论文笔记 Vision Transformers are Parameter-Efficient Audio-Visual Learners
本文最后更新于:2023年5月21日 下午
Vision Transformers are Parameter-Efficient Audio-Visual Learners
论文链接:https://arxiv.org/abs/2212.07983
代码链接:GenjiB/LAVISH: Vision Transformers are Parameter-Efficient Audio-Visual Learners (github.com)
CVPR2023的一篇关于少参数训练多模态视音频模型的论文,使用了最近火热的Parameter-Efficient的方式,将ViT冻结,通过只训练一种叫作LAVisH的Adapter进行音频编码和模态融合,从而以极低的参数量达到令人满意的效果。
LAVISH
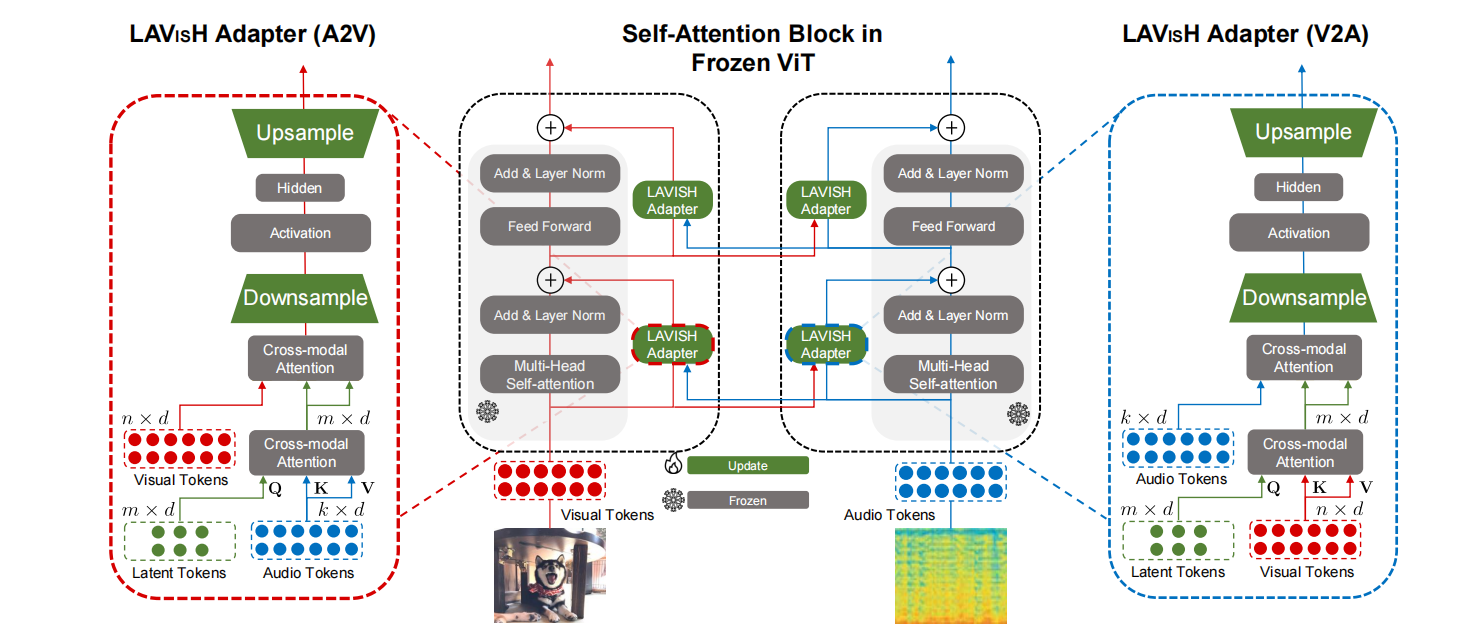
论文整体框架如上图所示。
首先图像经过Tokenize之后得到视觉Token,音频转化为频谱图后也类似得到音频Token。
随后,两个模态都会经过同一个基于ViT的冻结的Backbone,而在自注意力部分和FFN部分会通过可训练的LAVISH Adapter进行模态融合。这些LAVISH就是训练中要调节的参数。
两个模态的LAVISH设计相同,以左边的A2V为例,其将音频信息引入到视觉特征中。首先会通过Cross-Modal Attention(CMA)和Latent Token得到紧凑的音频模态信息,这里CMA是参数量极少的类似交叉注意力机制的模块,其公式为:
与交叉注意力相比,CMA没有QKV映射矩阵的参数,也没有输出映射矩阵的参数,是直接将QK相乘然后softmax,再使用一个可学习的权重来控制从另一个模态过来的信息。Latent Token则是和Perceiver、BLIP-2、CoCa、Flamingo中类似的,通过可学习的张量作为Query,通过交叉注意力的机制从长序列特征中提炼特征。
在得到另一个模态的紧凑特征后,还会通过一个相同的CMA,但是此时Latent Token是Key和Value,当前模态是Query,也就是让当前模态吸收另一个模态的紧凑特征信息。
经过注意力的分配之后,类似Transformer原本的架构,也经过一个FFN,但这里就是和Adapter的设计一样,先降维,然后激活,再升维。
LAVISH与原本的模块呈现并行关系,每一层会在注意力块和FFN块都添加一个并行的LAVISH。
所以,需要训练的参数仅为降维和升维的参数以及几乎可以忽略的。
LAVISH下游任务
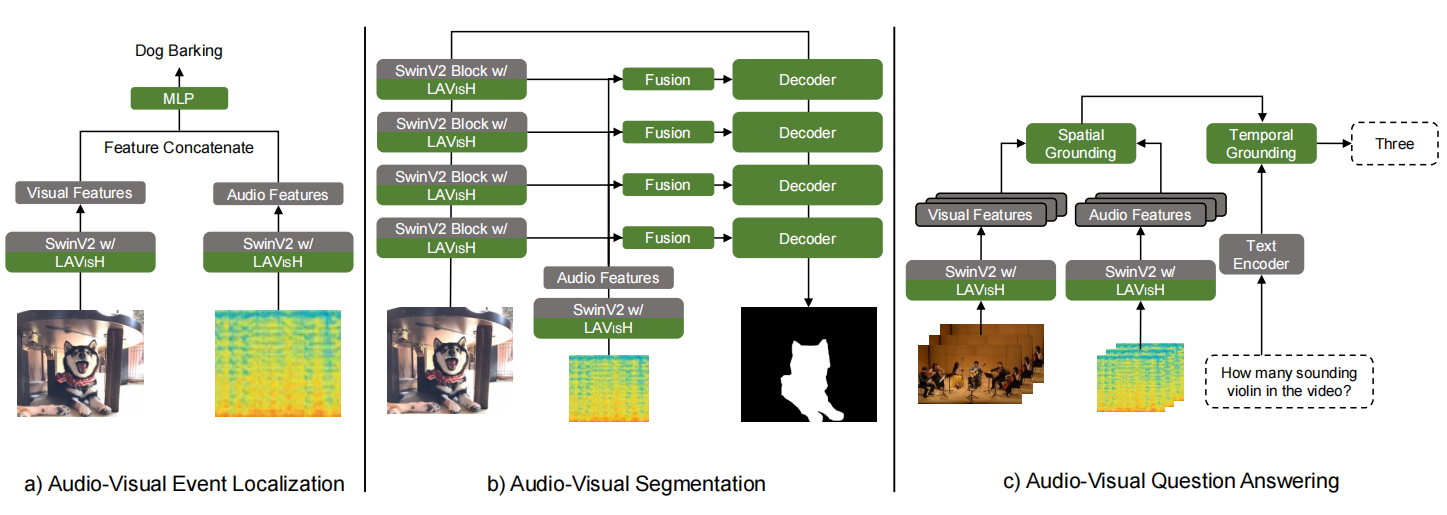
通过这种即插即用的设计,LAVISH可以应用在多个下游任务中,(a)任务就特征拼接+MLP分类,(b)任务使用了U-Net的结构,(c)任务使用了MUSIC-AVQA数据集的Baseline。
LAVISH使用的Baseline是Swin-V2-L网络。
实验结果
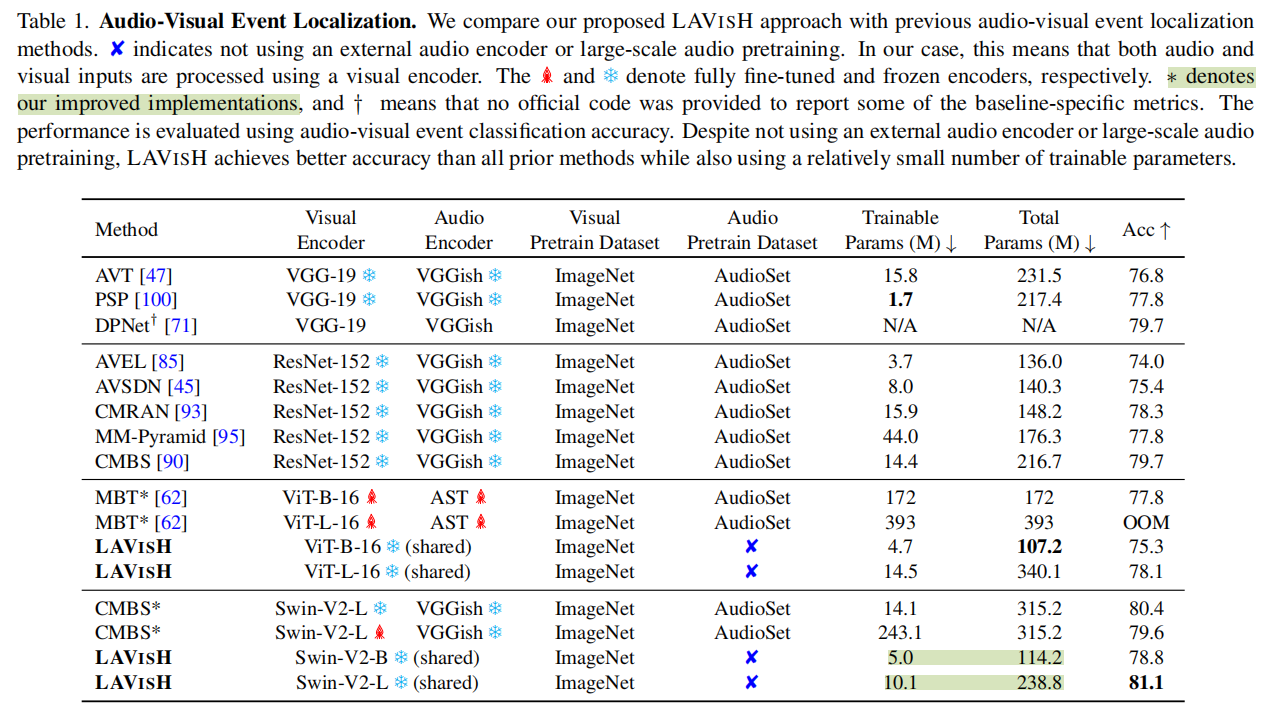
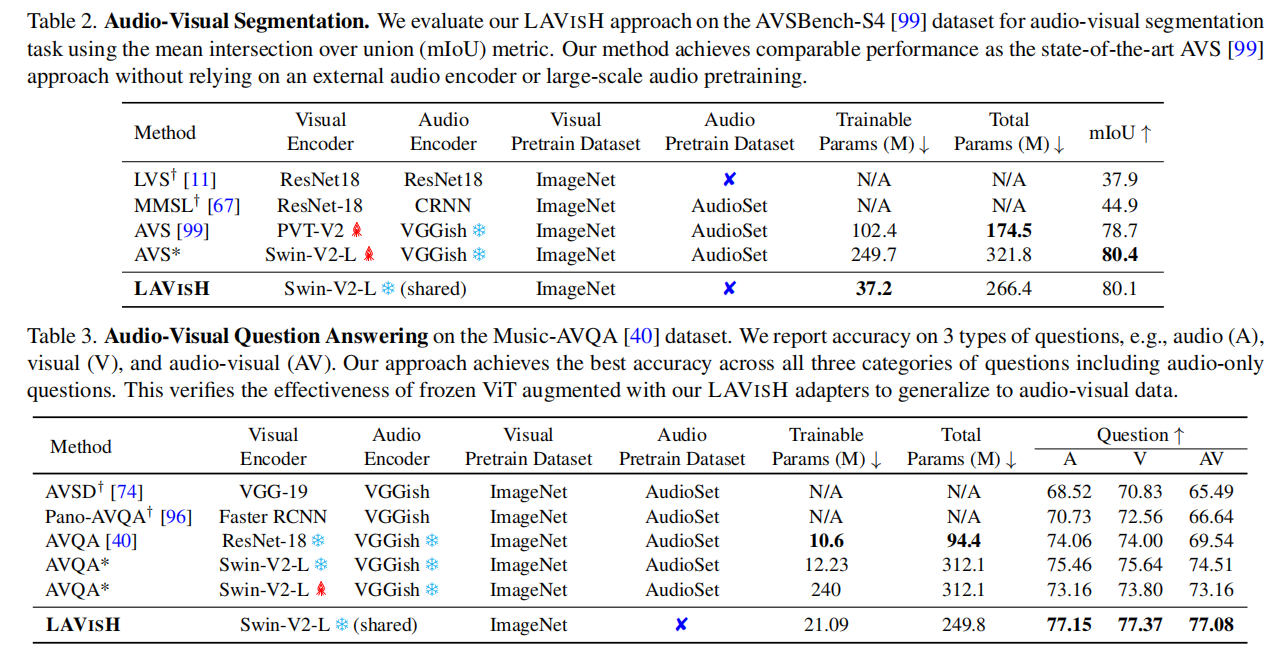
两个大表摆出来,作者主要关注的是是否使用额外的音频预训练数据集以及训练的参数量,可以发现在不使用AudioSet预训练的情况下,LAVISH的结果已经超过了大部分模型,在于MBT的比较中,虽然使用Base的ViT效果比它差,但是LAVISH训练参数少,可用更大的Backbone进行超越,更别说MBT还要用AST这个额外的预训练模型。与CMBS的比较中,同样训练参数量小,但是LAVISH效果好,参数量还更少。
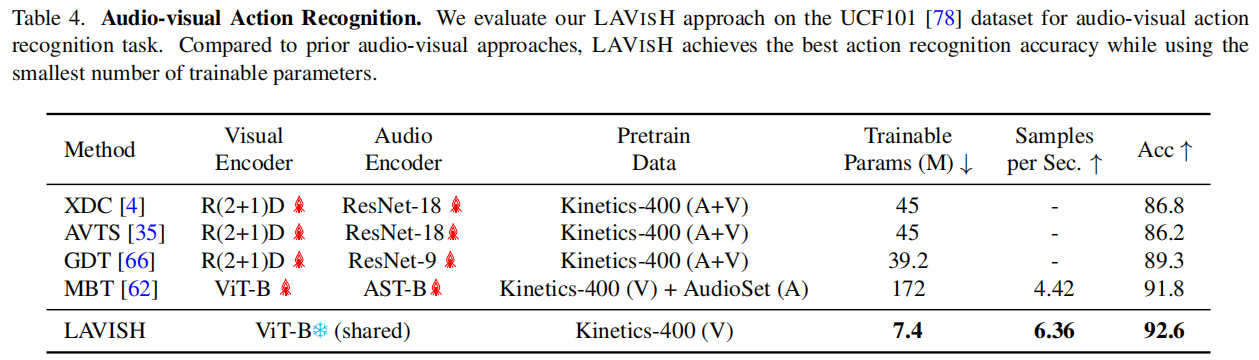
表2、3也是基本一样的比较思路,此外作者还进行了表4所示的动作识别任务,效果也十分惊艳。
消融实验
作者进行了非常扎实的消融实验。
LAVISH设计消融

两个方向的模态融合都有一定的作用,结合两者效果则更好。AVISH是不使用Latent Token的结果,GFLOP从11上升到了217。Latent Token的设计在降低计算量的同时,也能带来性能的提升。
与其它Parameter-Efficient方法的比较
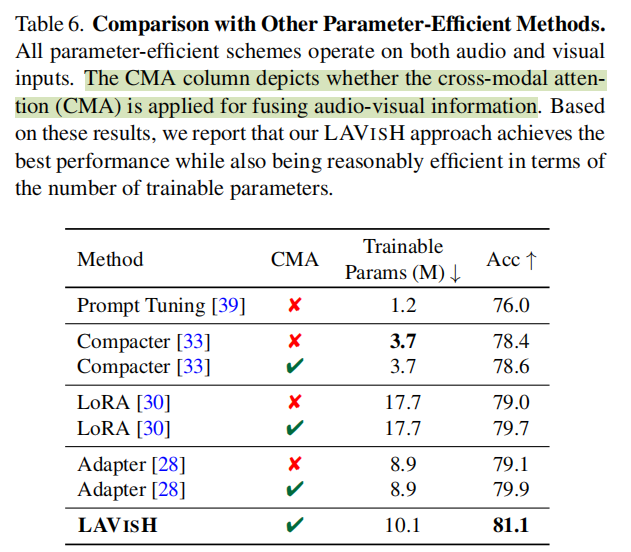
目前有许多Parameter-Efficient方法,作者测试了几种热门的,证明CMA带来的模态融合比较有用,Adapter+CMA的效果接近了LAVISH,而Adapter是级联,说明并联的效果会更好一些。LoRA也是并联,但是文中好像没说具体是LoRA在哪个模块。
Latent Token数量

证明少量的Latent Token就能得到较好的效果,所以计算量可以大大的节约。
额外的音频特征?

虽然已经考虑了音频特征,但是假如再加额外的预训练的音频编码器,效果还更好哦……这应该说明LAVISH学的还有些差距。题注里写是slight boost,但是感觉……提升还挺大的呀。
虽然参数量减少了,但是并没有减少计算量。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!