论文笔记 两篇关于Audio-Visual定位的论文
本文最后更新于:2023年3月27日 晚上
论文笔记 两篇关于Audio-Visual定位的论文
Audio-Visual Event Localization in Unconstrained Videos
论文链接:ECCV 2018 Open Access Repository (thecvf.com)
ECCV2018的论文,这篇文章提出了Audio-Visual Event Localization的任务,作者定义一个Audio-Visual Event就是同时会出现在视觉和音频中的事件,并以此收集了一个AVE数据集来进行三种任务:监督视听事件定位、弱监督视听事件定位、跨模态定位。作者提出了一个双模态残差网络(DMRN)学习这些任务。
AVE数据集
作者从AudioSet中选出了一个子集,包含4143个视频和28种事件,拥有视听事件的秒级标注,每个事件至少2s。

监督视听事件定位
一秒的视频与音频为一个segment,对应了一个C类(包含28种事件和1个背景类)的分类标签。视频和音频通过CNN之后进行audio-guided visual attention来生成上下文向量。这个向量是t时刻所有的token的加权,权重是两边走MLP后加在一起再过个Linear后softmax,以前常见的套路。
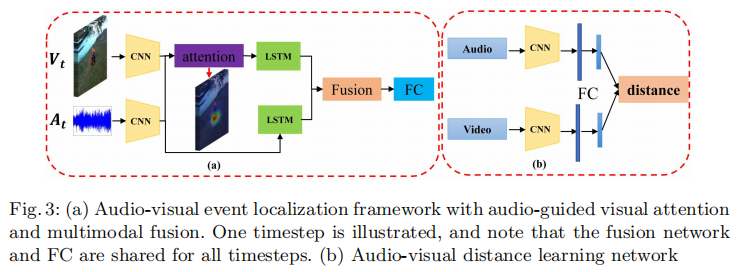

之后两个单独的LSTM编码,再之后通过一个简单的残差相加来预测。
弱监督视听事件定位
作为一个MIL问题,训练阶段预测每个segment的概率,然后所有时刻的概率相加再softmax,卡阈值选。
跨模态定位
上面的方法可以衡量视觉和音频特征的距离,用一个滑动窗口来定位。
实验结果
事实上,这个学习地还不错,通过attention map的可视化还能定位到更细粒度。

Self-Supervised Learning of Audio-Visual Objects from Video
论文链接:https://arxiv.org/pdf/2008.04237
项目主页:Self-Supervised Learning of Audio-Visual Objects from Video (ox.ac.uk)
ECCV2020的论文,该文章主要是通过自监督的方式来找到视频中的视听目标,即音频和视频中发音的对象。本文在4个下游任务上进行试验:多说话人声源分离、定位追踪说话人、同步视音频、正在说话人识别(不是弄这个方向的,任务名简单翻译)。
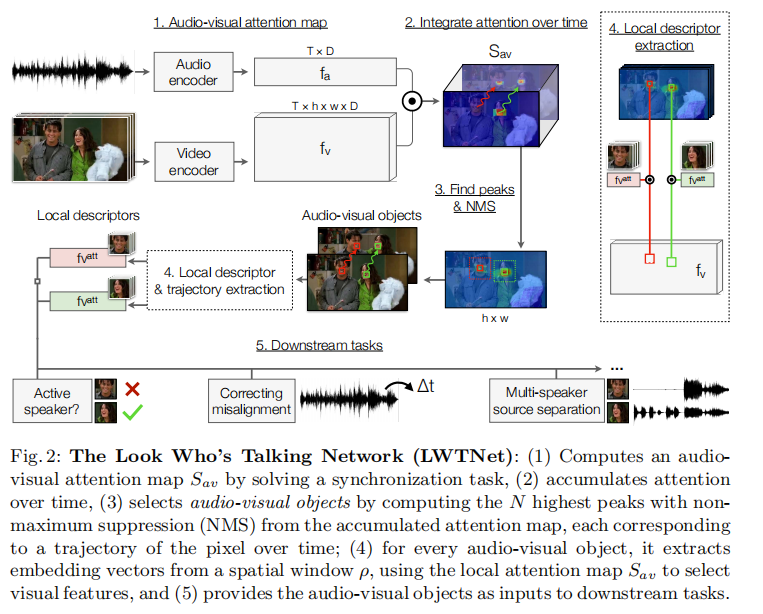
首先Audio Encoder和Video Encoder各自编码,视频侧会得到像素级别的attention map,音频也会得到每一帧对应的attention map。于是进行点乘得到,音频作为query,视频作为key。
之后运用预先提取好的光流来累积预测信心,第一帧的attention map最重要,会加到后面通过光流追踪到的像素上。
之后通过NMS把注意力图自下而上地汇集成instance。
最后提取局部特征。
训练任务就是拉近同步的视频和音频信息,拉远不同步的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!