论文笔记 AttrSeg:Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation
本文最后更新于:2024年4月8日 中午
论文笔记 AttrSeg:Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation
上交的一篇NIPS2023(2024.1),进行Open-vocabulary的语义分割,其将类别通过大语言模型和人工分解成多种属性,然后提出了一种AttrSeg网络来通过这些属性进行语义分割,从而提升Open的能力。
由于本人不了解该领域,本文介绍其基本思想和少量关键实验
论文链接:AttrSeg: Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation (arxiv.org)
AttrSeg: Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation | OpenReview
思路

如上图左,在OV的语义分割情况下,会遇到三种问题:
- Ambiguity:不完整或者过于简洁的名字带来歧义。(比如龙可以指西方龙,也可以指东方龙)
- Neologism:一些新词模型没有见过,难以描述。(比如科幻中的生物等)
- Unnameability:不知道怎么去命名
为了解决这些问题,这篇文章提出了Decomposition-Aggregation两阶段(上图中),分解阶段将标签分解为一系列的属性,比如颜色、形状等;聚合阶段则通过网络聚合用户提供的描述属性来预测mask。最后如上图右所示,能得到较好的结果。
AttrSeg方法
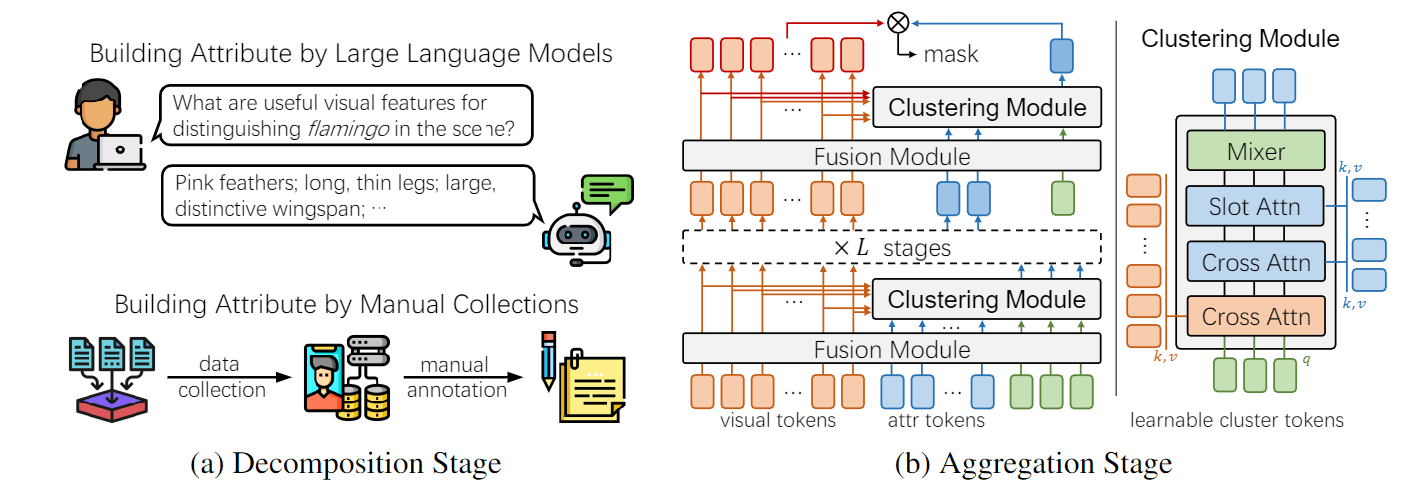
Decomposition Stage
对于通常的数据集(PASCAL、COCO),LLM可以得到它们的属性。同时这篇文章也搜集了一个新的数据集“Fantastic Beasts”,其包含20种哈利波特神奇动物系列电影的奇幻生物,并且人工标注了每个类别的属性。
Aggregation Stage
对于图片提取CLIP视觉特征,对于属性,分开提取CLIP文本特征。
Agg阶段使用了分级设计,如上图(b)所示,一个block(图上说stage,但是有点混淆)包含Fusion和Cluster两个模块,前者是一个普通的Transformer Encoder Layer,后者则如图(b)最右边所示是一个比较复杂的结构,其作用是根据视觉信息和属性信息,来得到一个全局的属性表征,其具体设计架构如下:
- 初始化几个可学习的向量,对视觉和文本特征分别做交叉注意力
- 与文本额外做一个Slot Attention,算法如下图所示,基本上就是cross-attention中注意力机制后加一个GRU。在Slot Attention中,是同一份参数反复迭代T次得到输出,但是这篇文章没有细说迭代多少次。
- 这些cluster tokens最后通过MLP-Mixer的架构进行token和channel的mixing进行编码,相当于一个简化版的Transformer层。

不同block输入的可学习向量的个数不一样,最后一层使用1个向量,就能得到全局的文本侧(标签侧)表征。
最后,利用两路特征,通过相似度比较和上采样就能得到分割结果。
除了层级聚合的架构,作者尝试了以下的几种架构,后续有消融实验。

文章认为属性potentially contain hierarchy,所以设计了层级聚合,但是后面却没有这个结论的验证和讨论,这一部分研究动机我觉得是欠缺的。
实验
实验配置
OVSS的标准实验是PASCAL-5和COCO-20数据集,前者20个类别,每个fold15个训练、5个测试,总共有4个folds;后者则是80各类别分成4个folds。训练好后,还在PASCAL VOC和PASCAL-Context上进行验证。除此以外,他们还在自己弄的Fantastic Beasts的20类别上验证。mIoU作为指标。
AttrSeg整了两个版本,使用CLIP ViT-L和ResNet101为backbone,类别对应15个属性。
实验表格


相关文献比较少,已有文献的比较结果都比较好。


在他们自己的数据集上也体现了优势,同时FB这个数据集上用attr的方式才能行得通,否则mIoU会非常非常低。

对于agg的策略,结合前面几个表格,post是传统方法中最好的,而层级式的是最好的,提点很多。
鉴于Hrchy的方法引入了非常多的参数量,这里有一些不公平比较的嫌疑,可能参数量多效果就更好

各个模块的消融实验,Mini的set指的是只留下Slot-Attention。可以发现,去掉MLP-Mixer后参数下降,表达能力也下降。CrossAttn和Slot-Attention感觉上作用是有一些重复的,但是实验这里去掉了Attr的CrossAttn后结果是有一定下降的。
为什么不做去掉Slot-Attention的实验呢?

作者进行了噪声对识别效果影响的实验,inaccurate是给属性中加一些相同类别其它图片的属性,incorrect则是加一些完全不同类别的属性,这两种“加料”均在训练阶段进行。加上之后,性能有一定的下降,作者使用VLM进行简单的过滤得到了一定的效果。
这个实验很令人迷惑,应该是一个类别对应一批属性,这里Inaccurate是怎么做的?人为标注一些inaccurate的数据吗?
而且,为什么要在训练阶段加噪声呢,不应该都在推理阶段进行吗,考验用户输入带噪时模型的表现?
VLM filtering的具体设置没有介绍,而且单独VLM filtering在测试阶段进行。
而且就单独这一个表没有说是在什么数据集上使用什么模型进行的实验。

这个实验大概将属性分成了4类,考察了每个类别的贡献。
叠加形式的实验感觉不是很能体现哪个最要紧,根据差值是Shape最重要,但是Color重不重要完全体现不出啊。
假如是我,我会标注差值或者使用移除的方式进行实验。
可视化

结论
这篇论文的部分研究故事是我很感兴趣的,即通过属性的方式解决Ambiguity、Neologism、Unnameability三个OV中会遇到的问题,但是层级和部分实验感觉不太行。
类似思路:[论文笔记 Multi-modal Prompting for Low-Shot Temporal Action Localization - Kamino’s Blog](https://blog.kamino.link/2024/02/05/multi-modal prompting for low-shot TAL/)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!