论文笔记 X-VLM Multi-Grained Vision Language Pre-Training Aligning Texts with Visual Concepts
本文最后更新于:2023年1月29日 下午
论文笔记 X-VLM Multi-Grained Vision Language Pre-Training Aligning Texts with Visual Concepts
论文链接:Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts (arxiv.org)
代码开源:zengyan-97/X-VLM: X-VLM: Multi-Grained Vision Language Pre-Training (ICML 2022) (github.com)
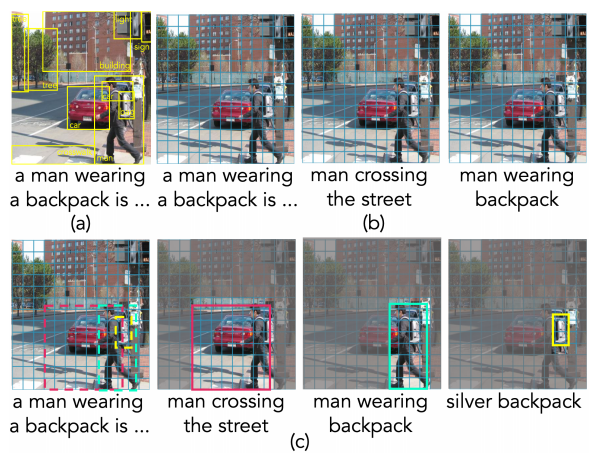
来自字节跳动的发布于ICML2022上的一个多模态的视觉-语言预训练模型:X-VLM,其将图像中的视觉概念与文本以不同粒度关联起来,如图1,其他方法要不然就像(a)那样依赖于目标检测模型,要不然就像(b)那样将文本与整副图像关联,而X-VLM则是©这样将不同文本关联到图像的不同位置上,并且不需要预训练的目标检测模型。
模型架构
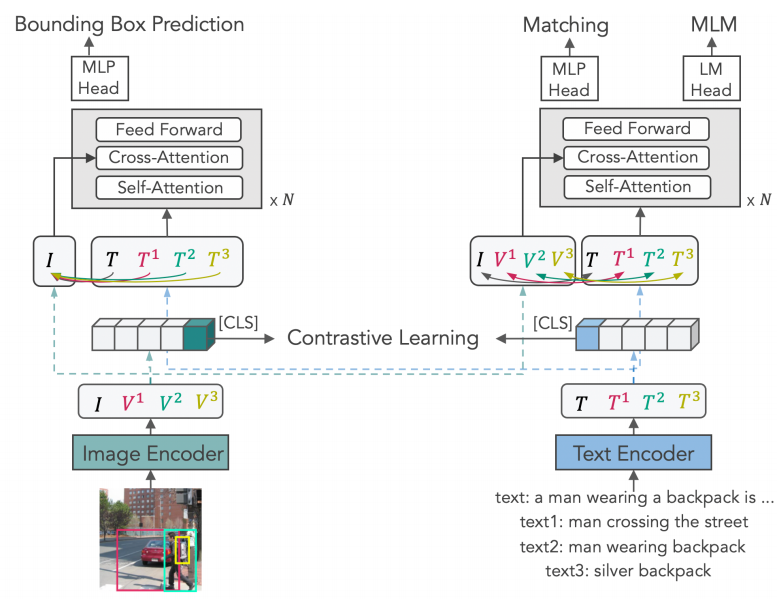
如图,X-VLM由一个Image Encoder、一个Text Encoder和一个Cross-modal Encoder组成,其中Image Encoder提取图像的整体特征()和其中概念的局部特征(),Text Encoder提取对应的文本特征()。
首先,得到的这些特征先像CLIP一样进行对比学习,视觉概念和对应的文本组成对,batch内其他对都是反例。其次,图2左上预测出每个文本对应的Bounding Box作为Bounding Box Prediction任务。最后,图2右上预测一个视觉概念-文本对是否匹配,并进行Mask Language Modeling。
数据处理
一项数据为,包含图像特征和其对应文本特征,以及N个从图像中提取出来的视觉概念特征和对应的文本特征。
Image Encoder
基于ViT,224的图像使用32的patch size能得到49个patch特征(),为了得到某个区域的特征,这些区域的patch将平均池化得到[CLS]的整体特征,同时patch将Reshape成序列的特征,再和'[CLS]'特征组合在一起。最后的特征长度为该区域覆盖的patch数量 + 1。
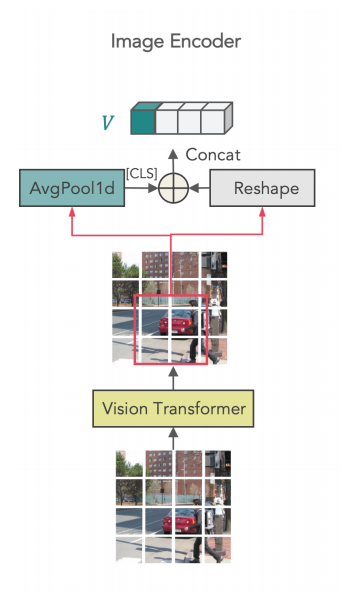
Bounding Box Prediction
一个Transformer的Decoder将图像的整体特征和文本特征进行编码,最后利用[CLS]位置的特征输入MLP再sigmoid归一化后输出box。TransformerDecoder中cross-attend的是图像特征,这里每一个图像都会进行多次预测,因为有多种粒度的概念-文本对。
损失函数则是IOU和常用的L1相加。
Contrastive Learning
使用视觉概念和文本的[CLS]位置的特征,像CLIP那样计算vision-to-text和text-to-vision两个方向的batch损失。
这里仍然由于一个图像会有多个视觉概念,这个batch会更大一些。
Matching Prediction
此处会选择hard negative(困难负样本)的对来进行判断,在对比学习的时候会计算每个视觉概念与所有文本的相似性,选择最高的那个用来预测。假如相似度最高却不是一对,那这个任务就能将其区分开来。
MLM
25%的几率进行mask,其中10%替换成随机token,10%不变,80%为[MASK]。
实验
数据集
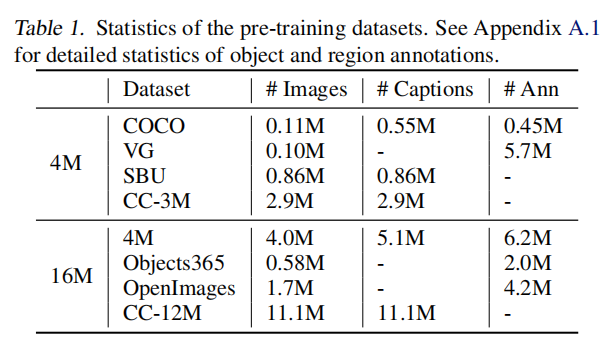
本文制作了4M和16M的两个数据集,如表1所示,4M的数据集从COCO、Visual Genome、SBU Captions和Conceptual Captions四个数据集中混合而来,16M的数据集还添加了Objects365、OpenImages数据集,16M的数据集包含更多噪声的数据。
其中,用来目标检测的VG、Objects365、OpenImages是目标检测数据集,有区域的标注;用来Image Captioning的SBU、CC则有Captions的标注;而COCO两种标注都有。
模型细节
Image Encoder是Swin-Base,Text Encoder是BERT-base的前6层,Cross是BERT-base的后6层,X-VLM总共有215.6M的参数,使用224的输入图片和最大30的文本长度。微调时使用384的图片,通过positional embedding插值适配。
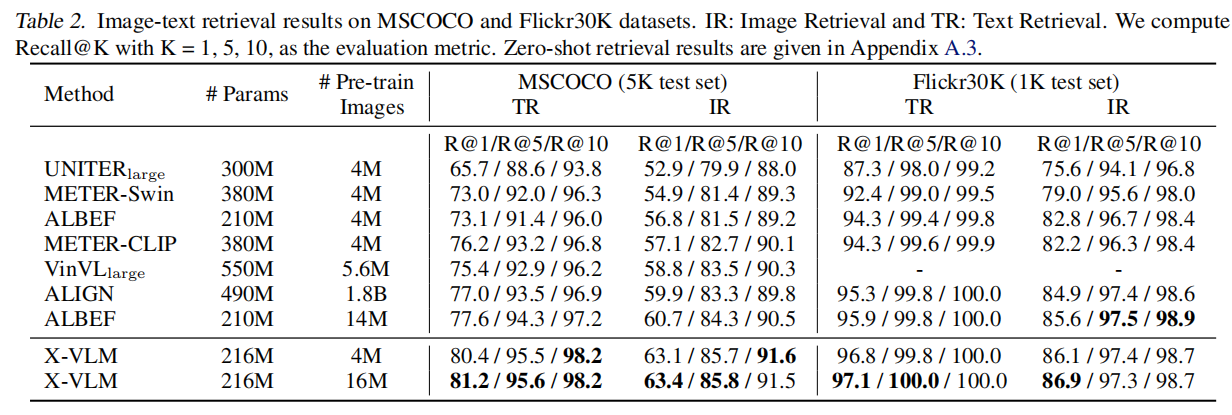
图文检索(跨模态检索)任务实验
本文由于match和对比学习两个可以用来检索的任务,所以预测时先通过对比学习那路计算相似度top-k的candidate,再通过match来计算相似概率来排名。
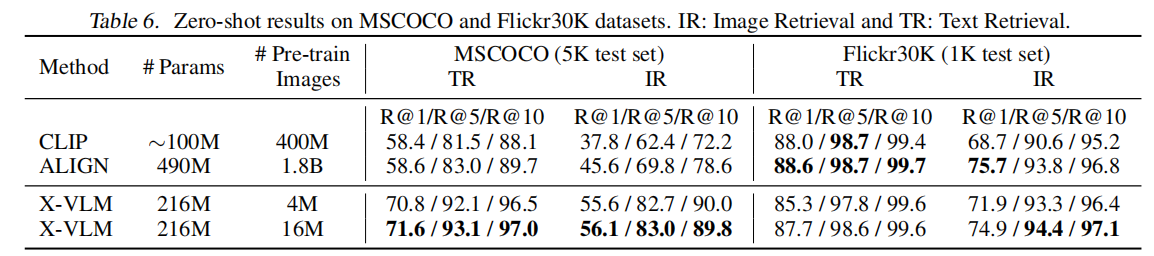
如下表,表2是微调结果,表6是Zero-shot结果。表2上普遍是SOTA,超过了使用目标检测特征的UNITER和VinVL,也超过了将不同粒度文本分配给整个图像的ALIGN、METER、ALBEF。Zero-shot结果也很好。
VQA任务实验
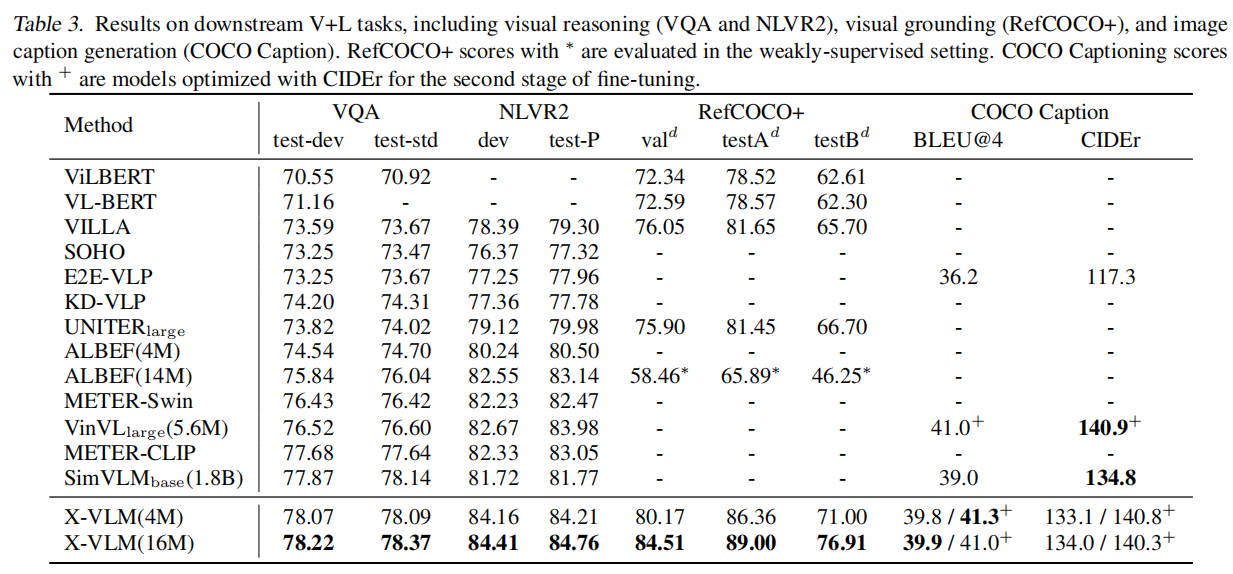
如表3的VQA一栏,本文额外加上6层的Transformer Decoder来生成answer(又加6层???!)
Natural Language for Visual Reasoning
这个任务判断一句话是否能够描述两张图片的关系,本文跟随ALBEF,扩展了cross-modal encoder,给定两个图片和一个文本,模型将文本分配给其中一种图片或者不分配。指标有明显的提升。
Visual Grounding
通过文本描述来定位图中的一块区域。其他方法都是通过RPN网络,而X-VLM直接有对应的任务。指标有明显的提升。
Image Captioning
图像描述任务,将MLM改成Language Modeling loss就可以训练了。
虽然表中没有比较,但是和GIT模型在相同参数时差不多,GIT在扩展了参数量和数据量之后效果更好。
消融实验
如表4所示,在去掉object后,除了Visual Grounding任务都出现了下降,去掉region下降的则更多。Bounding box Prediction是这个模型非常重要的一部分,去掉之后虽然数据不变但是性能下降很多。

可视化
利用Grad-CAM和Bounding Box Prediction任务,可以进行一定的可视化,结果如下:


本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!