论文笔记 Holmes-VAU Towards Long-term Video Anomaly Understanding at Any Granularity
本文最后更新于:2025年5月17日 下午
论文笔记 Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
论文链接:https://arxiv.org/abs/2412.06171
项目主页:https://github.com/pipixin321/HolmesVAU
华中科技大学的一篇CVPR 25 Highlight,重点在于视频异常理解,提出了一个基于XD+UCF的Instruct数据集HIVAU-70k,并提出了一个VAD模型+MLLM的级联模型,开源代码较易使用。
研究动机
文章在于理解不同temporal scale的异常,作者认为有的异常是immediate的,但是有的异常就需要extended contextual reasoning。因此,他们利用一个半自动的数据引擎构建了HIVAU-70K,包含clip-level、event-level和video-level的视频-文本对。为了处理long-term,他们没有采用均匀采样,而是在前面使用了一个VAD模型(文中称为Anomaly-focused Temporal Sampler,ATS),并根据预测分数进行density-aware的采样。
在我看来,VAD是否真的需要long-term尚且存疑,Intro中举的例子:短异常例如爆炸和打架,长异常例如偷窃和纵火,这个在我眼里还是不够直观,为什么纵火算长异常呢?火烧起来了不就可以说是异常了吗?
方法:HIVAU-70K
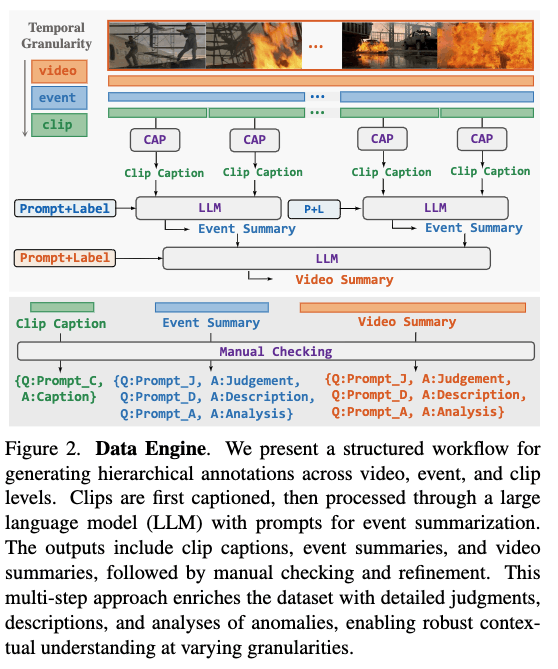
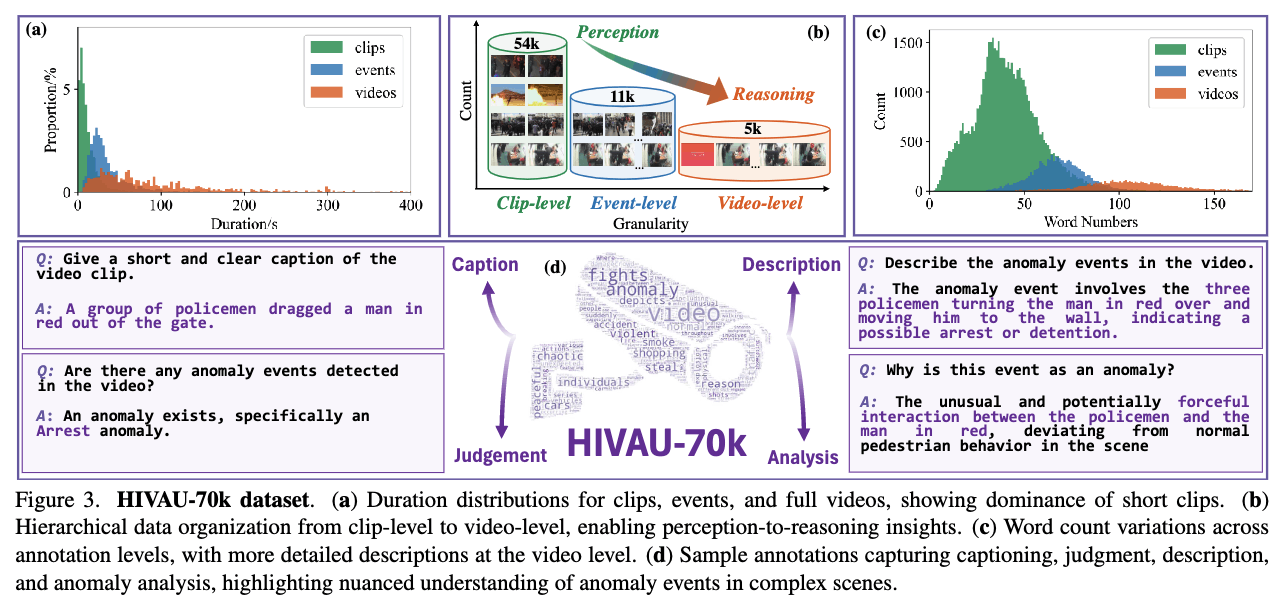
这张图比较好地概括了数据构建的流程,要注意的是,数据源是UCF-Crime和XD-Violence的视频,他们将训练集中的异常事件进行了标注。最后得到了5443个视频、11076个event、55806个clips。
clip的文本是描述,event和video的文本则是判断+描述+因果分析。
方法:Holmes-VAU模型
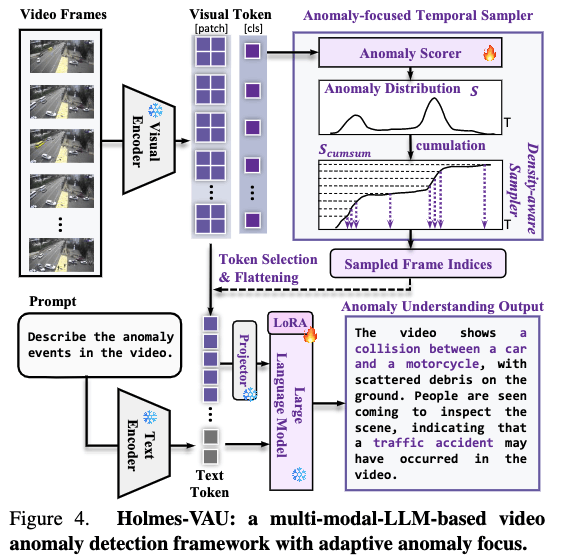
如图所示,帧级别的特征送入Anomaly Scorer,这就是一个普通的VAD模型,而patch级别的特征则送入MLLM。
得到的分数会累加构成一个probability mass function,然后在纵轴上均匀采样,再找到对应的采样帧。
这个方法简单直观又聪明。
训练时,两者完全分开训,Anomaly Scorer使用监督信号做BCE来训,后面的MLLM则用描述文本来训。MLLM使用了LoRA。
实验
实验分为检测性能和推理性能的评估,前者用AUC/AP,后者用BLEU、CIDEr、METEOR、ROUGE这些传统指标。
MLLM的参数使用InternVL2-2B初始化,用两个A100训练。
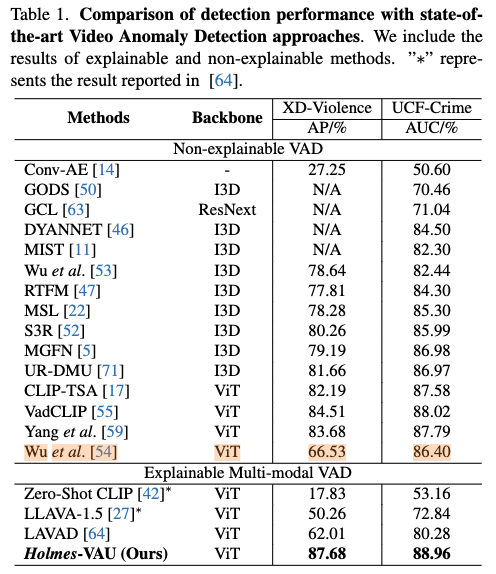
上图是检测性能的比较,说是为了公平,数值是用对应训练集而非混合训练集得到的,实际上,我感觉即使混合了性能也不会提高,反而会降低。此外,这里和[54]的比较不公平,因为人家训练集有open-vocabulary的限制。并且,这篇论文用的监督学习,和其他都不是监督学习的根本比不出来什么东西。这里和Explainable Multi-modal VAD放在一块也不太好,因为其他都是Zero-shot。而且,这里说是用Holmes-VAU,但是实质上和MLLM没有关系。
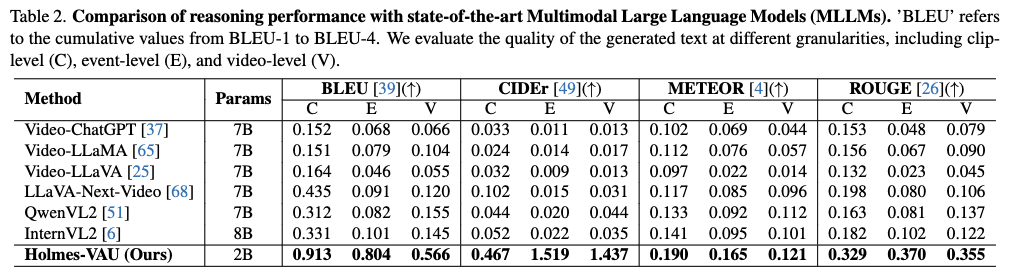
上图是reasoning的比较,大模型时代全用传统指标我感觉是不够solid的,用微调的和一堆zero-shot的general-purpose的比也不太公平。此外,这个比较我不太清楚是用GT片段送进MLLM还是直接整个视频给MLLM的,假如是后者,那么也不是很公平。
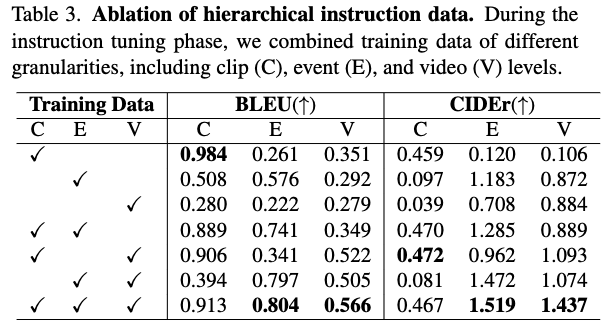
上图是数据的消融,能做这个实验还是挺不容易的,貌似E的数据加进来提升最多。不过我感觉这个实验应该分别考量jedgement、description和analysis,而非这种temporal的粒度。
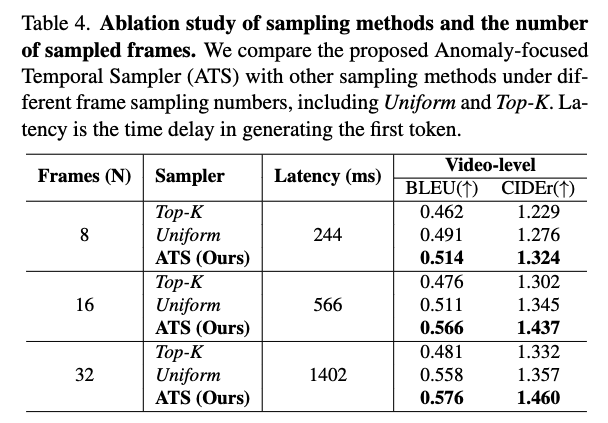
采样方式的消融,没什么好说的,感觉很棒。
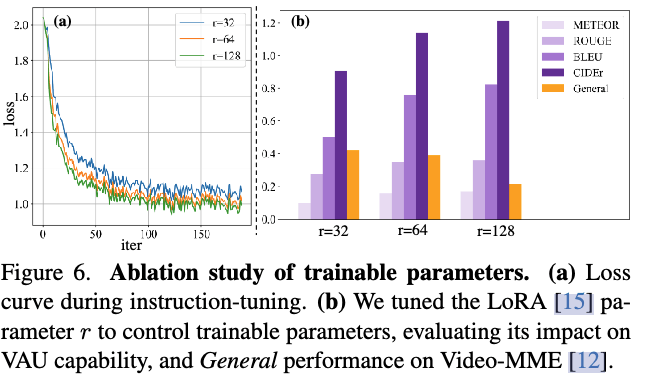
这个比较了LoRA的setting,参数越多,general的能力会下降,能在Video-MME上做使实验更扎实了。
可视化就不放了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!