当我们在谈论模型部署时,我们在谈论什么。
本文最后更新于:2024年11月4日 晚上
当我们在谈论模型部署时,我们在谈论什么。
工业界应用神经网络时,往往要对学术界产出的模型进行优化,才能在推理设备/服务器上实现更高的效率,从而降低成本,这整个过程也一般称之为模型部署(Deployment)。那么,当我们在谈论模型部署时,我们究竟要经历哪些步骤?怎么去做优化提速?
本文对这个过程进行大致的简略分析。
为什么要部署
模型部署目标有多种,云部署提供了可扩展性和易访问性;边缘部署通过使模型更接近数据源来减少延迟;本地部署则确保了隐私和控制。
云部署非常适合需要快速扩展和处理大量数据的应用程序。 一些平台可以轻松管理从训练到部署的模型,不过,使用云计算的成本可能会很高,尤其是在数据用量大的情况下,如果用户远离数据中心,还会面临延迟问题。
边缘部署非常适合需要实时响应和低延迟的应用,尤其是在互联网接入有限或没有互联网接入的地方。 在智能手机或物联网小工具等边缘设备上部署模型可确保快速处理并保持本地数据,从而提高隐私性。 然而,边缘设备的处理能力往往有限,因此您需要优化模型。
本地部署适用于当数据隐私至关重要或互联网访问不可靠或无法访问时。 在本地服务器或台式机上运行模型可完全控制并保证数据安全。
神经网络是如何计算的
神经网络一般可以表示为如下图所示的由算子组成的有向无环图,算子表示一个独立的计算过程,输入的数据就在这个图上进行传播,直到输出。

一个算子数学上是函数空间到函数空间的映射,实际上就是(大型)矩阵的加法、乘法等计算。比如卷积操作就需要卷积核在特征图上不断地进行element-wise的乘法并求和,又比如ReLU这样的激活函数需要对输入的每个值计算激活值。
根据算子计算的方式,一般会分为计算密集型算子核访存密集型算子。像矩阵乘法、卷积这种算子就是计算密集型算子,单独拿出某个值,它需要不断计算与其它值的乘法和加法;而像激活函数这些算子就是访存密集型算子,每个值的计算比较简单,但是要从内存中拿出所有数据去进行这个计算。
神经网络中用到的矩阵计算基本都是大型的运算,计算两个1024x1024的矩阵相乘是常态,对这些矩阵进行计算会消耗大量能源和时间,模型部署时需要尽可能地减少这些的消耗。
神经网络部署技术架构
如下图所示,从上到下是从训练到部署运行要经历的三个阶段。
绿色的是模型训练阶段,一般用到PyTorch、TensorFlow、PaddlePaddle等框架,此时还是神经网络还是动态图,比较灵活,并且一般都是在高性能的服务器上进行。
橙色的是模型部署阶段,会把训练出的模型编译为对应的格式,将计算流程固定成一个确定的有向无环图,并且进行一定的优化以适应下游任务。此时就有非常多公司有对应的技术,比如Nvidia的TensorRT、开源的Onnx、Pytorch的TorchScript、Paddle的PaddleLite等。
蓝色的是模型运行阶段,一个程序最终还是要在硬件上运行的,这就有各家不同的硬件处理器实现了。不同的处理器的计算能力不同,消耗的功率也不同。在移动平台上的硬件会更注重功率,在大型服务器上的硬件则可能会兼顾算力和功率。

第二阶段有的时候也会细分为两部分,一部分更接近底层,直接作用于硬件,另一部分则更抽象,作用于计算图。

硬件层面提速神经网络计算
首先讨论神经网络在现代计算机(冯诺依曼架构)上是如何计算的。
graph LR
A[取指令] --> B[译码] --> C[访存] --> D[执行]
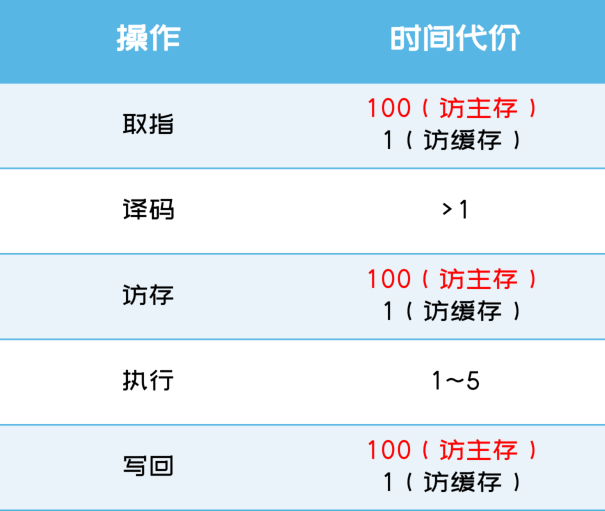
如上面这个流程图所示,处理器(CPU、GPU等)在执行指令时分为取指令、译码、访存、执行四步。
- 取指令是从内存中去取一系列表示指令的01串;
- 译码是理解指令,知道要执行哪个指令、要取哪些数据,这个过程可能会把指令拆解为多个微指令,一般CPU的指令会更复杂,而GPU则更简单;
- 访存就是根据指令来从内存/寄存器上取一些数据,CPU有多级缓存,如何更快地获取数据是一大难点,所以内存控制器也是CPU中占据大量面积的部件。计算机缓存一般是
寄存器>L1>L2>L3>主内存,越往后越慢,越前越贵,L1的访问延时可能只有0.5ns。 - 执行就是芯片让电流信号送入晶体管,然后在输出接收结果。比如送入物理上存在于某处的加法器电路等。
进行以上操作时,现代处理器一般都是流水线式的,上一个指令完成“取指令”后,就马上取下一个指令,而不是等当前指令执行完。这些操作的时间代价如下所示:
我们都听说过,神经网络在GPU(或者其它专门为AI推理设计的硬件)上运行会更快,这是为什么呢?
GPU与CPU的区别是:GPU有更多的“核”、更大的带宽,可以支持数据更快地存入寄存器,然后并行地处理多条指令,但是由于共享了相同的控制器,所以并行处理的指令必须是相同的。
这个特征和神经网络极为相似,因为上一节介绍的神经网络就是要进行非常大量的类似的运算。利用GPU更多核的并行计算可以快速得到结果,利用GPU的大带宽也可以快速访问数据。

GPU是随着电子游戏的发展而发展起来的,直到Hinton的AlexNet出现,人们才发现GPU能够加速神经网络的训练。然而,GPU中也有一些神经网络用不上的(光线追踪等)特殊器件,所以为了进一步降低神经网络推理的成本(速度和功率),国内外也有更专注于神经网络推理的硬件出现。比如TPU(Tensor Processing Unit)、NPU(Neural Processing Unit)等。
有的硬件可能会设置处理器专用的内存,有的则和CPU的RAM共用内存,有的硬件也会设置更多的int8的运算电路来运行量化后的模型,有的硬件还专门为transformer架构进行优化。
国内研发这类硬件的厂商比较多,有龙芯中科、寒武纪、莫尔线程、地平线等。
如下图所示,各种除了各种PU,还有公司会针对特殊的应用场景定制FPGA和ASIC。

软件层面提速神经网络计算
除了构建适合高速计算的硬件,软件层面如何去减少计算量、如何调度硬件进行计算也是十分重要的。将模型弄成硬件可执行的0/1代码的过程叫做编译,目前神经网络的编译框架如下图所示:
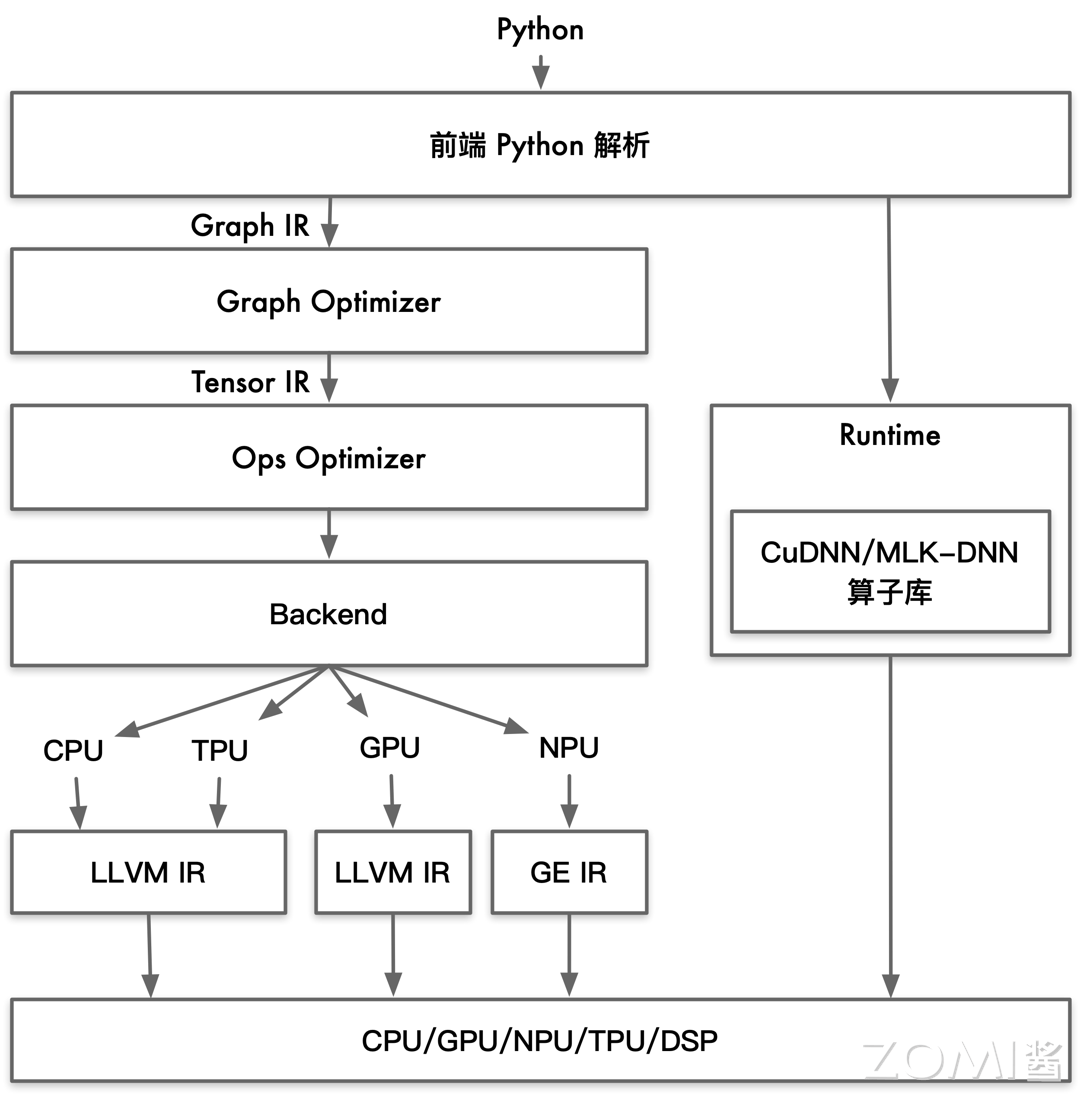
现有的神经网络一般都是用Python训练的,所以编译的第一步就是从深度学习框架中导出一个包含模型参数和运算方式的中间表示(IR)。
接下来,Graph Optimizer会对IR进行优化,减少计算图的冗余部分,提高执行效率(比如算子融合、常量折叠)。
在接下来,Ops Optimizer会对IR进行硬件相关的性能优化(重排计算顺序、内存优化)。
最后,Backend会生成硬件能够直接执行的代码。
算子融合
Computing Op + Activation 融合为 ComputingAct:
比如MatMul/Conv/ConvTranspose/Gemm + ReLU/PReLU/Tanh/Sigmoid,可以在计算向量的点积的过程中就套上ReLU。
1 | |
Computing Op + BatchNorm 融合为 ComputingBN:
公式变形得到新的W和B
支路并行融合:
左侧图需要访问内存中的A输出两次,但是假如把A复制一份,然后分别与BC融合,则节约了一次访问内存。

多个卷积核融合:
有的神经网络就是为了部署,设计上就能够融合,比如下面这种

算子优化
就算是单个算子,如何将它放到GPU上计算也有说法,因为不同硬件的核不一样,处理int8/fp32的个数也不一样。
由于算子种类的多样性,并没有一个一网打尽的优化手段能解决所有算子的高性能执行方式。算子优化存在以下挑战:
- 优化手段多样:要在不同情况下权衡优化及其对应参数,例如针对不同种类算子、相同算子有不同的参数可采用不同优化,对于优化专家来说也是相当耗费精力。
- 通用性与移植性:不同类型的硬件架构差异,使得优化方法要考虑的因素也有很大。例如硬件可使用的指令集,硬件的内存带宽,算力以及存储层次的影响。
- 不同优化间相互影响:各种优化之间可能会相互制约,相互影响。这意味着找到最优的优化方法组合与序列就是一个困难的组合优化问题,甚至是 NP 问题。
总结
当我们在谈论模型部署时,我们在谈论什么?
参考资料:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!