论文笔记 Advancing Video Anomaly Detection A Concise Review and a New Dataset
本文最后更新于:2024年12月3日 下午
Advancing Video Anomaly Detection: A Concise Review and a New Dataset
论文链接:https://arxiv.org/abs/2402.04857
代码链接:Github
NeurIPS 2024的一篇论文,是Track on Datasets and Benchmarks上的,提出了一个新的多场景的异常检测数据集MSAD。MSAD包含了14个监控视角场景,包含与人相关和与人无关的类别,支持弱监督学习和自监督学习。
文章给出了一个简单的综述,后面介绍了数据集的构成,最后跑了baseline。
异常检测综述
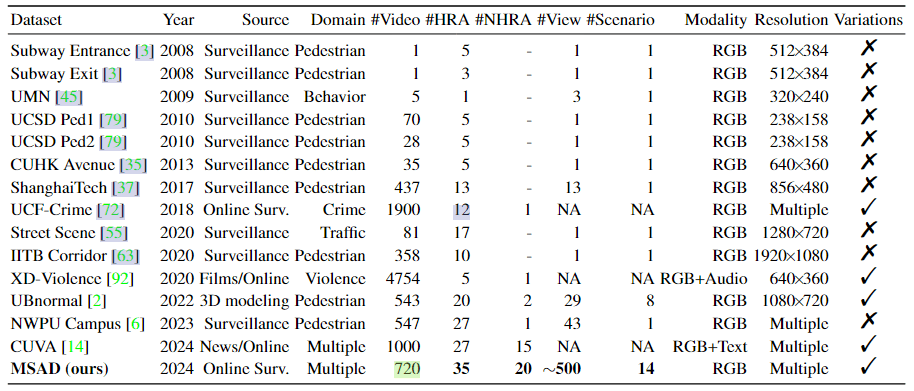
作者认为,异常视频检测(Video Anomaly Detection,VAD)领域早期的数据集较简单,比如Subway、UMN、UCSD Ped、CUHK Avenue这些只有较少的低质量视频、并且视角是固定的几个。ShanghaiTech数据集则有更多的视角,并设计了未见的异常类别。这些数据集的方法基本是传统方法,深度学习时代主要用的数据集是UCF-Crime和XD-Violence。
作者还提到了few-shot学习的几个文献,比如Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks使用了元学习的方式,预训练后,在新视角下稍微微调一下就有好性能。(作者在这里给了6篇文献)
对于VAD领域,作者认为自监督和弱监督是主流,因为这个领域数据比较稀缺。
- 自监督的方法是说模型只在正常数据上训练,然后将偏离正常的数据点标记为异常。这类方法有基于reconstruction的、基于prediction的、基于distance的。但是问题是很难学习到所有正常的模式,并且相同的异常可能在不同场景下有不同的判断结果。
- 弱监督的方法避免了frame-level和pixel-level的标注,使用video-level的标注。这种方法常用预训练模型提取特征,比如TSN、C3D、I3D、Swin(有很多用swin的吗?)。
作者特别提到了human-related的VAD,这类方法还利用光流、运动信息或者pose信息来判别。最近还有用LLM来辅助VAD的,并且有一个叫CUVA的多模态VAD数据集被提出。(这个CUVA是CVPR的那篇Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly提出的)
除此以外,多模态在VAD中也比较热门,作者列举了光流、骨骼以及文本(利用CLIP)的一些方法。
作者主要讨论了以下问题:
- Context-awareness:有的异常是需要关注上下文才能判断的,比如NWPU数据集(西北工业大学的那个)。这篇文章提出的MSAD数据集包含更复杂的场景。
- Generalizability:目前数据集限制在少量的异常类别,导致泛化性较差,导致应用新的异常类别就要重新训练。虽然目前有synthetic的数据,但是真实数据更好。
- Adaptability and Reliability:白天和夜间的异常不同、工作日和周末的异常不同,需要一个自适应的算法。这篇文章虽然没有提出这种算法,但是说他们的数据集包含更长的视频,可以让模型学到这种信息。
- Interpretability and privacy concerns:一般做新数据集要提到privacy。然后可解释性也是老生常谈。没什么新鲜的。
MSAD
MSAD:Multi-Scenario Anomaly Detection。
如下图所示,MSAD包含14种场景,720个视频,11种粗类别,35种人相关异常和20种人无关异常,平均20.7s。
注意这里的场景和Shanghai Tech中的“scene”不一样,后者其实是校园里的摄像机视角,而前者是比如门口、高速公路、商场这种场景。
MSAD中人相关异常指的是车祸、打架这种,人无关异常指的是物体坠落、漏水这种。
MSAD的720视频包含240个异常视频和480个正常视频,其中有240个异常视频有帧级别标注。作者提供了两个评估protocol:
- 360正常视频训练,240异常+120正常视频测试(自监督)
- 360正常+120异常视频训练,120异常+120正常视频测试(弱监督)
官方使用帧级别AUC和FPR作为指标。
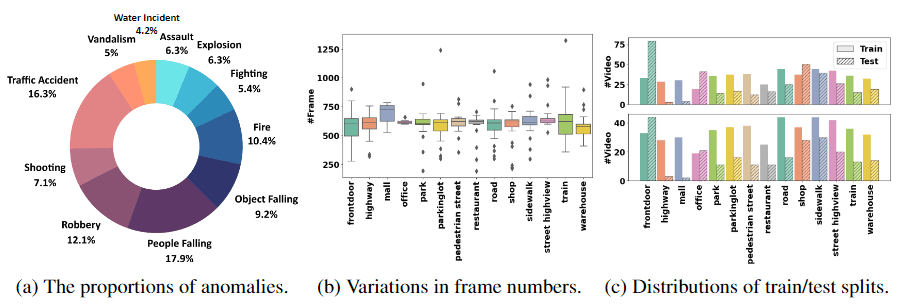
给的注释只有11种类别,论文table5给了更细的,但是下载下来的标注中是没有细粒度类别标注的!


MSAD收集视频分辨率较高,720p和1080p占主流。

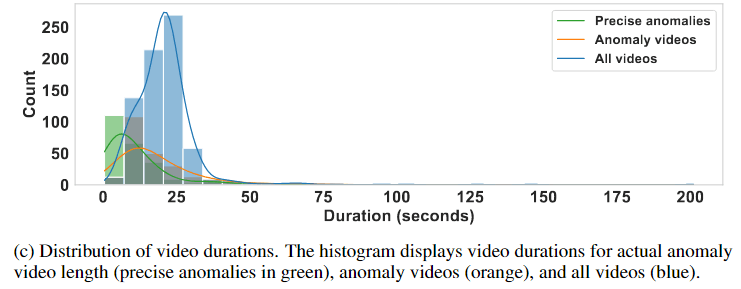
视频时长平均20s,但是单独拿出异常视频则大概在13s左右,其中异常片段的平均时长在7s左右。
数据收集
MSAD数据来源于YouTube、B站和Itemfix,没有具体说收集、标注的过程。收集的数据排除了低分辨率、灰度视频、非监控视角的视频、文本太多的视频、涉及政治隐私过度暴力的视频。
Itemfix是Liveleak的延续,当年UCF-Crime就是Liveleak上爬的数据,打开网站一股十年前的味道,但是貌似高质量的事故视频还挺多。
协议:非商业、要从中构建新数据集必须研究小组同意、仅能在学术时展示。
实验
实验设计分为两部分,一部分是Generalizability and adaptability,另一部分是Practical applicability and effectiveness。前者使用自监督的protocol评估,后者使用弱监督的protocol评估。
Generalizability and adaptability
作者提出了一种scenario-adaptive model ,结合了一种few-shot的FSAD模型。他们将模型在ShanghaiTech和MSAD上训练。对比实验分为相同场景不同视角和不同场景两部分,前者在同一个场景下训练和测试,后者在一个场景训练然后再另一个场景测试。

如上图所示,Table2展示了第一种对比实验,训练集用ShanghaiTech或者MSAD,然后用了别人的FSAD模型和他们提出的新模型。同样FSAD的话,除了v6,大部分指标都明显提升,然后SAD又在此基础上有一定的提升。v6指标低是因为,v6将自行车和开车到道路上当作异常,而这个一般不被当作异常。
Table3则是第二种对比试验,这个作者解释是MSAD训练比ShT训练在UCSD Ped2上能得到显著更好的结果,比如57.37->70.35,但是实际上不同数据集用的是不同模型,这个比较不是很公平呀。
Practical applicability and effectiveness
作者复现了一系列模型:MIST、RTFM、MSL、UR-DMU、MGFN、TEVAD,用了C3D、I3D(10-crop)、Swin三种特征。

如上图所示,就是跑了一遍,没有什么信息量。不解的是为什么MIST和MSL两个方法没在MSAD上跑呢?并且这个实验的意义大部分在于report results,而不是证明MSAD的优越性。
附录中有更多的实验:


Table7、8是细分类别与场景的定量指标,训练集是UCF或者MSAD,测试集是MSAD。每一个在UCF那一栏中标黑了的数字,都代表某个方法用UCF跨数据集验证居然性能更好。然而,在Overall中,AUC和AP都是更好的。作者说“证明目前数据集不能足够好地关注与人不相关的异常,而MSAD促进了这方面”。

Table9展示了zero-shot跨库性能,在ShT上普遍下降,在CUHK和Ped2上有上升。作者认为是ShT数据集的锅。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!