论文笔记 mPLUG Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
本文最后更新于:2023年2月21日 中午
论文笔记 mPLUG Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
论文链接:mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections (arxiv.org)
代码链接:AliceMind/mPLUG at main · alibaba/AliceMind (github.com)
阿里巴巴达摩院于22年5月发布的大规模视觉-语言预训练模型——mPLUG,该模型在多个视觉-语言的下游任务(包括分类和生成任务)直到本文写的时间为止都处于SOTA,并且在运行速度上也有较大的提升。
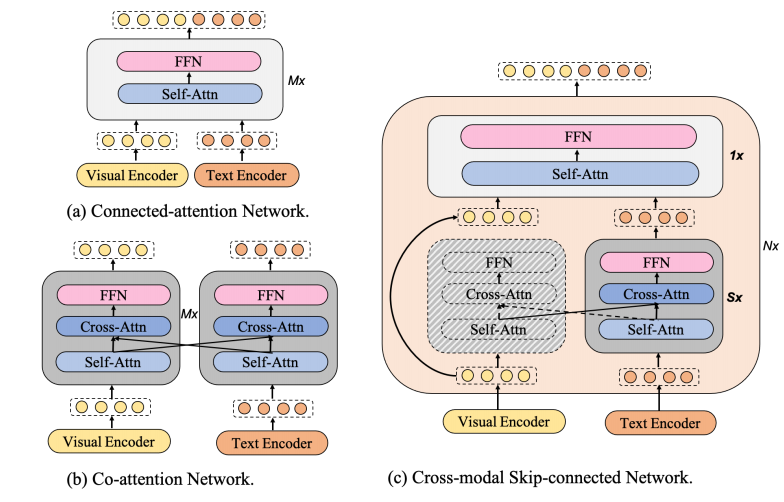
mPLUG设计了一种新的跨模态skip-connected网络,如下图,左边两个网络是传统常用的跨模态网络,(a)是类似BERT那样的Transformer Encoder,其将多个模态在时序上拼接之后进行编码,(b)则是co-attention网络,仅适用于两个模态,这两个模态会各自通过一个自注意力网络编码,然后在Cross attention中互相attend。
而(c)是本文设计的网络,其能够让融合发生在不同的抽象级别,也就是先但单独编码S层后两者再进行一次融合操作,作者在此是跳过了视觉模态的许多层编码层。
简介和相关工作
大规模视觉-文本预训练模型最近很火,大部分方法都是将视觉和语言学两个模态进行对齐,而挑战则是在两者之间找到合理的分配方式,从而缩小两者的语义差距。Oscar、VinVL、Up-Down这些模型使用了训练好的目标检测器来检测区域并与文本的一部分来对应,这种方式极大受限于目标检测器的效果、预定义的标签和标注的质量,而且这种方式在计算上也更复杂。Pixel-BERT、ALBEF、SimVLM、ViLT、METER这些文献则没有使用目标检测器,而是通过patch来学习的,这也带来了两大问题:① 效率:自注意力层在处理长patch序列更大计算量;① 非对称信息:训练的视觉-文本对中,一般文本是更短更抽象的,而图像则包含更多的信息,这种信息的不对称也是模态融合的一个难题。
视觉-语言预训练(VLP)模型粗分可以分成两类:dual encoder和fusion encoder,前者对于两个模态都有单独的编码器,然后通过简单的数学操作(如点乘)来进行模态交互,典型的有CLIP和ALIGN。然而,这些方法无法应对更复杂的视觉-语言(VL)理解任务,比如VQA需要更强的推理能力。后者则通过多层自注意力层或者交叉注意力层来进行深度融合,从而能够对细粒度的跨模态交互进行建模,典型的有UNITER、OSCAR、LXMERT、ALBEF、ERNIE-ViL,这些方法能够更好地捕捉两个模态间的关系,但导致推理速度更慢。
为了提升推理速度,Pixel-BERT、E2E-VLP和ViLT分别移除了特征提取的目标检测器、通过CNN网格特征进行训练、线性映射patch,而VLMo还通过一个shared mixture-of-modality-experts Transformer统一了dual encoder和fusion encoder。本文则采用了Skip-connection的方式来提升推理速度。
Skip-connection是常见的一种避免梯度爆炸或梯度消失的技巧,在ResNet和Transformer都被广泛使用,目前也有许多利用这个技巧的方法:ResNet是直接相加,highway network设计了一个transform gating function来控制输入和变化后输入的权重,DenseNet使后面的层能够重复利用前面的层的特征,Layer Normalization和recursive skip connection的使用也使模型优化更加稳定。本文则是使用Skip-connection来应对跨模态融合的问题。
mPLUG架构
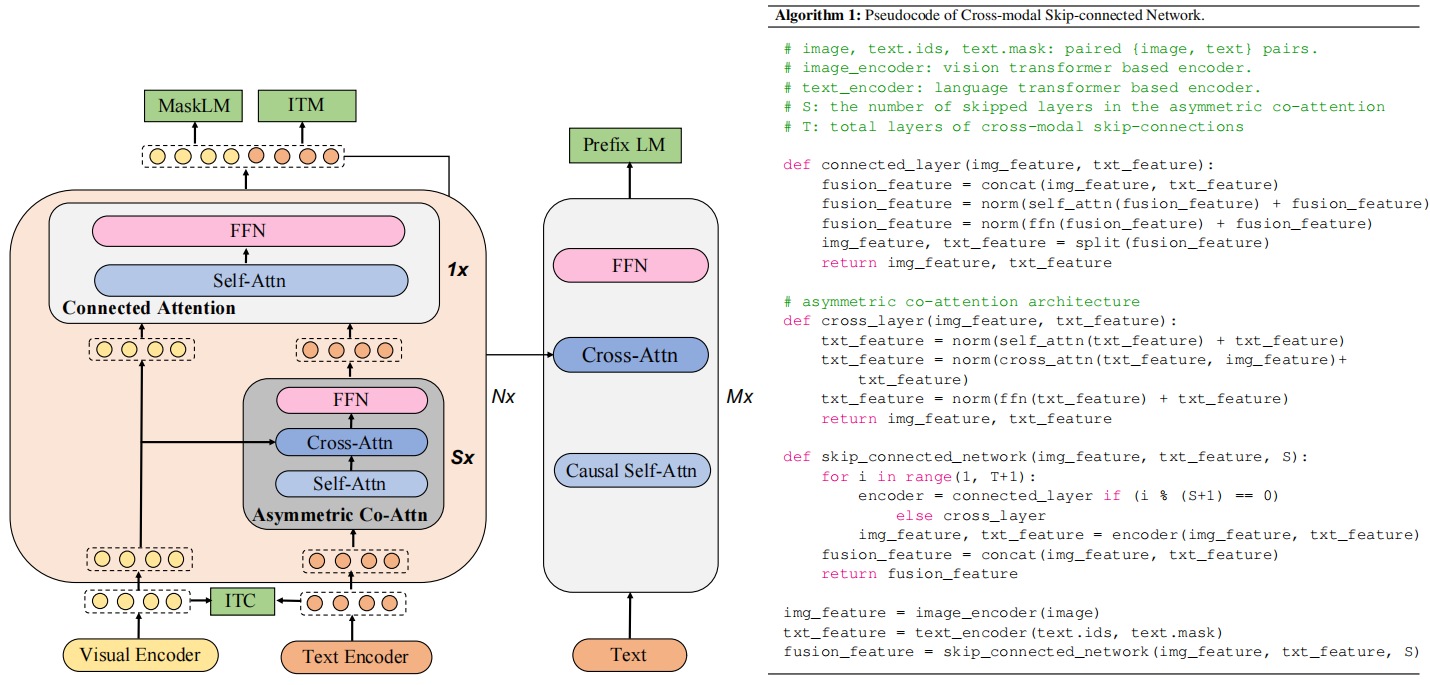
如上图,mPLUG先有两个单模态编码器(Visual Encoder、Text Encoder),然后是一个跨模态skip-connected网络和一个用来生成文本的解码器。
Visual Encoder是基于ViT的,能够得到图像各个patch的特征和整体特征([CLS]),Text Encoder也类似能够得到每个词元的特征和整体特征。跨模态skip-connected网络由N个skip-connected融合块构成,每个块又包含S个非对称Co-Attn网络和1个共同的Attn网络。这种设计的目的是利用上共同Attn网络的有效性和非对称Co-Attn的效率。
跨模态skip-connected网络
下面把Connected Attention Layer叫做连接层,Asymmetric Co-Attn叫做非对称层。
非对称层是由自注意力层(SA)、交叉注意力层(CA)和前项传播网络(FFN)构成的,前一层的文本输入首先通过SA得到,然后上一层的视觉特征通过CA被注入文本特征,得到,最后再通过FFN得到visual-aware的文本特征,具体公式如下(LN是Layer Norm):
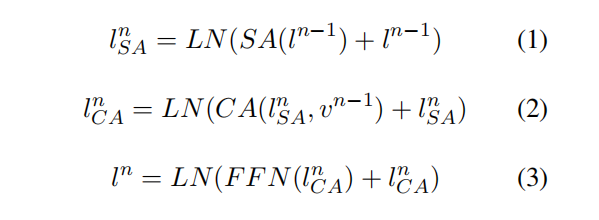
连接层则是由SA和FFN组成,上一层的视觉特征和S层非对称层的输出被凭借在一起,然后通过SA和FFN得到这个块的输出。
预训练任务
进行四个任务:图像文本对比学习(ITC)、图像文本匹配(ITM)、掩码语言建模(MLM)、前缀语言建模(PrefixLM),前三个比较简单,ITC就是像CLIP那样,ITM就是选择hard negative的对进行分类,MLM就是BERT那样。PrefixLM有一些些不一样,这个任务要根据跨模态的上下文来预测文本段的后续,和普通Language Modeling的不同在于这个任务会给出有意义的Prefix(类似于prompt)。
大规模分布式学习
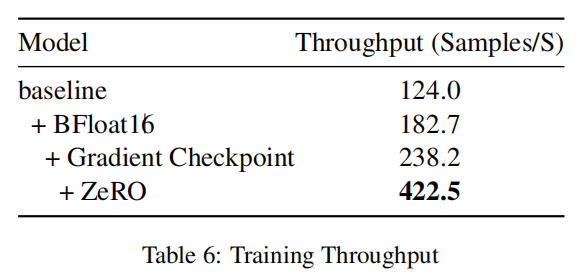
本文还通过减少内存、计算时间来提升模型训练的效率。作者使用了ZeRO方式来划分参数,单个GPU的静态内存能够被大约减少到1/N,N是GPU的个数。此外作者还使用了gradient checkpoint的方式来减少运行时内存。作者还用了BF16训练,比起FP16和FP32,BF16拥有与FP32相同的表征范围,但是减少了数值上溢的风险,并确保了模型的收敛稳定性,还和FP16的计算速度相当。
实验
数据与初始化
作者Follow了ALBEF的数据集,包含了来自MS COCO、Visual Genome、Conceptual Captions、Conceptual 12M、SBU Captions这五个数据集的14M图片文本对。
作者使用1024的batchsize在16张A100上训练了30轮,Text encoder和skip-connected网络都是6层的Transformer,分别由BERT-base的前6层和后6层初始化,Decoder则是12层的Transformer,Visual Encoder是CLIP的ViT-B/16或者ViT-L/14。
作者还介绍了一些学习率的分辨率的细节,请查看原文。
VQA实验分析
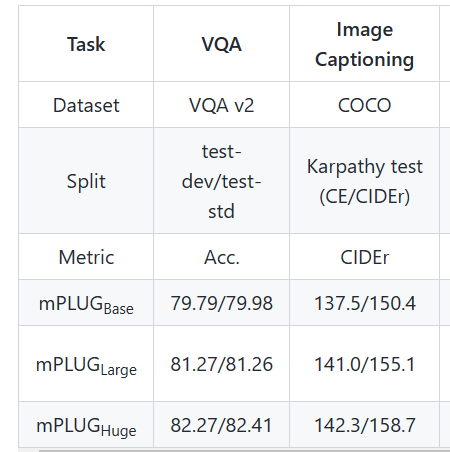
mPLUG将VQA看作是生成任务而不是多标签分类任务,如下表,在使用4M数据情况,mPLUG超过了同样使用CLIP的CLIP-ViL和METER(虽然超的不多),在更多数据的情况下,mPLUG也超过了SimVLM和Florence这些用了几十倍数据的模型。ALBEF和BLIP模型是只有Co-Attn的,mPLUG也超过了他们。
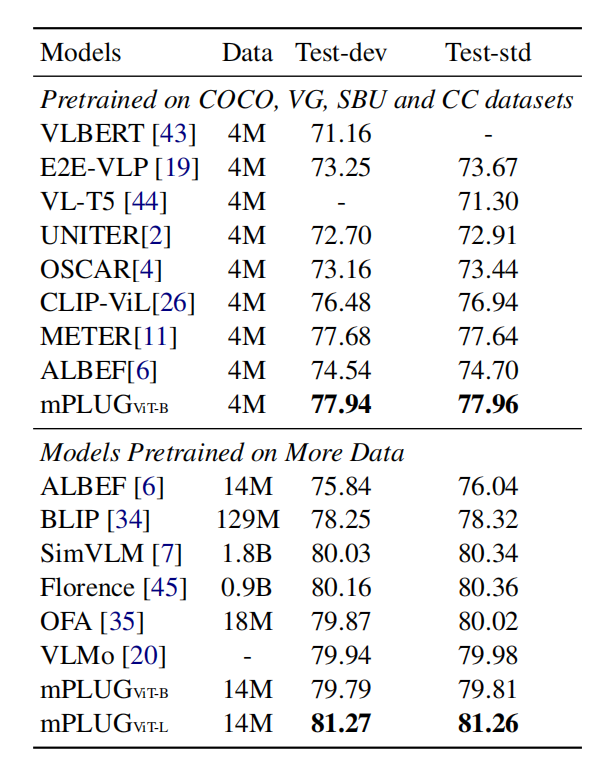
Image Caption实验分析
如表1,mPLUG使用COCO的训练集finetune,然后在COCO-test和NoCaps上测试,还提供了SCST 5轮的结果,可见mPLUG打败了使用更多数据的LEMON、SimVLM模型。
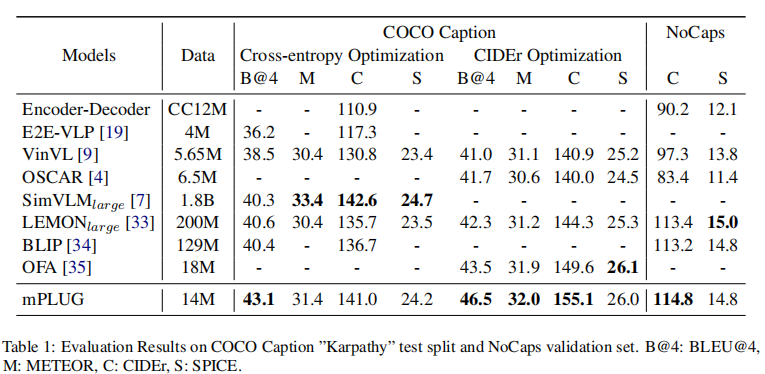
Image-Text Retrieval实验分析
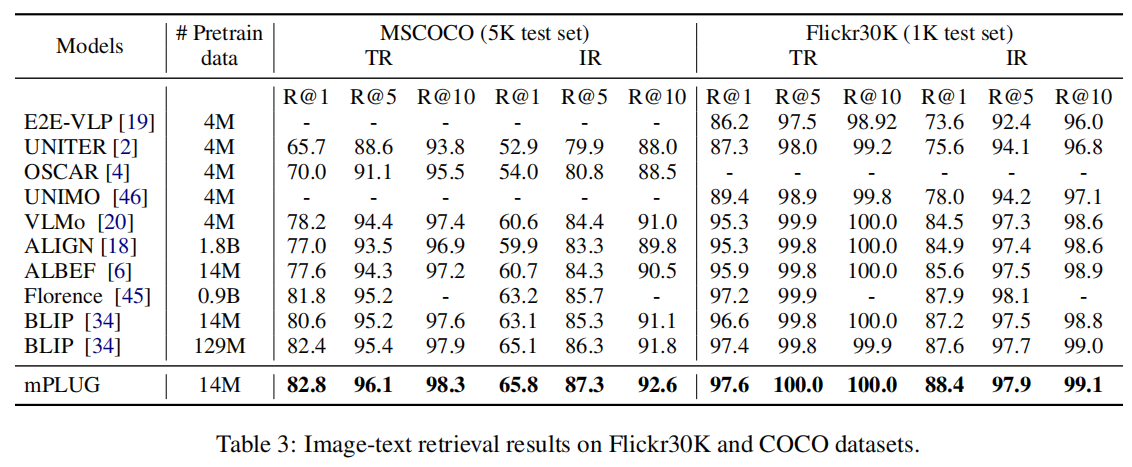
作者使用ITC和ITM进行微调,推理时,选择top-k个点乘相似度高的candidate,然后再根据ITM的分数排序。在两个方向上的检索结果如下,COCO和Flicker30K上都SOTA,也是打败了更多参数的模型。
Visual Grounding实验分析
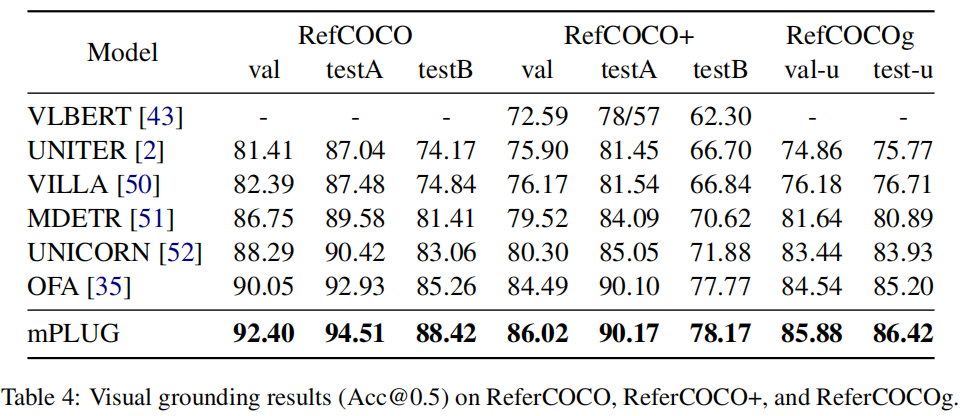
这个任务要求定位文本描述的图像区域,本文不直接回归bbox,而是组合视觉和文本特征之后送进decoder来预测坐标。下表可以发现仍然是SOTA。
Visual Reasoning实验分析
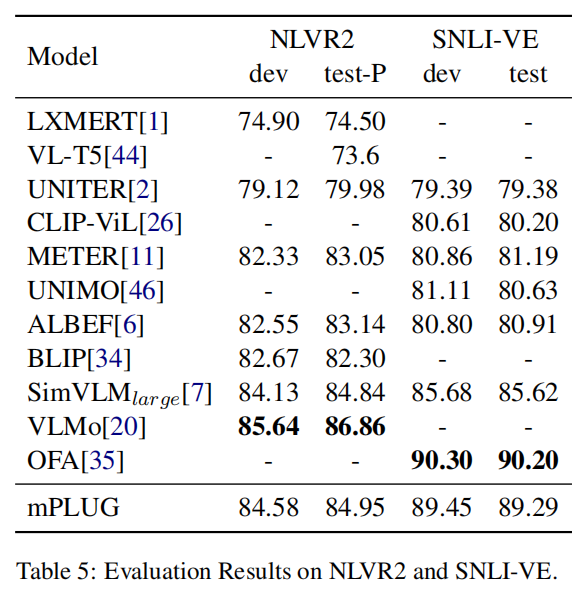
任务给定两张图片,要求分析文本是否能够描述关系。本文Follow了BLIP的方式,使用了两个CA层来处理两幅输入图片,然后将他们的输出结合并输入进FFN,最后接MLP在[CLS]上进行分类。这里比SOTA差了一点点,作者分析还是因为OFA和VLMo添加了大量只有文本或者只有图像的数据。
有效性和效率分析
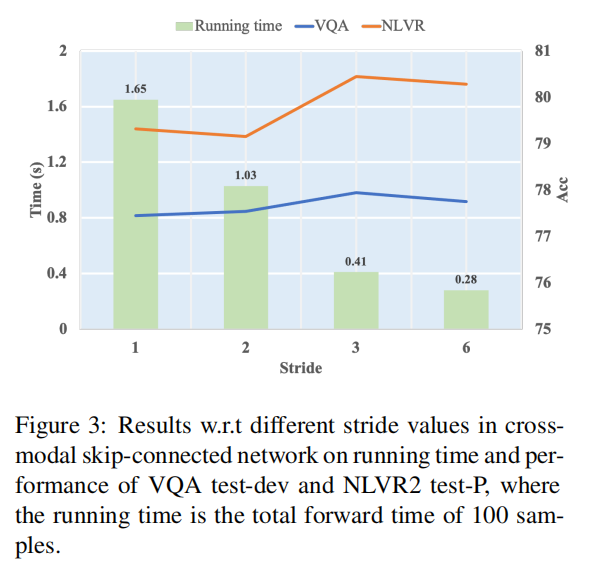
非对称层的那个S越大,计算时间就越短,同时性能也会有不同,如下图,为了效率,本文使用S=6进行预训练。
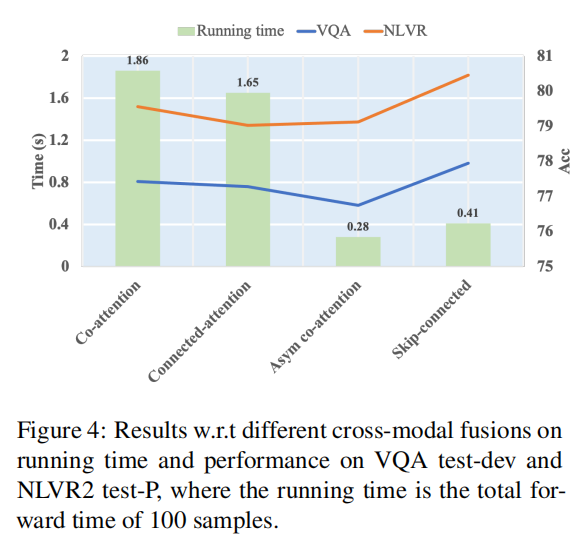
模态融合消融分析
使用不同融合模块的时间和性能对比,可以发现Skip-connected效果好,而且快。
训练加速分析
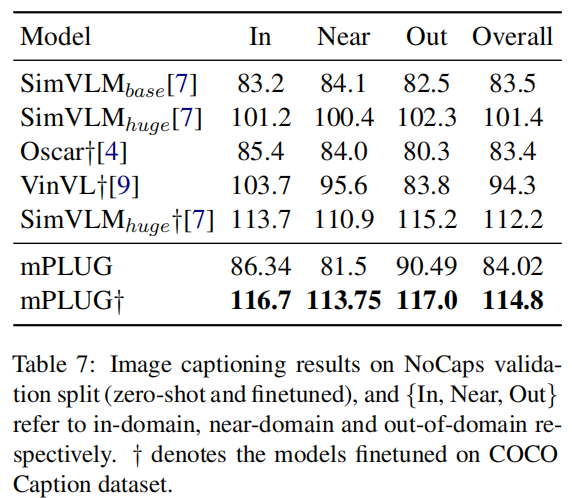
Zero-shot迁移能力
如下图,在Image Captioning方面,本文直接使用预训练的模型在NoCaps上预测,结果与Oscar和VinVL接近,在COCO上微调之后,更是SOTA了。在Image-Text Retrieval方面,没有微调的方法中SOTA,微调之后同样SOTA。
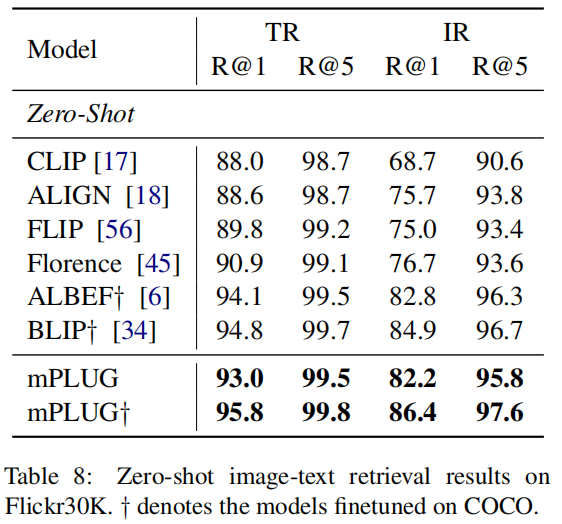
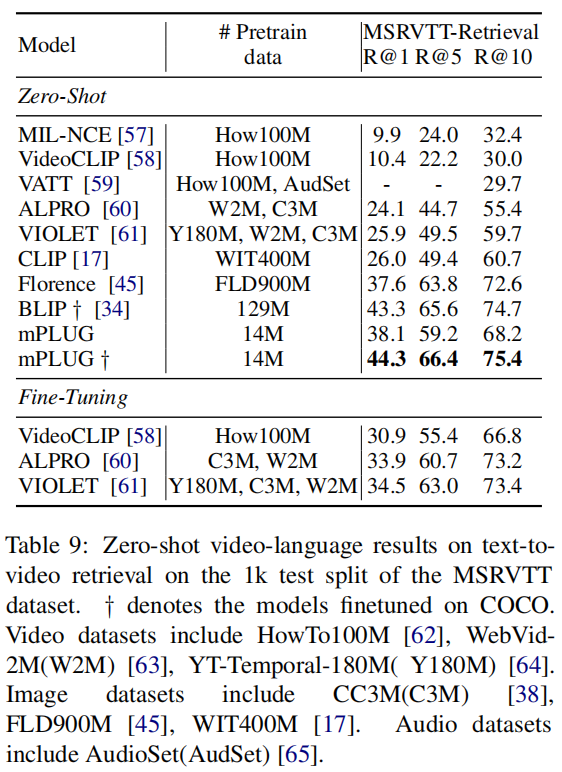
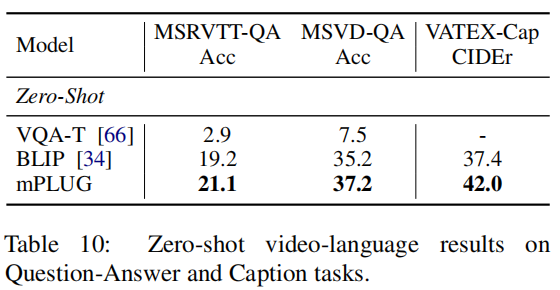
除了图像以外,作者还尝试将mPLUG应用在视频上,作者同样Follow了BLIP的处理方式,均匀地从视频里选取了N帧,并将其组合成单个序列来进行预测。在Video-text检索任务上,作者列出了Zero-shot和在COCO微调后的结果,可以发现,mPLUG在不利用时序信息的情况下,仍然超过了大部分用视频数据集预训练的模型。在VQA任务上,作者也是使用生成式来处理,对比下来也更好。在Caption任务上,作者使用了A video of的前缀,对比下来也比BLIP好。然而假如与其他Video Captioning的模型相比,这个效果非常差。
开源情况
作者开源了base(350M)、Large(600M)两个模型,Huge(1.1B)模型说coming soon。
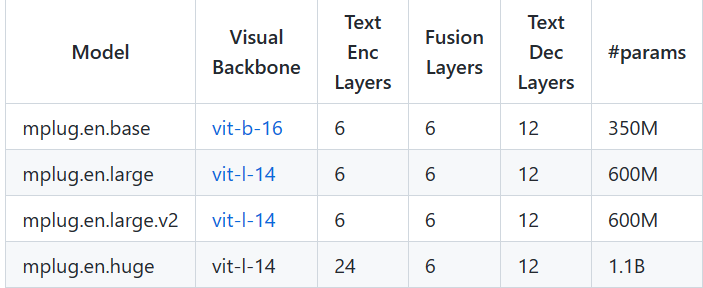
作者开源了fine-tune的脚本,没有开源预训练的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!