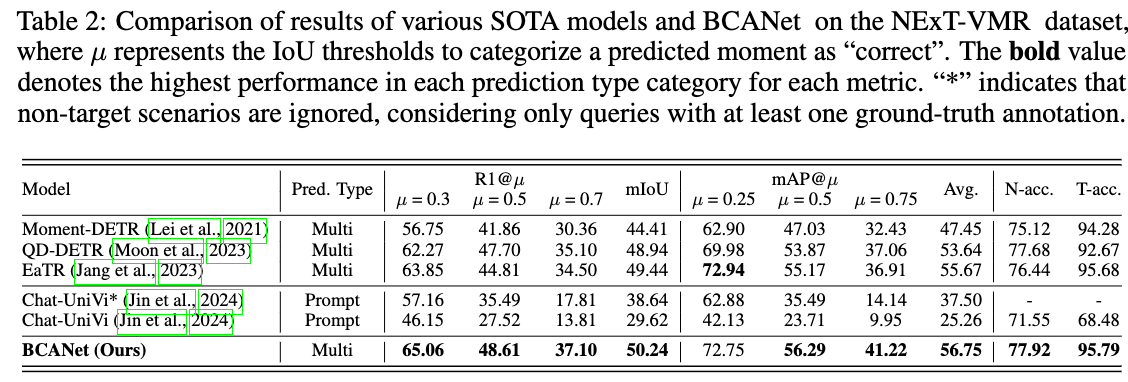
主要结果如上,和以往的貌似没有高多少。
结论
看标题很唬人,看贡献感觉有新任务、新数据集、新方法,很牛的样子,但是实际上写作和方法都差点意思:
- 为啥Related Works讨论了很多数据集,但是完全没有介绍相关方法?Table2中的方法完全没讨论。
- 是如何重新标注0.8M的数据的?没有细节,甚至后面又说这个三元组标注是来自YFCC的?
- 数据集部分的3.4.3说用LLM生成了scene graph,真的是graph吗?看例子不像啊,而且图2上写的又是scene caption。
- 方法部分的写作简直是灾难,图中压根就没有体现BCA是什么东西,定义不明确,编码前也叫这个,编码后也叫这个?具体的方法中公式符号也经常定义不清楚。
- BCL太简单了,感觉不够创新。QCA的proxy loss没看懂为什么取这个名字。
- 推理过程不清晰,文中说推理时不计算BCL损失和Proxy predictions,这不是废话,不是训练为什么要计算损失?
OpenReview上审稿人提出了很多问题,给的分也是boardline,最后还是中了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!