视频异常检测领域中关于时序定位相关指标分析
本文最后更新于:2025年3月20日 下午
视频异常检测领域中关于时序定位相关指标分析
本文对视频异常检测(Video Anomaly Detection,VAD)中关于定位异常发生时间段任务的相关评价指标进行分析。
VAD任务旨在定位视频中与预期不符的部分,实际上基本就是为视频每一帧打异常分数(二分类),部分工作还涉及给出帧级别的细粒度多分类分数(也在本文讨论范围内,但不是主要部分),还有的工作涉及到空间(这部分本文完全不讨论)。
本文会介绍相关指标的计算、对其概念进行解释、指出容易犯的误区,并给出自己的思考。
混淆矩阵
深度学习入门时相比都了解了混淆矩阵,这里放出来以防忘记
| 预测结果 | ||
|---|---|---|
| 真实情况 | 正例 | 负例 |
| 正例 | TP | FN |
| 负例 | FP | TN |
AUC
AUC本意是Area Under Curve,即曲线下面积,而VAD领域一般特制ROC曲线下面积,其它的称呼有“AUROC”或“AUC-ROC”。
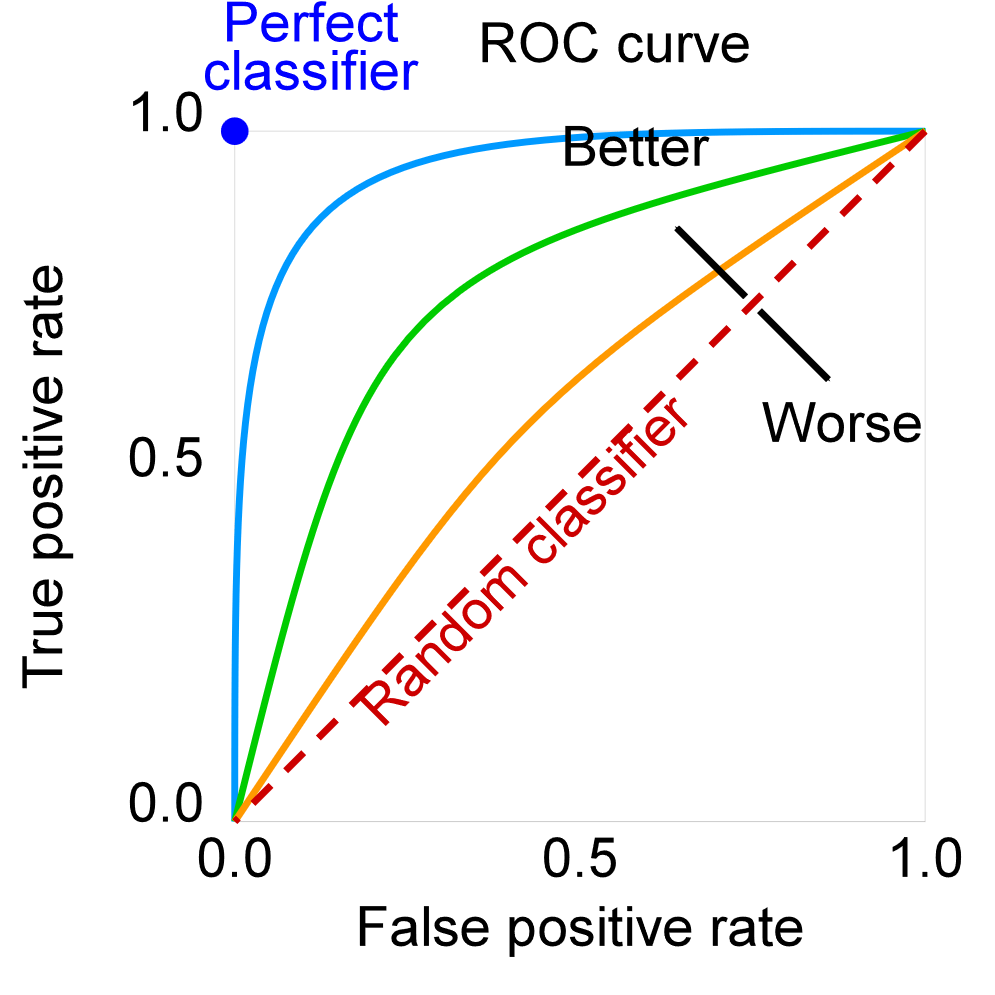
如下图所示,ROC曲线是以FPR为横轴、TPR为纵轴、通过改变阈值而绘制的曲线:
TPR是真实情况是正例中,模型判断正确的比例,也叫做召回率(recall);FPR是真实情况为负例中,模型判断错误的比例,也就是误报警的比例。我们期望的模型则是召回率高但误报率低。现实中,这两个指标都是随着模型判定阈值而正相关,阈值越低、召回率越高、误报概率越大。
ROC曲线一定会经过左下角的点和右上角的点,越往左上角凸则表示模型性能越好,一个随机预测的模型对应的线段,一个最佳模型对应的曲线。
因此,曲线下的面积可以作为单个值来衡量模型性能,比随机分类器更好的模型的AUC应该大于0.5。(假如你的分类器AUC小于0.5,那应该考虑把正负类反转一下,用1减去分类器输出的预测概率)
直观来说,AUC还表示“模型对正例的预测分数大于对负例的预测分数的概率”,这是AUC与其他指标相比的一个最直观的解释。同时也说明AUC是一个基于排名的指标。
通用情况下AUC的不足
AUC起源于二战,与经济学常用的基尼系数有直接的联系,并且医学、工业等领域广泛应用这个指标,但是也有对这个指标的批评。
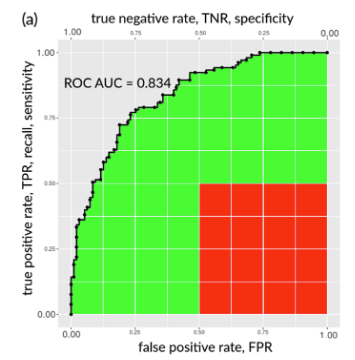
根据[2]所述,AUC可以被认为是对同一个模型在不同情况下的性能总结。在现实中,有的人可能更注重误警率,有人则更注重召回率,他们可以通过改变阈值来调整。然而,某些情况人们几乎不需要,比如极高的阈值和极低的阈值,人们不关心这些情况下的模型性能,但是此时的性能仍然贡献了AUC值。[1]中给出了下图,对于一个看上去比较好的AUC=0.834的模型,贡献这个值的是曲线下的所有面积(绿+红),然而,红色部分面积对应的点是表现很差的模型(误报率高但是召回率低),这部分面积占了0.25。
其实这部分不是很明白,假如觉得红色的0.25不重要,那就把AUC减去0.25然后再重新归一化就好了?
除此以外,[1]还认为ROC曲线和AUC并没有提供关于precision和NPV的信息(),一个高AUC的模型可能有低P和低NPV。
在VAD领域中AUC的不足
[1,2]都是医学统计学方面的文献,都是在争辩AUC对于常规的二分类任务到底好不好。然而在VAD领域中,实际上并不是一个单纯的二分类任务,VAD的测试集包含多个视频,每个视频包含许多帧,这包含一种层级的关系,而目前的AUC完全忽略这种层级。
这会导致AUC与人类所希望的方向不是同一个方向,比如Temporal Action Localization任务中会使用mAP@IoU来评价,只要预测的时间段与GT时间段的IoU大于一个阈值,就算作预测正确。这种比较符合人类的直观,我不希望你预测的内容和GT一模一样,只要看着差不多就行。这种思想在图像的质量评价上也有体现,比如超分领域衡量两张图像不像,一开始是用MSE,但是和人眼的相似不一样,所以后面出现SSIM、LPIPS等指标。
在VAD领域,由于GT本身可能存在偏差,或者人们更关注“是否在异常事件早期检测出异常”,我们想要的好模型和AUC衡量出来的好模型不一定是一回事。博主近期就在研究这方面,若有论文产出会及时更新到此处。
此外,和接下来要介绍的AP指标一样,他们无法评价单个视频的判断成功性。对于一个异常视频(包含正例和负例),还是可以计算AUC指标的,但是对于一个正常视频(全都是负例),无法计算AUC。假如我们想评价模型在几个正常视频上预测地好不好,就无法用AUC来评价。不过,这个问题实际上也不算是一个大问题。
AUC的误区:Micro-AUC和Macro-AUC
发表在TPAMI上的[3]指出VAD中有micro和macro的AUC的区分,[4,5]这两篇发表在CVPR的论文也跟随它汇报了两种AUC,但是这两个指标衡量的并非同一个东西!
[3]认为,micro-AUC是把所有预测分数拼接在一起,把所有GT也拼接在一起,然后计算两者之间最小单位为帧的AUC,这是常规且直观的做法。而macro-AUC则是先计算每个视频的预测分数与GT的AUC,然后对所有视频进行平均,这看上去也没毛病,而且符合micro-macro的思想,然而,正如我前一节所说,我们无法计算正常视频的AUC,这个指标从原理上是不可行的。
既然它们都在论文里汇报了指标,那么实际上是怎么计算的呢?[3]没有公开代码,[4]在代码里计算macro-AUC的时候会人工添加一个TP和一个TN [6]:
1 | |
[5]在代码里则是忽略了正常视频:
1 | |
单看这两个代码的实现,得到的就不是同一个指标,[4]修改了预测结果来避免NaN,[5]则是忽略了一部分的数据。
此事在Issue中亦有讨论:https://github.com/lilygeorgescu/UBnormal/issues/3#issuecomment-1258619983
综上所述,目前Macro-AUC并不是一个规范的、有明确意义的指标,不应该被用来评估模型性能。
Ano-AUC /
[8]中的Ano-AUC和[9]中的是同一个东西,只对异常视频进行计算AUC,单独用来衡量模型对异常的定位能力。这个指标比较像micro版本的[5]的macro-AUC实现。
这个指标没什么好说的,只对异常视频计算,本质上只衡量了模型一方面的性能。
AP
AP是Average Precision,是Precision-Recall曲线下的面积,所以也可以叫做“AUC-PR”或“AUPRC”(不过一般没人这么叫)。
如下图,PR曲线不像ROC曲线那样单调、平滑,PR不一定过端点,在局部也可能出现上下波动。AP旨在衡量模型对正例的识别程度,它使用两个负相关的统计量作为两个轴,阈值越高、精确率一般会更高、召回率会更低。随机分类器的AP值取决于正样本的比例,完美的分类器的AP为1。
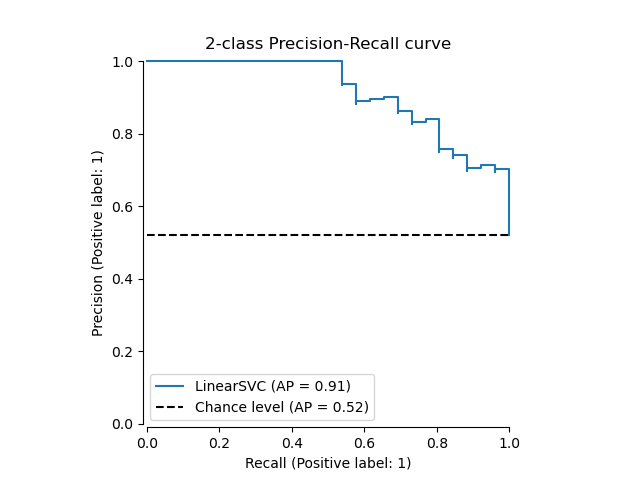
在VAD领域,XD-Violence数据集[10]上最先使用AP指标,其它数据集(ShanghaiTech、UCF-Crime、UBNormal、MSAD)都以AUC为默认指标。
AP与AUC的比较
[10]中说AP在面临类别不均衡情况下更有优势,会更关注正例。根据[11]中对AUC和AP指标的分析,AP受到不均衡数据集的影响,而AUC不受影响。这种性质可能带来正反两面的影响,假如我想检测的两个类别的重要性是相当的,比如猫狗分类,那可能AUC更适合,而在VAD中,异常数据是稀有的(数据集中异常帧相较于正常帧少很多,实际情况中这种差距则更剧烈),我们也是更关注异常类别的,所以此时AP应该更适合。
不过,这个可能智者见智,仁者见仁,至少没有macro-AUC的歧义性,目前的规范就是跟着数据集官方给出的评价标准来。
更新
AP在计算方式上相较于AUC有一个严重的误区,可能造成评价结果变化几个百分点,直接让SOTA不再SOTA。
对于PR曲线和ROC曲线,由于点是离散的,曲线下的面积计算都要近似为矩形或者梯形的面积计算。对于ROC,由于其一定是单调的,所以可以进行插值来计算近似面积。然而,根据[14,15,16]的分析,进行插值会导致过于乐观的AP结果,所以在sklearn中,直接使用
sklearn.metrics.average_precision_score来计算AP时是不插值的,即计算矩形的面积。然而,假如选择先使用sklearn.metrics.precision_recall_curve得到PR曲线,再使用sklearn.metrics.auc计算曲线下面积,则计算的是梯形的面积,这样会得到更高的AP值。此外,在torchmetrics的AP实现中是和sklearn一样默认使用矩形面积的。综上所述,应该直接使用
sklearn.metrics.average_precision_score来计算AP,比较不同模型结果时最好严谨地看看是怎么计算的。
mAP@IoU
AUC、AP都是将VAD的任务看做平面化的给每一帧进行二分类的任务,没有考虑到异常的事件性。在[8]中作者使用了Temporal Action Localization中惯用的mAP@IoU指标到fine-grained VAD上来。fine-grained VAD要求为每一帧给出正常和不同异常类别的概率。
对于预测和GT,假如IoU大于一个阈值就算TP,对于没有对应GT的预测就是FP,对于没有预测的GT就算FN,根据这三个值计算AP。每个类别单独结算,然后在所有类别中做平均。通常论文会给出不同IoU阈值下的指标,有的还会给出平均几个IoU阈值下的综合指标(比如AVG 0.1-0.5)。
需要注意的是:
- VadCLIP只在异常视频上计算这个指标
- 该指标需要确定阈值(VadCLIP中使用了动态阈值),不像AUC和AP是与阈值无关的指标。
- 在VadCLIP的实现上,计算IoU是通过帧级别的交并比,而TAL任务一般则是基于片段的交并比。
模型预测的帧级别分数在卡了阈值之后会变成多个独立的片段,VadCLIP的实现上把这个作为一个pred。假如拓展到正常视频,只要有一帧超过了阈值那就会被认为是一个FP。
TBDC
[12] 中提出Track-Based Detection Criterion(TBDC)作为评价指标,同样使用了IoU的方法考虑了标注噪声带来的影响。TBDC是类似ROC的曲线,以false positive regions per frame(FPR)为横轴,Track-Based Detection Rate(TBDR)为纵轴。
一个TP的track表示至少有的TP region被检测到了,而一个TP region表示这一帧中预测与GT的IoU超过,而TBDR是检测到的track数除以总GT track数,相当于一种召回率。
一个FP的region表示预测与任何GT的IoU都小于,则FPR是FP region数量除以总帧数,这个值可以大于1,相当于一种误警率。
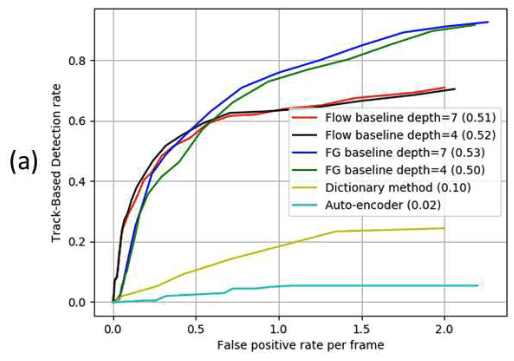
这个指标参考了ROC的不同阈值的概念,同时也利用了IoU的鲁棒性,然而这个指标是同时考虑时空信息的,并不是直接对时序进行评估。其次,论文没有分析这个指标的取值范围,横坐标没有归一化,感觉不太适合用来比较。
APD
[13] 提出了Average Precision Delay(APD)作为评价指标,参考AP指标并纳入了“惩罚晚期检测”的思想。APD的两个轴分别是Average Detection Delay(ADD)和Alarm Precision(P),分别对应AP中的recall和precision。
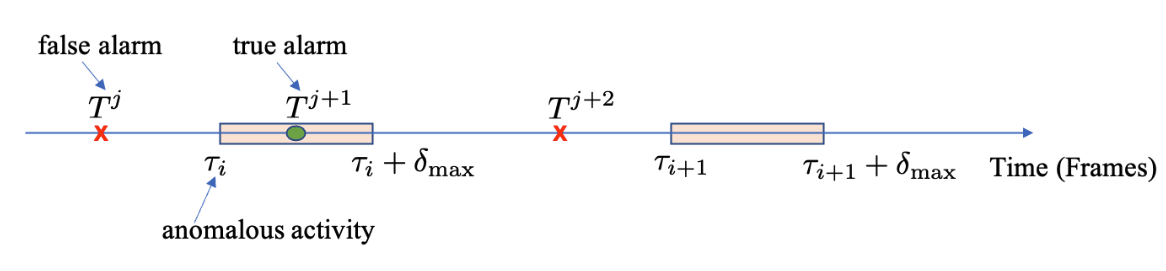
如上式和上图所示,ADD衡量检测延时,对于GT异常事件,找到其中最早发生的异常点,计算与开头的距离。[13]中对异常事件是以点的形式标注的,所以会预定义一个的窗口,在窗口内发生的异常根据延迟程度会给一个0-1的分数,假如窗口内没有预测出的异常,则分数直接为0。P衡量误警,对于所有的预测异常点,假如发生在异常窗口内则为为TP,假如同一个窗口内有多个预测异常点,则只考虑第一个。
改变阈值,两者曲线下面积就是APD。
这个指标看上去挺合理的,但是:
- 使用固定的时间窗口不合理,不同异常事件的持续时间不同,假如窗口过大,异常事件结束后的正预测也会被当作是TP。
- 只考虑首个点可能会收到噪声影响。
总结
目前在VAD的时序定位评价指标上,AUC占据主导地位,AP是一个强有力的挑战者,可以在一定程度上取代AUC,但是这两个指标都没有考虑异常的事件性,尝试考虑的几个指标都有各自致命的缺陷。
参考文献
[1] The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification
[2] AUC: a misleading measure of the performance of predictive distribution models
[3] A Background-Agnostic Framework with Adversarial Training for Abnormal Event Detection in Video
[4] UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection
[5] Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
[7] https://github.com/ristea/aed-mae/blob/84d718d244b772fd58acd1d32c136d34432ee16b/inference.py#L84
[8] VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
[9] Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection
[10] Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision
[12] Street Scene: A new dataset and evaluation protocol for video anomaly detection
[13] Rethinking Video Anomaly Detection - A Continual Learning Approach
[14] J. Davis, M. Goadrich, The Relationship Between Precision-Recall and ROC Curves, ICML 2006.
[15] P.A. Flach, M. Kull, Precision-Recall-Gain Curves: PR Analysis Done Right, NIPS 2015.
[16] https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-and-f-measures
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!