论文笔记 Language-conditioned Detection Transformer
本文最后更新于:2024年4月10日 下午
论文笔记 Language-conditioned Detection Transformer
一篇CVPR2024的论文,提出了一种Open-Vocabulary的目标检测模型DECOLA,利用图像-文本对进行language-conditioned的训练以提升泛化性。
论文链接: Language-conditioned Detection Transformer (arxiv.org)
代码链接:https://github.com/janghyuncho/DECOLA
前置知识
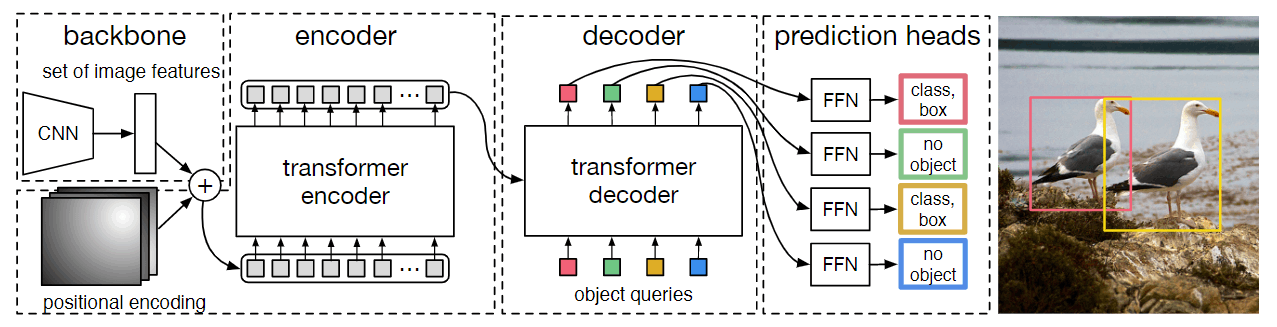
上图是Facebook于2020年提出的DETR模型,是最早一批利用Transformer架构进行目标检测的模型。其利用图像的特征图经过Transformer Encoder进行编码,然后作为key/value送到Transformer Decoder进行解码,解码时query设置为一些可学习的向量作为object queries,解码后的queries通过预测头得到目标检测框。
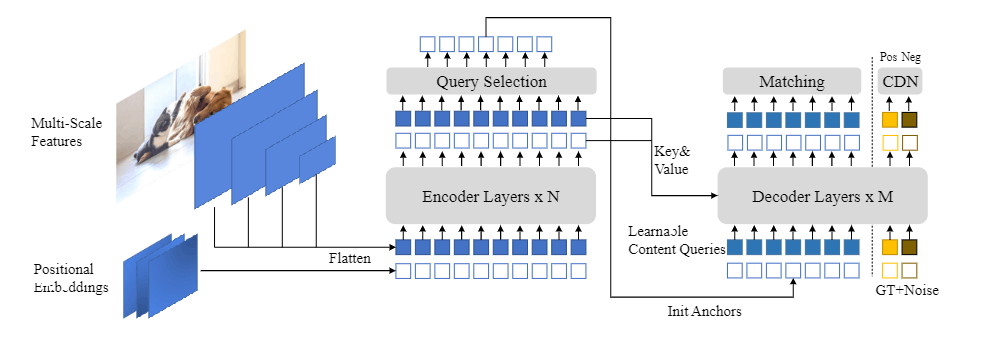
上图是一个2022年改进之后的DETR模型,叫做DINO。目前改进的现代版DETR在编码时会有Query Selection的过程,即query不是随意可学的参数,而是从图像中获得的某一块的特征,DINO就是预测每个区域的score,然后选择top-k个作为query。
DECOLA也是一个改进版本的DETR模型。
DECOLA
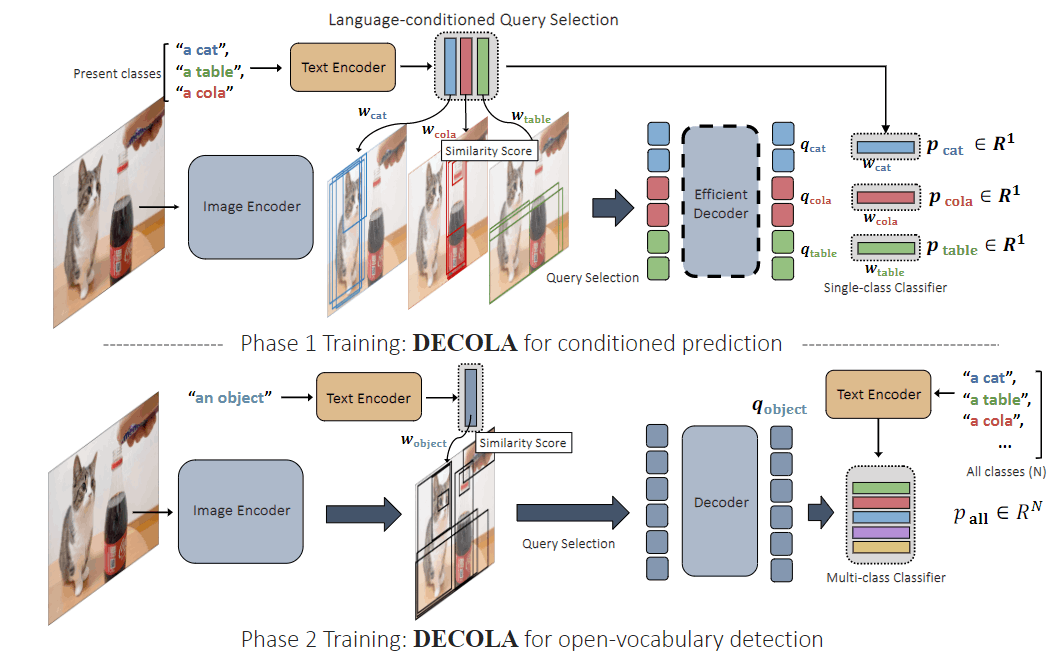
DECOLA将DETR的query改为“以language为condition生成”,并分成了两个phase进行训练。
- Phase 1:输入图像中存在的目标类别名称,输出对应的框
- Phase 2:OV流程,输入图像,输出proposal与text embedding进行匹配。
Phase 1
这一阶段首先提取图像的region feature(应该就是像素级别的,我不太清楚细节),然后对于图中存在的每一个类别得到对应的text embedding,两者计算余弦相似度,并为每一个类别选择top-k个region feature作为query 。
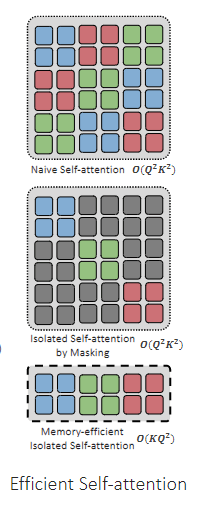
在Decoder中,通过mask的方式,使不同类别的query之间不施加注意力,作者发现这个操作可以优化到的复杂度(就是放到batch维度,比较简单)。
在最后的head中,对于每一个类别的query,需要得到其4-d的box坐标以及一个presence score,分别进行回归和BCE的损失优化。由于已经确定了query的类别,所以不需要进行多类的CE,只需要BCE。
总的来说,第一阶段有一点类似grounding,根据文本来找出图像中符合的区域。
query是来自于patch/pixel级别特征的,同一个object的特征要分别独立经过head得到bbox,这种思想和ActionFormer有点类似,ActionFormer也是要让行为发生区间内的每一个snippet特征都预测边界。
Phase 2
由于有了文本的加持,模型可以生成高质量的与文本相关的bbox,这种特性可以用来给image-text pair数据打伪标签。
为什么高质量?因为这里是有一种early fusion的情景,我们额外给出了先验信息“图中有xxx类别”,然后模型可以直接根据先验来关注特定的区域。
那么这种利用先验是怎么训练的呢?Phase 1的language condition就是起到这个作用。
比较有优势的是,这样可以off-line地打伪标签,不会引入额外的损失或者训练开销。
在Phase 2就利用伪标签带来的大规模数据进行OV形式监督学习训练。由于OV和Phase 1的形式有些许不同,所以需要对DECOLA进行一定的改造:
首先,把Phase 1中的language condition输入的类别文本直接替换成简单的"an object",然后把presence score的预测改为预测一个CLIP embedding进行训练。
作者在附录中讨论了DECOLA和另一个工作OV-DETR(Open-Vocabulary DETR with Conditional Matching)的区别。DECOLA的一个重要优势是,在Phase 2训练之后,是不进行condition推理的,而OV-DETR需要,这决定了DECOLA的推理速度比OV-DETR快很多。
如下图所示,假如要做condition,就要做early-fusion,则Decoder需要反复前向传播很多次。而DECOLA不需要,所以Decoder只需要传播一次,然后用余弦相似度匹配即可。

实验
作者贴心地评估了DECOLA的Phase 1、2的性能。使用了OV LVIS、LVIS、ZS lVIS、ZS COCO、ZS Object365、ZS OpenImages这些benchmark。
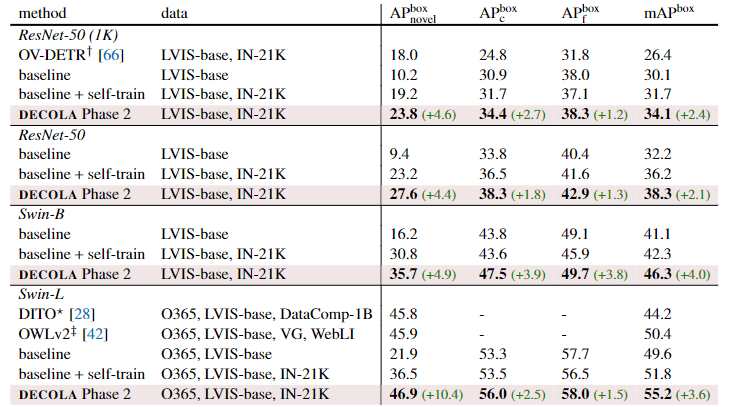
具体的实验细节可以参考原文,下面给出在OV LVIS上的DETR架构的比较,可以发现,使用了IN-21K来训练,效果提升了非常非常非常多。
下面两张图是GitHub上的Phase 1的两个结果(仅在LVIS数据集训练),第一张图放大可以看见,即使故意错误拼写了knif(knife)和piza(pizza),模型也能准确得到框。第二张图的cola和mentos都是LVIS中不存在的类别。


下表探索了将两种训练方式(conditioning、multi-class)结合的效果,(e)中是进行co-train的概率(p=1.0就是两者混合,p=0.0就是和原来一样),发现co-train时c-AP是会下降的。(f)没看懂,但是作者说伪标签的质量是非常重要的。
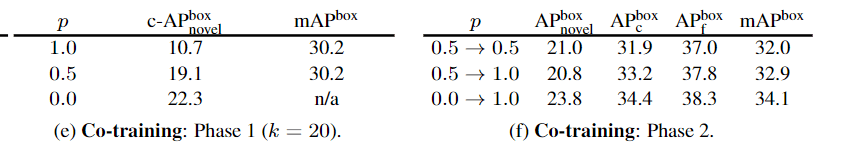
展望
目标检测领域太成熟了,这些指标天花乱坠,看不懂,但是貌似这篇文章的性能是很好的。
DECOLA主要利用了Condition的高精度的优势来打伪标签,然后再进行微妙的转换,第二阶段利用第一阶段的训练成果以及第一阶段打的伪标签,同时还避免了condition在推理阶段的性能损耗。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!