论文笔记 UniVTG:Towards Unified Video-Language Temporal Grounding
本文最后更新于:2024年4月13日 上午
论文笔记 UniVTG:Towards Unified Video-Language Temporal Grounding
新加坡国立+MetaAI的一篇ICCV23论文,其将Moment Retrieval、Highlight Detection、Video Summarization统一成了Video-Language Temporal Grounding的任务,并进行了预训练,得到一个Unified的模型,展示了在下游任务的强劲性能。
论文链接:ICCV 2023 Open Access Repository (thecvf.com)
代码链接:UniVTG: Towards Unified Video-Language Temporal Grounding (github.com)
研究动机

如图,作者主要考虑MR、HD和VS这三个任务。
- MR旨在通过文本查询定位视频中符合的片段;
- HD旨在给视频各部分打分,越符合视频主题的分数越高;
- VS旨在根据或者不根据文本,来得到视频中多个时间点,这些时间点的片段组合在一起能够较好总结视频内容。
作者认为这些任务有类似的目标,即Grounding,所以他们打算统一这些VTG的任务,提出UniVTG模型。
统一过程从三点出发:
- 从任务和标签的角度,定义了一种统一的范式,将视频分解为多个clip序列,每个clip分配3种基础的标签。从而能够进行统一的预训练。
- 从模型的角度,提出了一个统一的框架。
- 从预训练的角度,利用统一任务和统一框架,进行了大规模的预训练。
方法
 如图是UniVTG的pipeline,分成(i) (ii) (iii)三步,第一步将收集而来的各类数据转换为统一的格式,第二步利用大规模数据集进行统一的预训练,第三步在下游任务微调。
如图是UniVTG的pipeline,分成(i) (ii) (iii)三步,第一步将收集而来的各类数据转换为统一的格式,第二步利用大规模数据集进行统一的预训练,第三步在下游任务微调。
统一格式
视频包含个clip:,查询文本则包含个token:,每个包含三个元素。
- 是Foreground Indicator,为0/1二值标签,假如是前景则为1,反之为0。
- 是一个2d向量,和ActionFormer一样,是当前点距离时间段边界的距离,。整个区间表示为。
- 是一个的连续值,表示当前clip与的相似性。
下面介绍这种统一格式如何适配MR、HD和VS这三个任务:
- MR要定位出一个或者多个区间,可以定义为,即前景中的边界。假如有了MR的标注,则不在区间的,在区间的。
- HD就要得到视频中的高能点,即可以定义为。
- VS得到的片段就可以定义为。
数据收集
VideoCC是一个视频-文本对数据集,原本是通过文本来检索出长视频中的某个区间,然后提取这个区间与文本配对来进行视频级别预训练的,这篇论文则把VideoCC中0.9M的完整视频下载下来,然后以原本的区间作为interval label。
Ego4D是一个使用point标注的Video Summary数据集,每个点包含一个描述文本。这个数据集的1.8M数据直接拿来作为point label。
结合Ego4D和VideoCC,作者使用下面这种CLIPTeacher的方式获得更多的3种label。即从语料库中抽取一大堆的concept,然后CLIP-Text-Encoder与视频的帧级别CLIP特征进行余弦相似度计算,然后取平均分数最高的5个类别作为视频主要概念,得到curve,然后将相似度以0.05的间隔进行离散化,并取最大值作为interval。有了interval就能相应生成point。


最后,这篇文章获得了以下这些数据,预训练用了上面所说的数据,总共有4.2M的时序注释。之后也是进行了下游任务的广泛的评估。

统一框架

UniVTG的统一框架比较简单,视频编码器和文本编码器Follow了Moment-DETR的架构,视觉是CLIP-base+SlowFast(R-50),文本是CLIP。得到token级别特征之后,文本侧得到global特征与视觉侧计算clip级别相似度,得到。另一路两个序列拼接,加上时序和模态编码送到k层的Transformer Encoder中,得到结果通过一维卷积的两个Head得到。
训练的监督学习分成Matching、Localization、Contrastive三部分。Matching即的二值标签使用交叉熵。Localization使用L1和GIOU损失。Contrastive进行intra-video和inter-video的对比学习。
推理时,MR任务利用以及作为置信度,进行NMS。HD任务将的值进行排序,得到top-k。VS任务使用KTS算法(不太懂,Category-Specific Video Summarization),然后根据得到top-2%。
实验
对于模型规模,模态融合编码器4层Transformer,d=1024,head=8。
这些benchmark本人都不是很熟悉,所以简单看看。

👆Zeroshot的性能超过2019的论文,不预训练的情况下差不多是顶尖水平,预训练之后性能更是有非常高的提升。

MR任务上,NLQ是Ego4d的一个自己,所以Zero-shot就以及很强,预训练微调之后更强了。Charades也不错,但是TACoS的Zero-shot就不太行了,因为粒度有些细。但是预训练之后是真的秒杀其它。
其它的SOTA比较就不放了。
消融
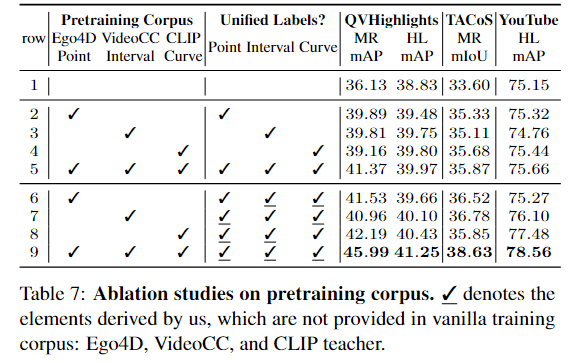
上半部分1-5主要是论证每一种数据都是有效的,下半部分6-9说明通过一种标签生成另一种标签页是有效的。

这个图也证明了预训练规模越大越好。

这里发现intra的对比损失效果提升非常高,应该是有一种negative mining的思想在。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!