论文笔记 Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization
本文最后更新于:2024年3月27日 晚上
论文笔记 Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization
论文链接:CVPR 2023 Open Access Repository (thecvf.com)
上海交大王延峰组的一篇CVPR23,进行弱监督TAL任务,即利用视频级别的标注来定位视频中动作发生的区间。作者发现这个任务中,基于分类预训练的模型具有较高的TN值,但是FN值也高;基于视觉-语言预训练的模型则具有较高的TP值,但是FP值也高。这篇文章利用两类模型互相协作得到更佳的性能。
动机解释
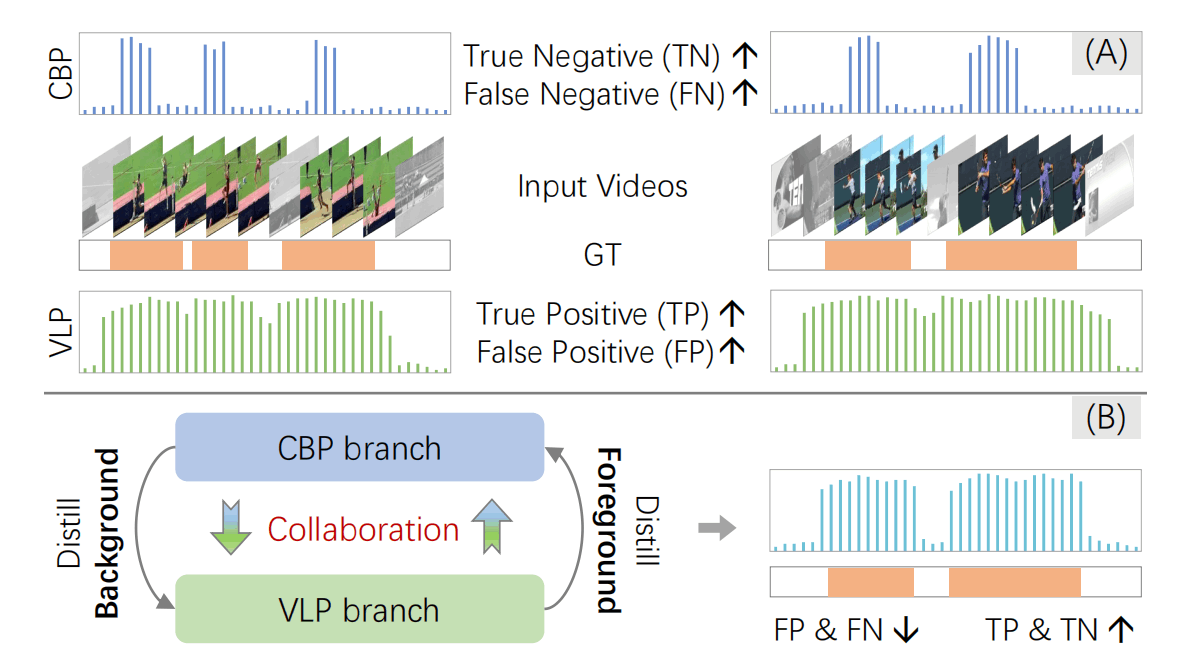
如上图所示,基于分类预训练的模型(Classification-Based Pretraining,CBP)具有较高的TN值,但是FN值也高;基于视觉-语言预训练的模型(Vision-Language Pretraining,VLP)则具有较高的TP值,但是FP值也高。说人话就是:CBP模型比较保守容易把正例给漏了,VLP模型比较激进容易把误判成正例。
那也就是说,CBP的Negative的标签比较可信,VLP的Positive标签比较可信。在弱监督学习中,恰好需要获得高可信度的伪标签,所以这篇文章利用这一点进行双支路的协作训练。
此外,文章把negative作为background,把positive作为foreground。
方法

如图所示是这篇文章的整体架构,上面是I3D+时序编码backbone,下面是CLIP+时序编码+跨模态相似性计算。都是比较简单常规的backbone。
对于两路,作者使用双阈值进行标签分类:设置高阈值和低阈值,高于高阈值的是前景(标记为1),低于低阈值的是背景(0),处于中间的是不确定(-1)。
为了让优化有个开始,作者先对CBP使用常规的MIL损失进行热身。
之后,开始进行B-step和F-step(B和F分别对应Background和Foreground)。
- B-Step:冻结CBP支路,令其生成可信的背景伪标签,计算其与VLP预测概率的KL散度。
- F-Step:冻结VLP支路,令其生成可信的前景伪标签,计算其与CBP预测概率的KL散度。
注意,两个KL散度计算都只计算可信标签的部分。
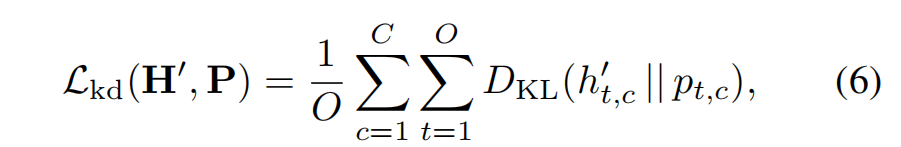
注意,文中又强调生成的伪标签同时包含前景和背景,只是不同支路生成的比例不同罢了。
从这个角度看的话,文中的动机有一点被削弱了,基本就是两路的互相蒸馏。
此外,文章还进行了对比学习,其使用InfoNCE的改版,其对两路都起作用 ,对于某一路得到的高置信度的正例和负例,组成集合,高置信度的特征两两计算相似度,和是分母,分子则是正例之间的相似度。
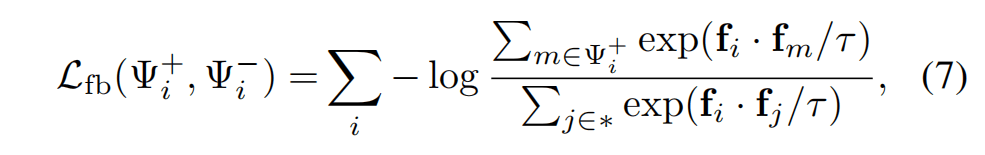
推理
推理时为了处理光流,只使用CBP一路,得到帧级别分数后,通过阈值限制,并连接相邻的snippet构成proposal,然后用softNMS消除多余的。
这里softNMS有用吗?按照这个逻辑应该没有重合的proposal呀。
实验
SOTA比较
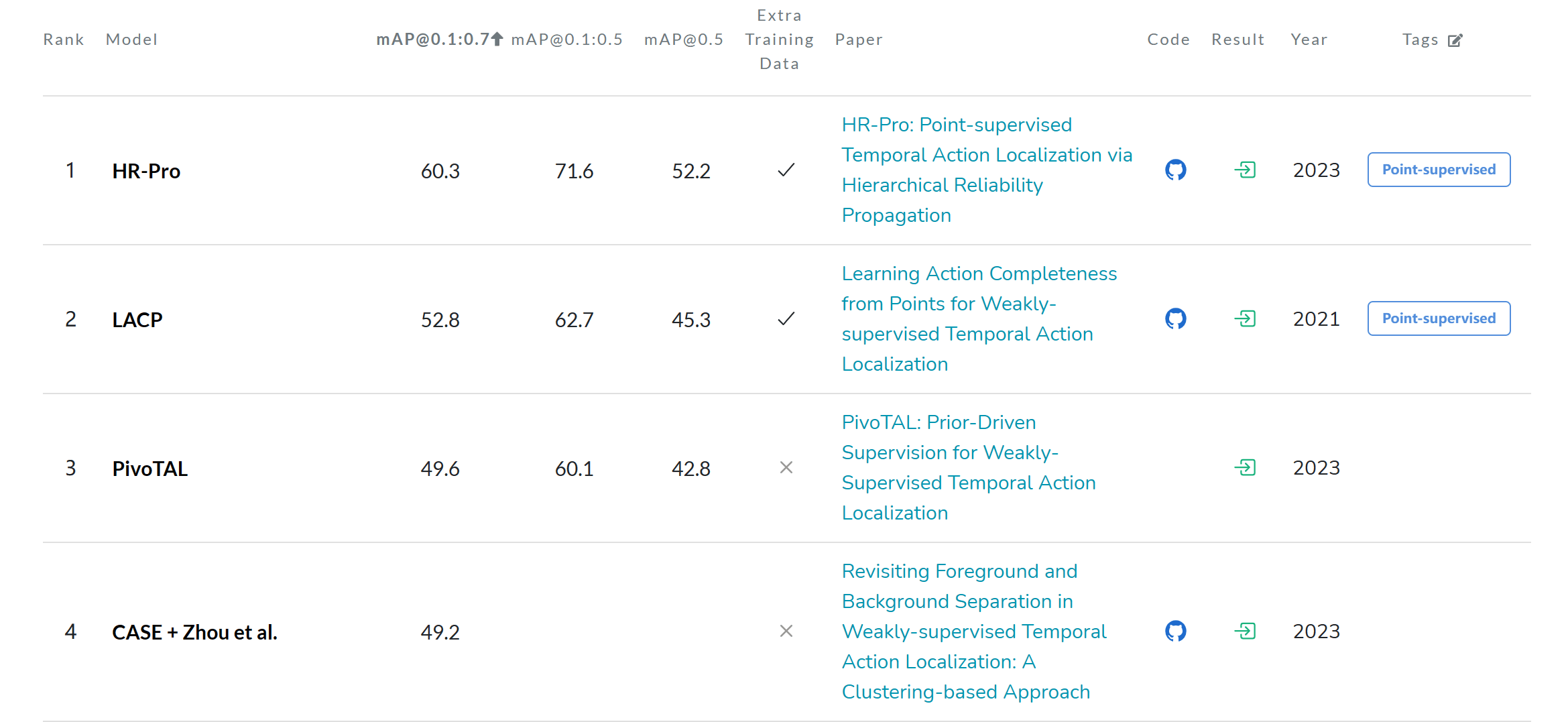
比较基础,在THUMOS14和ActivityNet1.2上比较,直接看结果的话,AVG的IoU提升非常明显。


目前(2024.3)来说,paperwithcode上也是能排到第三的位置
消融实验
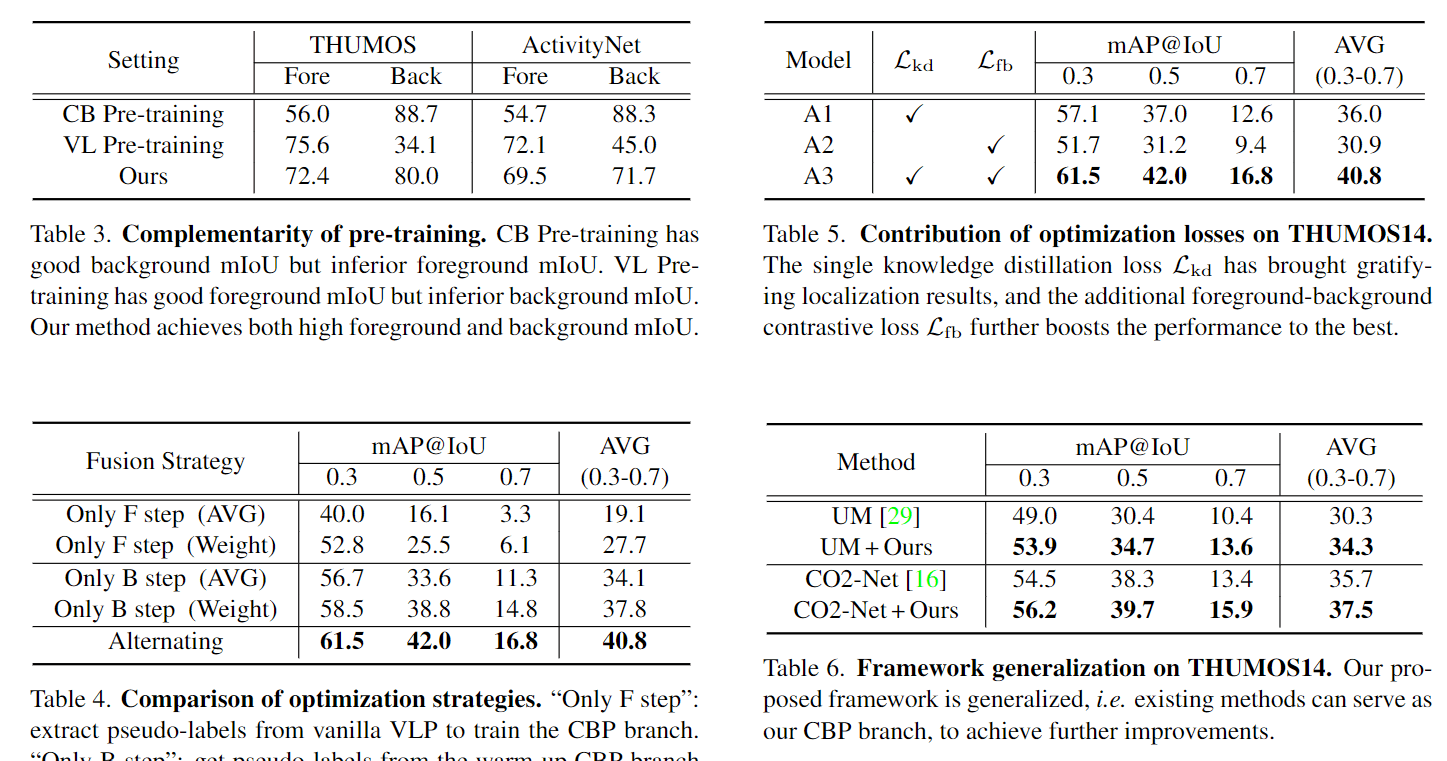
Tab3是对论文假设的验证,证明两路模型有不同的侧重点,而这篇文章的方法能比较好地融合。
Tab4是不进行Collaborate的消融,也就是做单向的蒸馏,效果不会更好。
Tab5是loss的贡献,这样看来,对比学习的loss也提升了很多点。
Tab6是一般人不会做的实验,为了证明方法的泛化性,找了不同的baseline来加上他们的方法,结果提升很多。
可视化
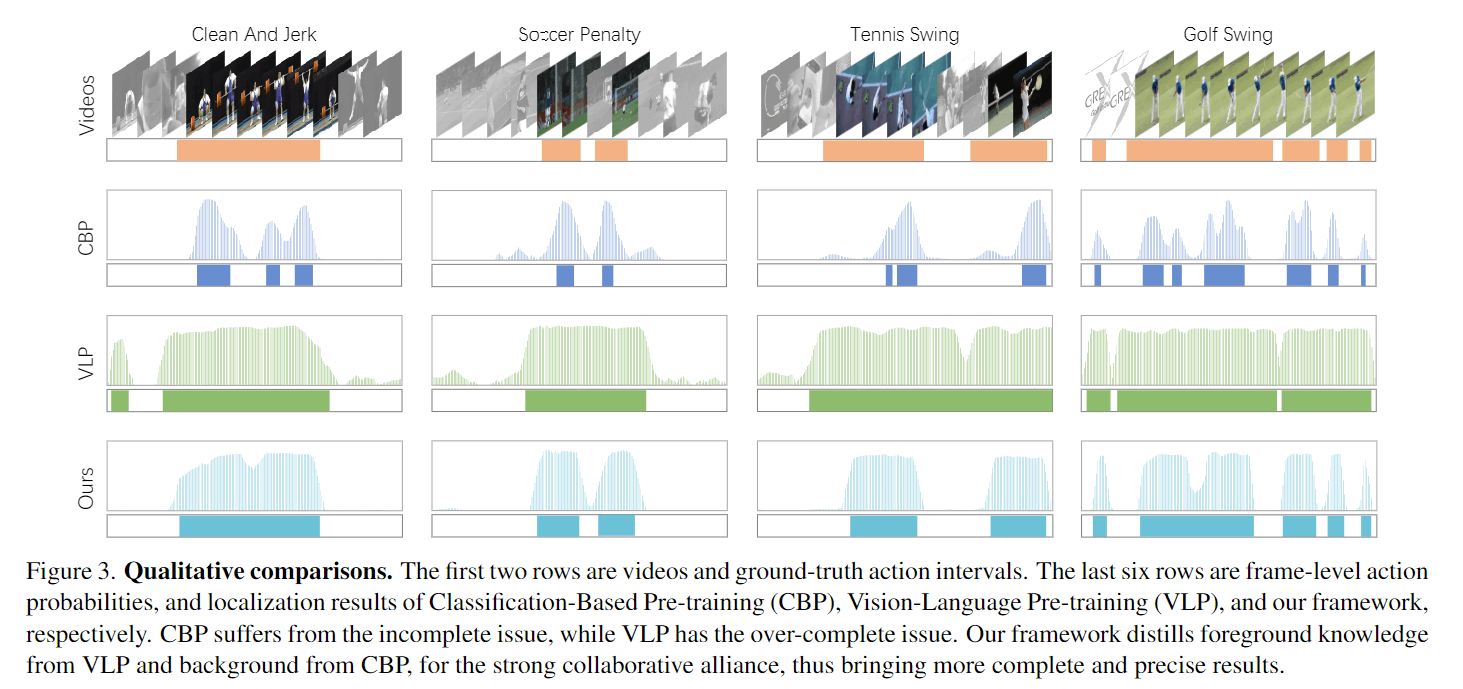
这个可视化真的很能验证假说。
结论
我感觉确实是一个非常扎实的工作,研究故事讲得很完整,作者未来工作打算做更大规模end2end的训练。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!