《知识增强的预训练语言模型》论文简单翻译
本文最后更新于:2023年1月7日 晚上
《知识增强的预训练语言模型》论文简单翻译
论文链接:A Survey on Knowledge-Enhanced Pre-trained Language Models (arxiv.org)
简简单单翻译这篇论文,可能有错误,仅供参考。原文第五章Evaluating KEPLMs由于兴趣不足没有翻译。参考文献的序号并没有全部标上,详细可以看原文。
介绍
预训练语言模型(PLM)指的是先在一个大数据集上训练,然后直接迁移到下游任务或者进一步在小数据集上微调的NLP模型。早期的PLM如Skip-Gram、GloVe是浅神经网络,他们从窗口上下文(window-sized context)中学习到的词嵌入是静态的向量,无法处理动态环境中的一词多义。随着深度学习的发展,研究者尝试深度学习+动态语义嵌入的方式来提升:最开始限制于监督学习,没有发挥深度学习充分的潜力;然后随着自监督模型如BERT的出现,大预言模型能够从大规模无标签的文本中通过预测被mask掉的token的方式学到许多知识,从而在NLP取得了突破。自此,许多使用Transformer+自监督来解决NLP问题的方法被提出,逐渐PLM进入了快速发展阶段,最新的现象级的成果就是OpenAI的ChatGPT。
虽然研究取得了进步,但是PLM仍然具有较弱的可解释性、健壮性和推理能力:PLM就像黑盒一样难以解释;PLM可能遭到对抗攻击,健壮性不够;还有就是PLM完全是数据驱动的,限制了推理能力。以上这些缺陷可以通过知识增强的预训练语言模型(Knowledge-Enhanced Pre-trained Language Models, KEPLMs)来改进。
虽然已经有一些KEPLM的综述,但是这个领域发展很快,本文旨在提供综合、最新、多角度的综述。
本文第二章介绍KEPLM的背景,第三章介绍常用的知识种类和格式,第四章介绍构建KEPLM的多种方法,第五章介绍可能的衡量指标,第六章介绍在要用到许多知识的下游任务中的应用,第七章介绍未来研究方向,最后一章总结。
背景
这一章先介绍PLM的概念,然后介绍最近PLM+Knowledge的趋势。
PLM
2013年word2vec开启了PLM的时代。第一代PLM有Skip-Gram、GloVe,它们企图直接从下游任务中获得词嵌入,由于算力问题,并且它们的模型架构通常都比较简单。第二代PLM如基于LSTM的CoVe[53]和ELMo[54]还有BERT和GPT,专注于通过动态上下文来得到词嵌入。这一时期Transformer成为了NLP领域的热点,几乎所有明显的突破都使用了它。现今,PLM通常指Transformer架构的模型,在预训练-微调的范式下的模型。典型的PLM包括GPT(Transformer的解码器)、BERT(编码器)、BART(解码器和编码器)。最近,prompt learning,一个NLP中的新范式,正在变得火热[57],它可以更好地使用PLM的知识,并给予PLM在few-shot和zero-shot这些困难场景下的能力。
Knowledge+PLM
在Knowledge和PLM的结合中,有两条研究线路:第一条是将PLM作为知识库(Knowledge Bases, KB),第二条是通过知识来增强PLM。本文更着重后者。
将PLM作为知识库
知识库(如Wikidata和ATOMIC等)储存了实体和实体间关系,通常以关系三元组的形式呈现。PLM则是相较于结构化知识库而言的一种替代。从LAMA[59]开始,许多研究者探索了PLM能否当做结构化知识库。文献[60]探索了如何使用PLM自动构建结构化知识库,文献[61]探索了神经网络中准确度和内存容量的关系,论证了PLM可以被用作知识库。文献[62]说关系化知识库可以更正确地表示知识,但是缺乏灵活性。作为对比,文献[63]探索了PLM和知识库各自的优缺点,他们相信具有显性知识的知识库无法完全被具有隐性知识的PLM代替。文献[64]发现closed-book问答对于生成模型来说还是一个挑战,所以生成模型并不适合作为KB。文献[65]认为PLM要在5个方面表现好才能作为知识库,并且5个中有3个方面知识库比PLM更好。
通过知识来增强PLM
另一方面,我们可以通过知识来增强或者扩展PLM。在许多要用到知识的下游任务中(比如QA任务),增加PLM的参数量可以提升其学到的知识。然而,增加参数来学习知识的操作的效率并不是那么高,比不上直接结合知识。所以,研究如何将知识嵌入PLM中是一个需要研究的方向。
如ERNIE[67]、KnowBert[68]、K-BERT[69]的方法是早期通过知识来增强PLM的方法,他们在要用到知识的下游任务中取得了成功。许多接下来的模型受其启发,现今,更多的KEPLM正在出现,通过不同的方法结合各种知识,并在各种任务上进行尝试。
KEPLM的知识来源
这一章对要融合进PLM的知识的种类和格式进行叙述。
知识的种类
分成五类分类叙述:语言学知识、语义知识、常识知识、百科知识、特定领域内知识。
语言学知识
- Part-of-Speech Tags:常用的tag包括名词、动词、副词等,这个可以帮助理解自然语言。在语义情感分析中,SentiLARE[70]就使用了这方面知识。
- 句法结构:通过句法分析获得句子的结构知识,比如单词间的依赖和支持。Syntax-BERT[71]使用了这方面知识,构建了句法树。K-Adapter[72]结合了依赖解析信息(dependency parsing information),提升了依赖关系预测任务。
- 跨语言迁移性:PLM可以通过多语言语料学习到多语言的迁移能力,XLM-K[73]证明了一个语言的语言学知识可以帮助其他语言的学习。
语义知识
语义知识旨在帮助模型理解文本的含义,比如KT-NET[74]、SenseBERT[75]、LIBERT[76]引入了WordNet的语义知识,分别在机器阅读理解、缩句、多义词分析(word sense disambiguation)取得进展。文献[78]将句法树通过VerbNet转换成了对应的语义,从而模型能够理解文本。SemBERT[80]通过语义角色标签来获取语义知识,从而改进阅读理解和语言推理的效果。
常识知识
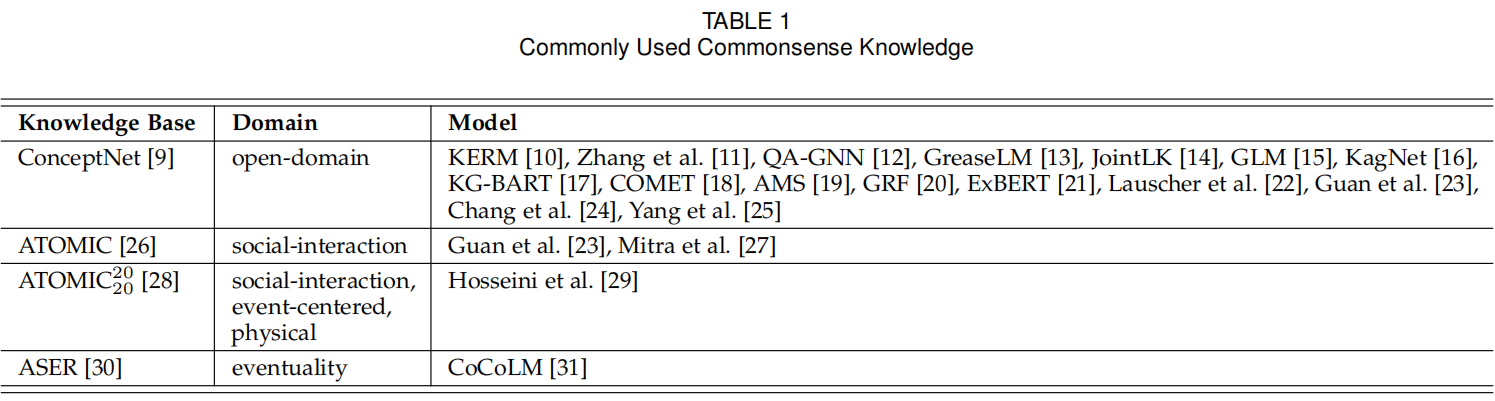
常识指的是日常人们每天关于世界和活动的知识[81],常用的常识知识库如图1。常识在知识库中使用三元组表示,其节点更多为短语而非单词,与百科知识不同。举例来说,一个三元组可能是*having no food, CauseDesire, go to a store,而一个百科知识可能是China, capital, Beijing。
表1所示,ConceptNet是最常用的开源常识库,其包含34种关系,比如RelatedTo、IsA等,在QA、常识验证、常识故事生成任务中常用。ATOMIC则是一种基于if-then的推理关系,比如if X pays Y a compliment, then Y will likely return the compliment,包含了causes vs. effects,
agents vs. themes, voluntary vs. involuntary events, and actions vs. mental states(啥?不会翻译了)。这在常识推理、常识QA任务中比较有用,如文献[23]和[27]。ATOMIC包含了更准确更多样的常识,包括社交、物理和一些以某事件为中心的类别。文献[29]将其中的三元组转换成自然语言来预训练,提升了因果分类和常识QA任务的效果。ASER是大规模eventuality的知识图谱,事件作为节点,语句关系作为边,比如一个因果关系的两个节点:Jim yells at Bob、Bob is upset。
百科知识
百科知识包括了公开范围的广泛的信息,以文本或者三元组的形式存在。Wikipedia是一个多语言的非结构化的百科,BERT就使用了其作为预训练数据来学习,而其他方法通常利用三元组形式的百科知识。
Wikidata是百科知识中的最广泛使用的知识图谱,一些KEPLM(K-Adapter、ERNIE、KgPLM、ERICA)就使用了Wikidata作为知识来源。其他常用的英文百科知识图谱包括Freebase、DBpedia、NELL。CN-DBpedia则是一个常用的中文百科知识图谱。用在中文的下游任务的KEPLM有K-BERT[69],其就使用了CN-DBpedia。
Wikidata5M是KEPLER提出的一个大规模知识图谱,其不仅包含三元组,还包含实体和关系的高质量描述,KEPLER自己利用这些描述来初始化knowledge mebedding,CoLAKE同样也使用了这个方法。
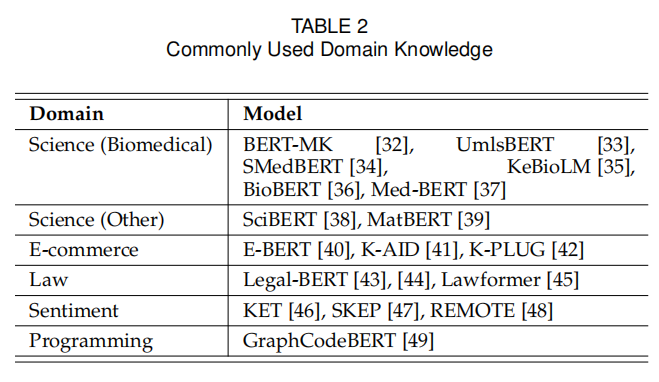
特定领域内知识
相较于百科知识,特定领域内的知识更具体,比如医学、电商等领域,如表2总结。
生物医学的知识通常用症状或者疾病的三元组表示,比如bacterial pneumonia, with associated morphology, inflammation。电商领域的知识则是由商品名称组成,它们的描述用一系列短语构成。比如iPhone XS is described as iOS; 4G signal; T-Mobile service; OLED screen; ...。
知识格式
总共有四种常用的格式:实体词典、知识图谱、纯文本、有标签的图像。
实体词典
为了将实体中的知识融入,我们需要将实体的知识嵌入集成到对齐的token嵌入中。现有模型通过两种方法来初始化实体的嵌入,第一种是通过传统的知识嵌入算法(比如TransE,文献ERNIE和CokeBERT使用),第二种是通过编码实体的描述(文献KEPLER)。
第一种方式能够融合邻居节点,但是要面临heterogeneous embedding space的问题,因为文本的特征空间和知识图谱中实体的特征空间是不一致的。第二种方法在相同空间中融合,但是实体嵌入可能不能完全表示实体的含义。
以实体嵌入的形式注入知识既简单又直观。但是,当知识图谱更新时,实体嵌入需要再训练,并且如果在是在预训练阶段融入的知识,则模型也必须再进行训练。
知识图谱
- 三元组:为了融合三元组形式的知识,可以像K-BERT[69]、ERNIE 3.0[91]、文献[11]和[92]那样将三元组放进文本中合适的位置。或者也可以像文献[93]中融入三元组的嵌入。
- 子图:知识子图是知识图谱的一部分,QA-GNN[12]、GreaseLM[13]、KG-BART[17]和KALA[94]就使用了子图的方法,在4.2.2节中详细介绍
纯文本
为了融合文本格式的知识,我们可以将知识三元组转换成句子作为预训练阶段的语料,或者也可以添加相关的实体定义。常识知识三元组比较适合转换成句子。比如:文献[29]把三元组(PersonX accidentally fell, xEffect, PersonX breaks an arm)转换为 “Tracy accidentally fell. As a result, Tracy breaks an arm.”,然后在预训练阶段将其作为输入。
Dict-BERT[95]还将稀有词汇的定义添加到了文本末尾作为模型的输入,这也令模型在稀有词汇的学习提升了,但是并不适用于多义词。
有标签的图像
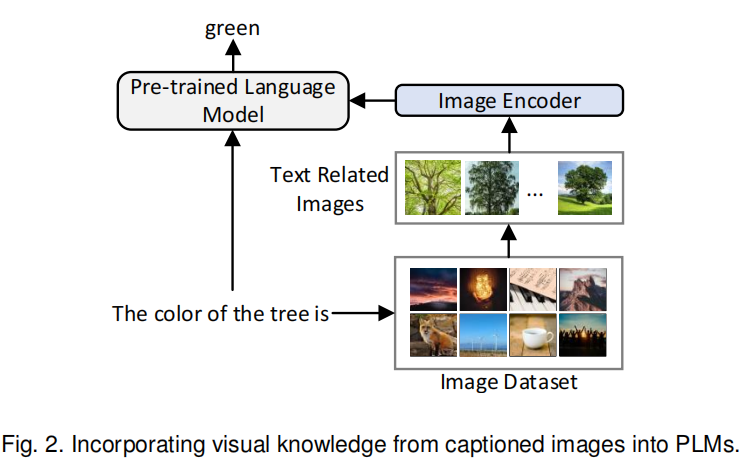
不同于上述形式,视觉上的知识可以通过图片来学到,为了融入视觉知识,模型可以先检索出与上下文有关的图像,然后编码并结合其与文本的嵌入,比如VALM[96](图2)。视觉知识还可以通过图文对齐的训练目标嵌入进,比如Vokenization[97]。
搭建KEPLM
搭建KEPLM可以将外部知识显式、隐式或二者皆有地集成进模型中。
隐式知识集成
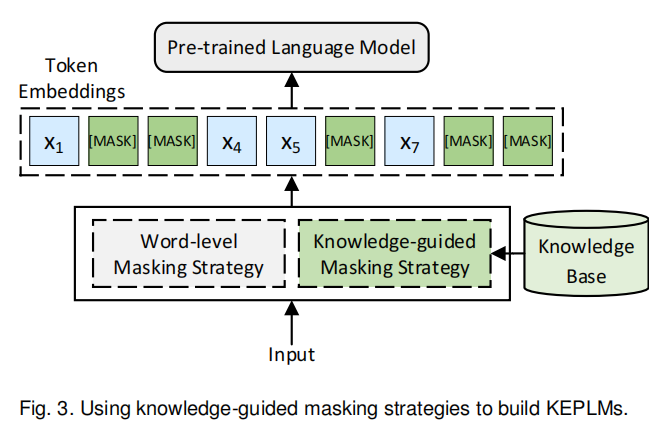
知识引导的Mask策略
BERT类的PLM一般使用如Wikipedia一样的非结构化的文本作为预训练的语料。这些非结构化文本数据包含丰富的上下文语义信息,BERT可以通过Masked Language Modelling(MLM)从中学到词汇的上下文知识。然而,文本中实体和短语所包含的宝贵信息却被忽略了。通过采用知识引导的Mask策略而非对单个单词的Mask策略,PLM能够学到更多关于短语和实体的知识。如图3。
ERNIE模型就在BERT的基础上添加了实体级别和短语级别的mask策略,并以此引导了BERT在与徐娜林中学到更多知识。SKEP提出了mask情感词汇的方法,可以注入情感知识。
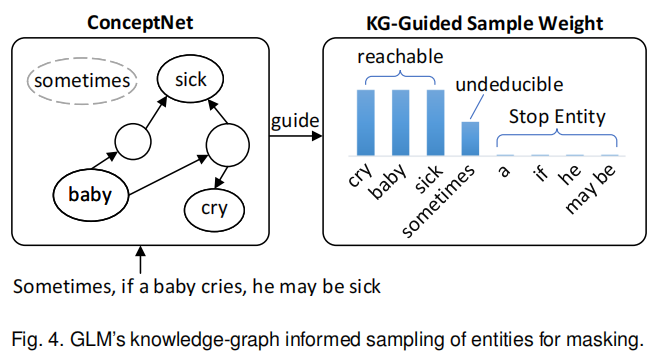
与ERNIE和SKEP不同,GLM使用了知识图谱来分配给重要实体更高的mask权重。具体来说,GLM以20%的概率mask普通词汇,80%的概率mask一个实体。当GLM需要mask实体时,那些可以在ConceptNet中通过一定跳数通向其他实体的实体将会被认为是更重要的实体,并且会以更高的概率进行mask。如图4,左边这4个实体中,sick、baby、cry可以互相连通,但sometimes不能,所以会像右边这样分配概率。
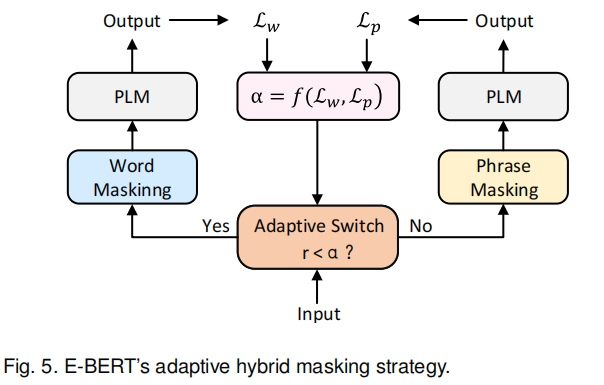
与其使用一个预定义的概率,E-BERT[40]还提出了一种自适应的mask策略,允许模型能够在单词级别和短语级别的mask策略间进行切换。如图5所示,当时进入word masking模式,反之则进入phrase masking模式,是每次迭代随机生成的一个数字。这两种模式在一次迭代中得到的loss会被用来监测word级别和phrase级别的拟合程度,拟合程度用和表示,而表示下一轮两种拟合的相对重要程度,并通过来计算下一轮的。
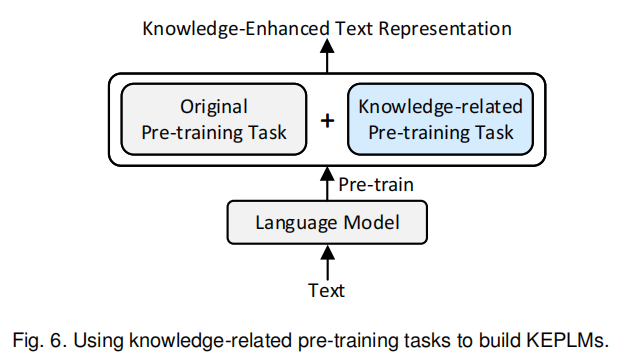
知识关联的预训练任务
有的时候如图6这么弄,添加知识关联的预训练任务。举例来说,KALM[99]在输入序列中添加实体的信号,然后增加一个实体预测的预训练任务,从而帮助模型更好地学习到实体的信息。KEPLER[88]添加了知识嵌入的预训练任务,其与MLM共享同一个Encoder,从而同时获取文本增强的知识嵌入和知识增强的PLM。Vokenization[97]提出了voken的概念,即visualized token,其添加了voken分类任务,预测图像对应的voken,从而用视觉知识增强PLM。
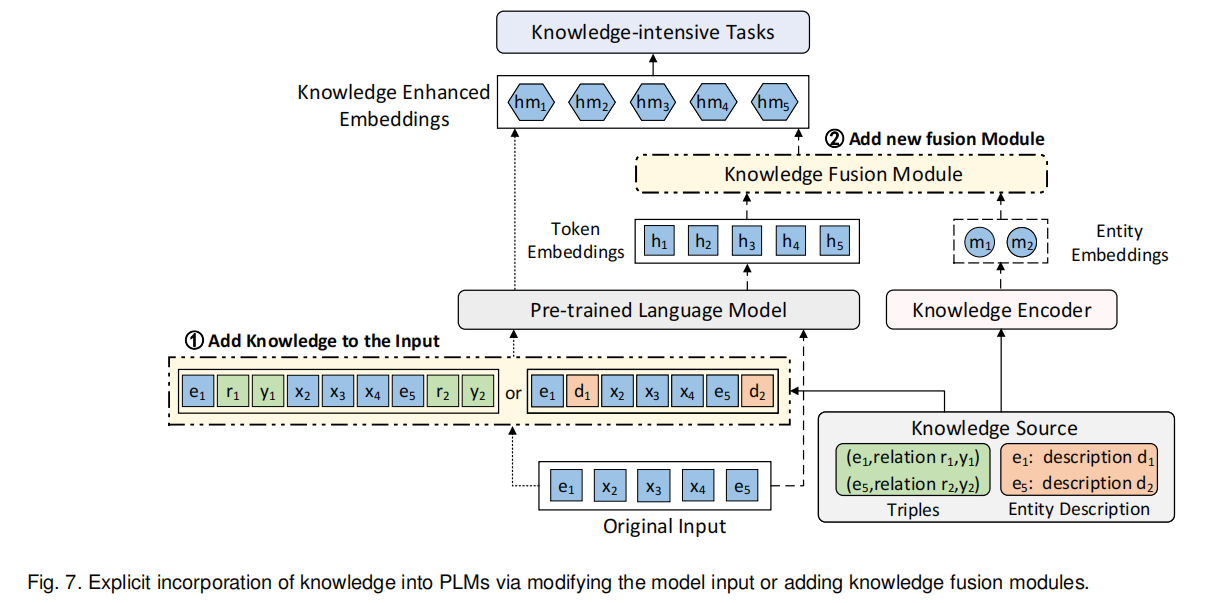
显式知识集成
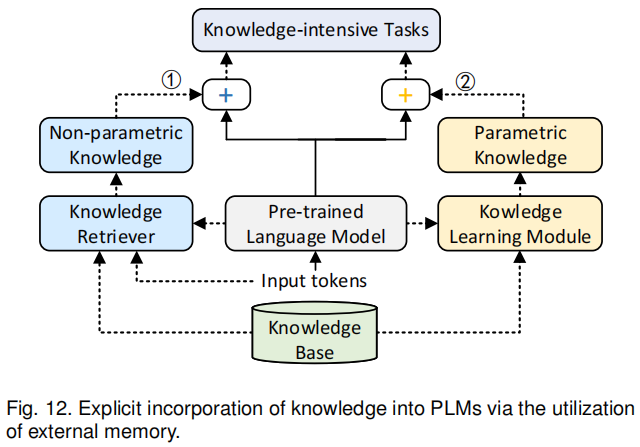
有三种方式来显式集成外界知识:修改模型输入、添加知识融合模块、使用外部记忆。前两种方式以额外的输入或者额外的模块向PLM中插入相关的知识,如图7中的①和②。第三种方式则保持文本和知识空间相互独立,可以促进知识的更新。
修改模型输入
一些KEPLM在预训练阶段插入知识三元组或者实体描述。ERNIE3.0[91]将相关的三元组添加在输入句子的末尾作为扩充的输入。K-BERT则将相关三元组注入每句话中,并生成一个语句树。若输入句子有实体apple,则其将从知识图谱中找到其邻居,并添加进来形成一个新的语句树,一个visible matrix还会被创建来控制知识噪声的级别。文献[11]则在此基础上改进了visible matrix来减知识噪声的引入。CoLAKE[89] 还在输入中引入了三元组,将文本看做是一个全连接的词汇图,并将知识图添加进去,形成一个混合图。其从K-BERT中获得灵感,并一定程度上减小了知识噪声。针对QA任务,文献[92] 将多个和问题有关的三元组通过预定义的模版转换成文本,并与问题和可选回答一起送入模型来训练,这在常识QA中获得了很好的表现。对于以上提到的方法,外部知识的引入可能损害原有的句子结构,所以必须要想办法在此过程中减少知识噪声。
同时也有一些方法以实体的形式融入知识。Dict-BERT[95] 通过Wikitionary获得句子中稀有词汇的定义,并将其添加到句子末尾。相似地,DKPLM[101] 专注于实体的长尾问题,并通过pseudo token来替换长尾实体,pseudo token从相关的三元组中获得。WKLM与这些方法不同,其用相同类型的实体来替换文本中的一些实体,然后模型需要分辨哪些是被替换的。这个方法没有修改模型,只是修改了预训练时的输入数据。
CoLAKE[89] 具体如图8所示,结合知识子图和全连的单词图,获得单词-知识图,然后作为模型新的输入,模型还需要分辨新输入中节点的种类并初始化不同的节点。(?)
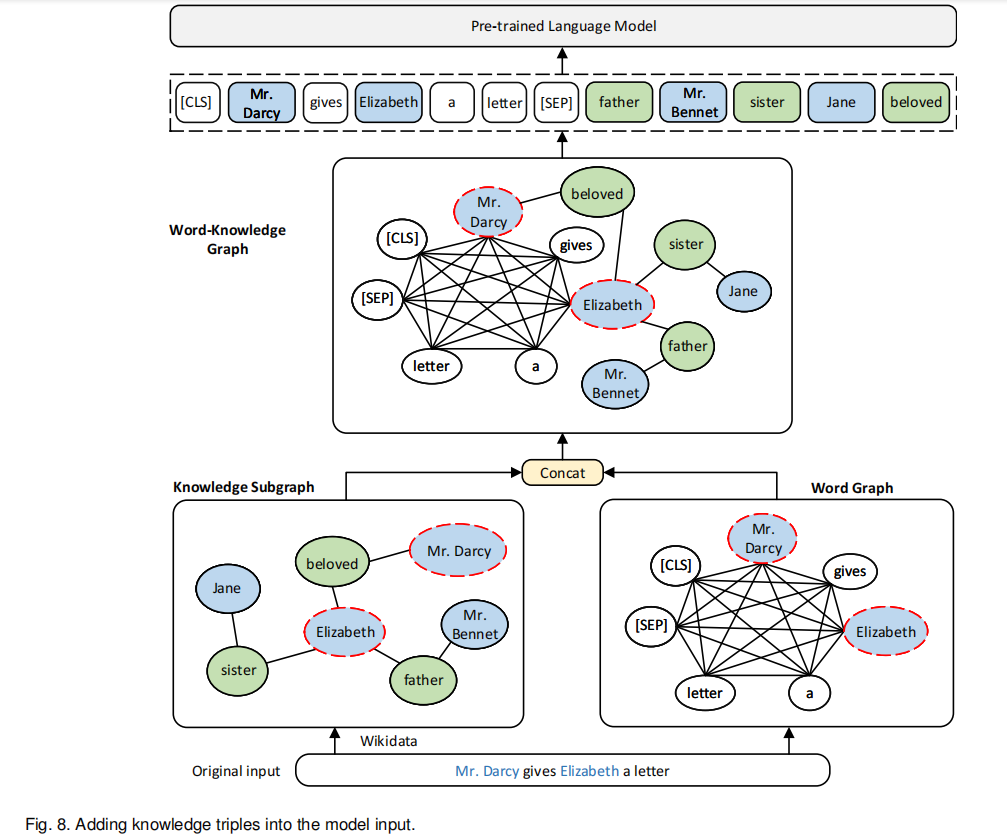
DKPLM[101]提出了长尾实体的概念,表示那些语料中尚未完全被学好的实体。在预训练阶段增强这些长尾实体的学习能够增强模型理解上下文的能力。因此,一个叫做KLT的测量方法被提出,用来测定长尾实体,更低的KLT分数表示更可能是长尾实体。KLT分数通过下式得到:
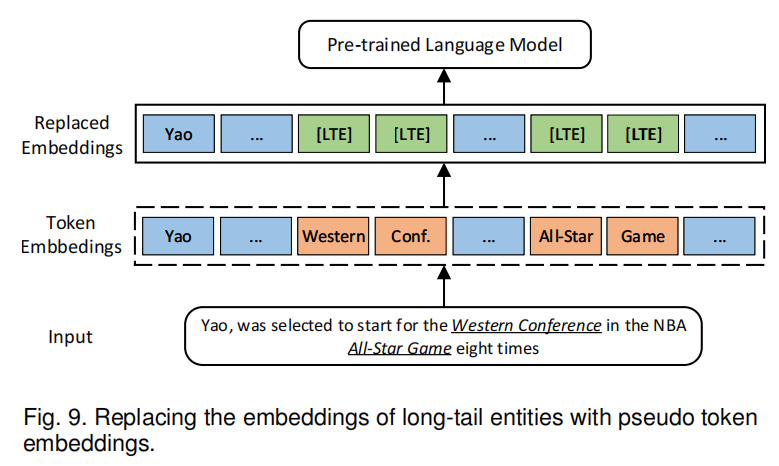
式子是三项相乘,第一项是该词的出现概率,第二项是semantic importance,第三项是知识图谱中的邻居节点。如图9所示,DKPLM替换长尾想来那个的embedding为[LTE],这个embedding叫做pseudo token,其通过知识图谱中的三元组编码得到。
添加知识融合模块
与上一小节不同,这一节的方法都设计了模态空间的融合,文本和知识模态先各自编码,然后通过一个额外的模块来进行融合。如图10所示,知识融合模块通常出现在三个位置:(a)整个PLM的上方 (b)PLM的Transformer层之间 (c)PLM的Transformer层内
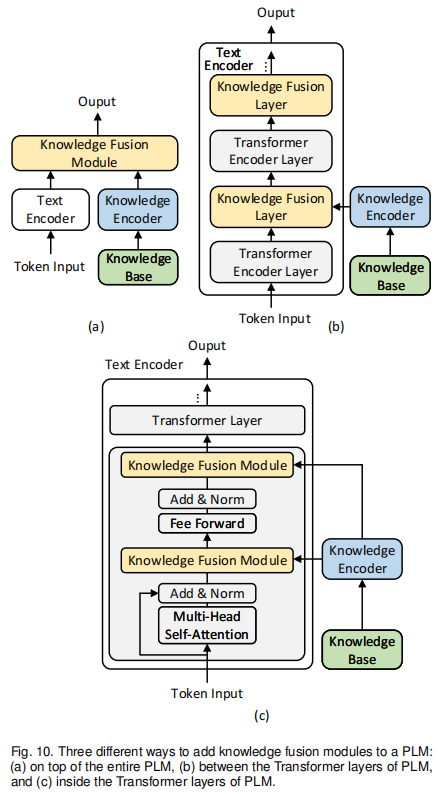
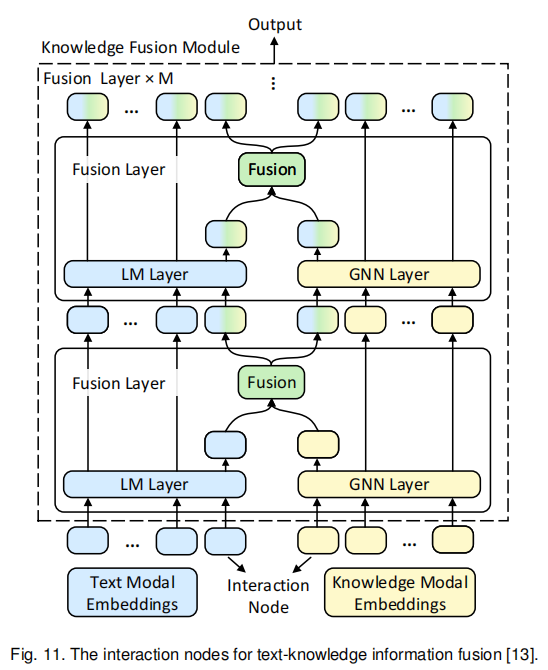
(a)这种方法可以细分成两类,一类是ERNIE为代表的T-K结构,主要以实体嵌入的形式集成知识,T-Encoder用来编码文本语料,K-Encoder用来将实体嵌入编码进文本空间。许多KEPLM使用这种结构,但是区别在于如何获得实体嵌入。ERNIE通过TransE获得单个三元组的嵌入来训练,这种方式不包含相邻节点。BERT-MK[32]则基于此考虑了邻居节点的信息来学习实体嵌入。由于ERNIE方法的嵌入无法根据上下文动态变化,CokeBERT给邻居节点加权,意思更接近的邻居节点获得更多的权重。(a)方法的第二类则是将知识融合的结构附加在PLM后,比如注意力机制。文献[104]就探索使用注意力机制来集成与句子相关的三元组,JointLK[14] 则令问题token和知识图谱节点互相施加注意力。KET[46] 采用了一种分层自注意力机制来集成情感知识到文本中。文献[93]则编码了相关三元组,并通过门控机制进行模态融合。还有其他的方法基于节点的交互进行融合,两个模块的信息通过节点的交互进行融合。QA-GNN[12]通过节点的交互,集成了文本空间的信息到知识空间,在常识QA中取得了好结果。受此启发,GreaseLM[13]设计了两个模态节点的交互,两个模块能分别进行学习,并在融合层进行信息交互,如图11所示。
(b)这类方法则是在Transformer层之间添加知识融合模块,KnowBERT在Transformer的Encoder block之间添加了新的模块来融入知识,它考虑到了ERNIE的一个关于一词多义的问题:对于一个多义词,融入的知识应该根据其在上下文中的具体含义来。KG-BERT在Encoder和Decoder的层之间添加了知识融合层来融入知识子图的知识,这个过程使用了多头图注意力机制。JAKET[105]将PLM分成前6层和后6层,前6层先得到文本的hidden表示,然后实体也同样用6层得到embedding,之后在文本中将实体的embedding加上,再作为输入进行后6层的学习。
(c)这类方法则是在Transformer层中间添加融合模块。KALA就是一个例子,受到了modulation的启发,即使用知识空间的知识来调制文本空间的embedding。
添加知识融合模块是很符合直觉的,并且融入的知识主要是实体的特征,一些方法还考虑实体在知识图谱中的上下文,比如BERT-MK,还有一些方法基于文本的上线爱问来过滤实体的邻居节点,比如CokeBERT。
使用外部记忆模块
使用外部记忆模块是搭建KEPLM的第三种方法,其使用了外部记忆来将知识空间与文本空间分离。
如图12,①表示从外部记忆中将非参数化的知识应用在下游任务的方法。KGLM[106] 从相关的知识图谱中选择一些事实来生成事实语句,也就是说它用知识库来扩充词汇量,补充模型没见过的知识。REALM[107] 则引入了知识检索模块来帮助模型检索和处理知识语料中的文本,从而改进在开放域QA的表现。如果知识变化了,它仅需要更新知识语料库而不用重新训练模型。
②则是使用一个额外的模块来学习参数化知识的方法。K-Adapter[72] 添加了用来学习参数化知识的adapter,PLM本身的参数在预训练中保持不变。这些adapter相互独立并且平行训练,当需要时,也可加入更多的adapter。
RAG[108]结合了上面两种方法,在开放域QA任务中带来了更好的效果,并且对于文本生成,它也能生成更具体、更多样、更具备事实的文本。文献[109] 还在RAG的基础上天极爱了一个记忆力模块来提升效果。
当知识库发生变化时,使用外部记忆模块的方法就有更大的优势,更符合实际应用。
评估KEPLM
这块兴趣不是很大就不翻译了。
应用KEPLM
KEPLM可以在知识密集的下游任务中大大提升效果,这些任务可以一句是否有新自然语言的生成而分成两类。
知识增强的NLU
使用Transformer的编码器或者编解码器构成的KEPLM可以用作NLU(natural language understanding)任务,比如实体分类、实体识别、关系提取、情感分析、问答、基于语言的推理和知识图谱补全。
实体分类
已知实体提示和其上下文,实体分类需要模型能够得出其语义类型。FIGER[122]和Open Entity[123]是最常用的数据集。我们发现CoLAKE、KnowBERT、KEPLER、DKPLM、LUKE至在Open Entity上测试。ERICA只在FIGER上测试。ERNIE、CokeBERT、K-Adapter在两个数据集上测试过。Open Entity更广泛,原因如下:FIGER的训练集通过远程指导标注,测试集则是人工标注,Open Entity则都是人工标注,并且有更多种类更细粒度。除此以外,BERT-MK还在医学领域进行此任务,使用了2010 i2b2/VA、JNLPBA、BC5CDR数据集。
大部分上述提到的方法在需要分类的实体前后添加特殊标记,比如he had a differential diagnosis of [E] asystole [/E],然后用[E]来预测实体种类。
文献[128]提出了一个新的数据集WikiWiki,包含10M Wikipedia文章,其中每个实体都连接到了Wikidata的知识图谱。与现有数据集对比,WikiWiki更大更准确。
实体识别
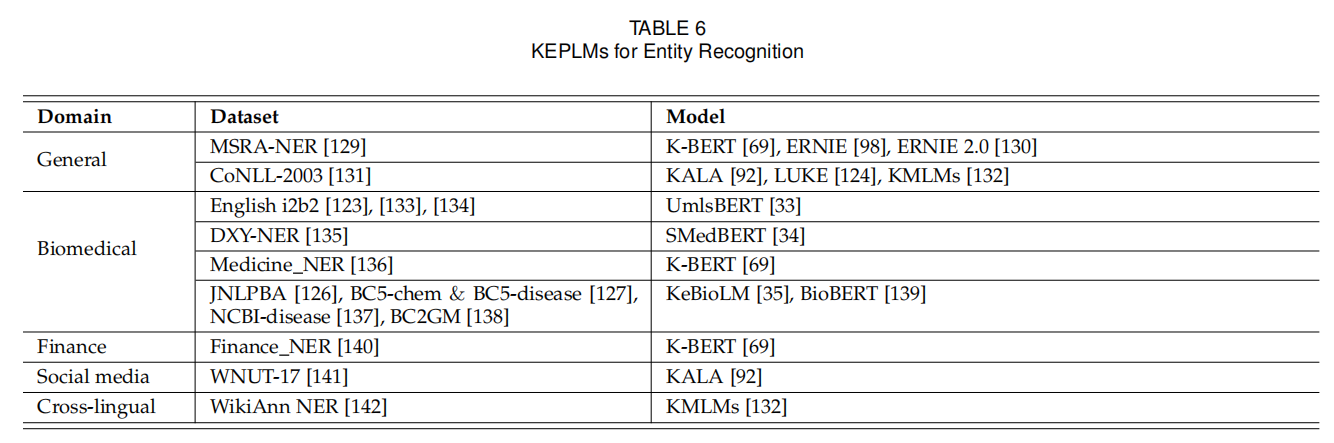
即NER任务(Named Entity Recognition),需要模型识别出文本中实体的种类。和实体分类一样列在表6。
关系提取
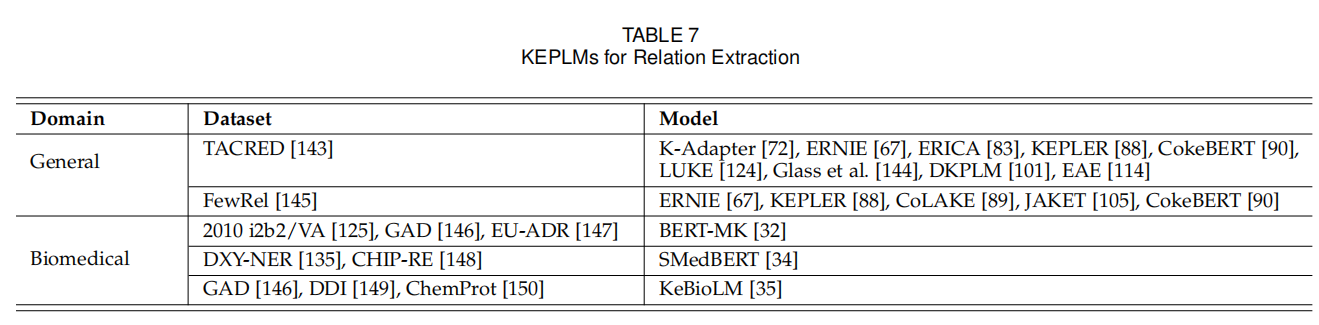
KEPLM可以帮助提升文本间实体关系提取。除了公共领域,这个任务更常见于生物医学领域。如表7所示,最常用的通用数据集是TACRED[143]和FewRel[145],尤其是前者更常用。我们发现用了这两个数据集的方法在FewRel上表现都比TACRED好,所以TACRED是一个更难的数据集。有许多工作专门为生物医学领域设计,与NER一样,这个任务可以帮助模型了解某个特别领域的知识。
情感分析
有两种情感分析任务,第一是句子级别的,第二是aspect级别的。句子级别的情感分析需要模型分辨一句话的情感倾向,通常用的数据集有Stanford Sentiment Treebank SST-2[151] 和Amazon-2[152]。aspect级别的情感分析需要模型分析上下文的不同方面(注:aspect是评论的对象实体属性,如在餐厅评论中,一个方面可以是食品的价格,质量等),通常用的数据集有SemEval-2014 Task 4[153]。
SentiLARE、SKEP通过融入知识比普通的PLM在两个方向上的表现都更好。通过情感分析,REMOTE[48]可以检测仇恨语言,KET[46]可以检测对话的情感,帮助QA机器人更好的回应。
问答
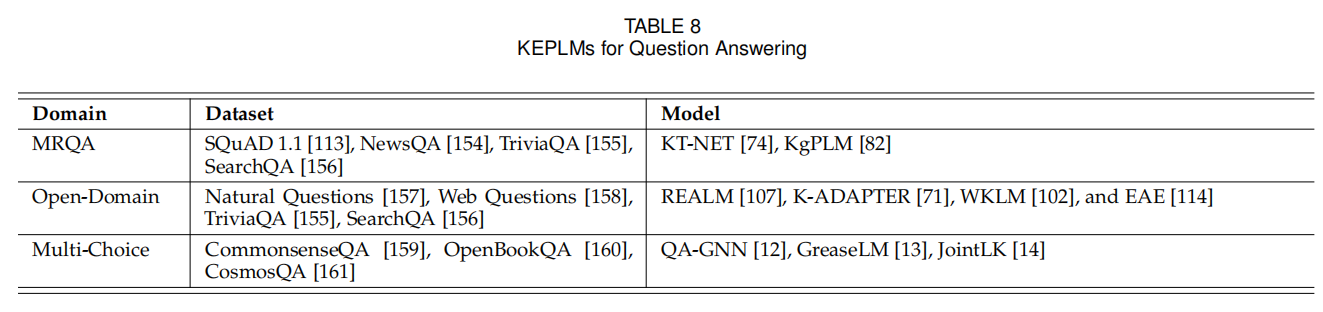
问答包括阅读理解(MRQA)、开放域QA、多选QA。表8中MRQA提供了问题和关联的文章,模型需要从文章中得到答案,最常用数据集是SQuAD1.1 [113]。开放域QA则没有关联的文章,需要模型自行检索相关文章。REALM、K-Adapter、WKLM、EAE在融入百科知识后比一半的模型表现更好。多选QA需要模型在多个选项中根据问题选出正确的选项。表8列出了三个数据集。开放域QA和MRQA的数据集有重合,因为去掉文章就可以变成开放域的。
基于语言的推理
典型的模型有SMedBERT、文献[162](自然语言推理)、KMLM、文献[163](数学推理)、文献[24](常识推理)、Vokenization(常识推理)、CoCoLM(时间时序推理)、VALM(物体颜色大小推理)
知识图谱补全
知识图谱经常遇到不完整的问题,实体间的许多关系可能缺失。KEPLM可以帮助推理这些链接。GLM这类模型比基于翻译的图嵌入模型和图卷积网络表现更好。
知识增强的NLG
NLG指自然语言生成,基于Transformer解码器或者编解码器的KEPLM可以用来进行NLG,比如句子生成、对话生成、问题生成和回答生成。
句子生成
句子生成任务要求模型生成合理的句子,常用数据集有CommonGen、ROCStories。前者需要模型根据3-5个概念生成合适的关联句子,KG-BART模型通过结合常识知识子图进行此任务,GRF、[171]、[23]则能够借助常识生成合理的故事结局。
对话生成
对话生成需要模型根据上下文生成回应。KnowledGPT在Wizard和CMU_DoG数据集上实验。Wizard数据集有广泛的主题,CMU_DoG只专注于电影领域。
问题生成
这个任务需要模型根据回答生成问题,RAG提出了Jeopardy Question Genration任务,Jeopardy指模型要根据提供的事实来猜测出一个实体。
回答生成
与QA不同,回答生成需要模型自己生成,而不是从选项或者文章中找到答案。RAG只使用MSMARCO NLGT taskv2.1,把这个任务当做开放域抽象QA任务并超越了BART。
未来方向
-
利用更多种类的知识
如第三章所示,现有的KEPLM考虑使用多方面的知识,但是还有很多其他的知识值得利用,比如HyTE这样的时序知识图谱,其包含能够反映各个实体间关系随着时间的变化的事件,若利用上这个只是,PLM可以帮助与时间有关的推理任务。并且随着ChatGPE的现象级成功,它证明了使用Reinforcement Learning from Human Feedback来融入人类意图和偏好的威力。
-
提升知识融合的有效性(Effectiveness)
如第四章所述,许多融入知识的方法已经提取,像KEPLER和Coke-BERT这些方法依赖于精密的多任务预训练和知识图谱嵌入。然而KEPLER在实体分类和关系预测任务中比只有实体级别知识的LUKE更差,CokeBERT也只好一点点。这些说明他们的效率比不上LUKE。文献[178]提出了图卷积Simulator来检测融入PLMd知识。他们对于ERNIE和K-Adapter的调查显示这些KEPLM只融入了知识的一小部分。
-
提升知识融合的效率(Efficiency)
现有的KEPLM都在刷榜,很少注意知识融入的成本。我们需要更节约时间和空间的解决方案。比如CoLAKE和ERNIE这些方法,在预训练阶段进行知识融合,比如K-BERT和K-Adapter和Syntax-BERT这些方法在微调阶段进行知识融合。在预训练阶段的融合成本更高但效果更好,需要减少预训练的知识融入消耗并维持好效果。
并且,知识融合可能提升推理时间,比如GRF和KG-BART包含了知识图谱子图的构建,造成了更长的推理时间。要应用的话,KEPLM要减少推理时间。
额外的空间占用也是部署上的一个问题,FaE[179]模型需要外部的包含了百万级别的知识三元组实体记忆和事实记忆。RAG依赖于千万级别的知识语料库。然而并不是所有都有用,所以挑选并存储哪些最重要的外部知识可以显著减少空间的过度消耗。
为了减少融入更不重要的知识,模型压缩技巧[180]可以起到帮助,比如quantization[181]、知识蒸馏[182]和参数共享[183]可以用上。
-
探索更多知识密集型任务
比起第六章所说的NLP下游任务,一些其他更少被探索的应用可能也能对KEPLM起到帮助,比如KEPLM可以用来提升机器翻译和文本总结的评估。
-
建立一个统一的KEPLM
大多数KEPLM被设计为专门的几个任务。为了在不同的任务上取得SOTA,经常是需要为每一个任务训练不同的模型,要是有一个统一的预训练KEPLM就更好。KGI是一个早期的尝试。
-
进行Zero/Few-shot学习
一些任务没有高质量的标注数据,所以Zero/Few-shot学习很重要,借助KEPLM中的知识,其比普通PLM更有可能克服这个问题。KALM[99]标记了输入的实体,极大提升了zero-shot QA任务,[128]引入了细粒度的实体种类,也在zero-shot对话追踪中获得了好效果。除了整合知识,prompt也有用[185-188],结合其与KEPLM也是一个有趣的方向。
-
提升鲁棒性和可解释性
可解释性指的是人能够理解模型的输出和预测。[189]调查了融入外部知识能否帮助解释自然语言推理任务。他们论证了自动评估方法和人工评分间仍存间隙,自动评估的有效性需要注意。[190]尝试依靠模型输出来追踪到其训练数据。[191]和[192]另一方面尝试定位模型中的只是。模型的鲁棒性指的是遇到有毒的知识和对抗攻击时模型的抵抗能力。[162]通过注意力机制提升了鲁棒性,[144]通过研究模型在不同数据集上的自适应能力来说明鲁棒性。现有方法在这方面还有欠缺。
结论
略
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!