Generative Cooperative Learning for Unsupervised Video Anomaly Detection论文笔记
本文最后更新于:2022年9月7日 晚上
Generative Cooperative Learning for Unsupervised Video Anomaly Detection论文笔记
这篇论文是CVPR2022的一篇无监督视频异常检测的文章。视频异常检测没有明确的定义,“异常”可能指暴力行为、爆炸、枪击、逆行等,同时,异常情况出现的概率相较于正常情况较低,数据也很难收集,所以视频异常检测是一个很难的任务。这篇文章提出了Generative Cooperative Learning (GCL) ,其包含一个辨别器 (discriminator) 和一个生成器 (generator,也是一个autoencoder),它们进行合作式的互相学习来实现无监督学习。测试阶段,根据原文的实现,每16帧将会输出一个异常分数。
CVPR 2022 Open Access Repository (thecvf.com)

大致介绍

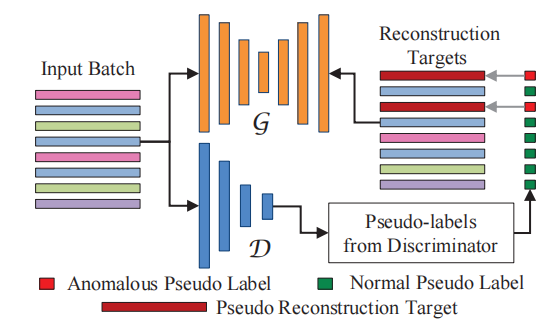
模型整体结构如上图。
输入的无标签视频数据将会分成长度为 的segment,然后使用ResNext3D进行特征提取,得到2048维的向量(不是很清楚这个特征提取模型,好像是提取之后没有时间维度了),随机的segment feature被组合成batch送入模型。
模型包含一个基于Autoencoder的生成器 和一个多层FC的辨别器 。Autoencoder有编码和重构两个阶段,在训练时生成器的目的就是:对于正常数据能够很好地重构,对于异常数据不能很好重构,所以,生成器在计算重构损失时,正常数据应该损失较小,异常数据应该损失较大。生成器的损失通过初始特征和重构特征之间计算MSE得到。在得到batch中每个segment的损失之后,会进行伪标签 的生成,根据之前的假设,设置一个阈值,损失大于阈值的伪标签为异常。注意,此时得到的损失并非最终的损失。
得到伪标签后,这个伪标签将监督辨别器的训练,这个没什么好说的,计算二分类交叉熵损失。在辨别器得到分布后,也会生成伪标签 ,设置一个阈值,概率大于阈值的伪标签为异常。如下图,得到的异常的segment的重构特征将会被替换为另一个“错误的”特征,然后再与输入计算MSE得到生成器的损失。通过如此指定“错误的”特征,能够避免让生成器较好地重构异常数据特征,回应了之前的假设。作者把这个叫做Negative learning。
细节介绍
生成器预训练
为了获得更好的效果,生成器会使用更clean的数据进行预训练。这个更clean的数据的提取比较简单,计算,假如超过阈值了就不使用。
Negative Learning
可以用多种方式替换异常数据的重构特征:(1)全1向量 (2)均匀分布的随机向量 (3)高斯分布的随机向量 (4)不替换。
作者通过下图的实验发现全1更好。

阈值选择
重构特征生成伪标签的阈值:
辨别器生成伪标签的阈值:
预训练的阈值:(这个真的迷惑,好诡异的超参)
本文提出的无监督学习与其他视频异常检测方法的区别
主要根据论文中Related Work进行分析。
-
与One-Class Classification (OCC) 的区别
OCC可见另一个[博客](One Class Classification算法简单介绍 - Kamino’s Blog)的说明。OCC在异常检测领域运用比较广泛,其需要正常的数据,不需异常数据就能进行训练。缺点是很接近正常数据的异常数据也会被well-reconstruction,并且需要的是正常的数据,不能混进异常数据。
-
与Weakly Supervised的区别
WS使用video-level的异常视频标注来训练,从而能够预测frame-level的异常分数。video-level的异常视频并不是说整个视频都是异常的,而是说这个视频中包含异常帧,但是并不知道具体位置。确定是也需要标签。
-
与其他Unsupervised的区别
作者说一些Unsupervised的方法其实是OCC,而本文是可以同时使用正常的和异常的数据进行训练。
结果比较
数据集
本次使用两个数据集,UCF-Crime和ShanghaiTech。两者都是监控摄像头下的视频异常事件数据集,UCF-Crime包含13类事件,总共有128小时,训练集包含810异常视频和800正常视频,测试集包含140异常视频和150正常视频,这个数据集的训练集包含video-level的标注,而测试集还有frame-level的标注。ShanghaiTech包含13个场景下的130中异常事件,训练集由63个异常视频和175个正常视频,测试集包含44个异常视频和155个正常视频。
整体比较

如上图,指的是也和其他OCC任务一样只使用正常数据进行训练,结果比其他方法好很多。

如上图,即使与弱监督学习的方法比较,也是comparable的。(但是这里不是很清楚WS的版本有什么变化)

SOTA了无监督的方法,是baseline,是进行预训练的版本。
消融实验
接下来才是重点,在UCF上进行的消融实验。

如上图,先用AutoEncoder做实验,使用所有数据的AE结果较差,使用标注出来的正常视频训练能达到65.76%AUC,而作者使用的 temporal difference的方法则能接近标注的效果,说明作者的TD方式是有用的。
其次,Negative learning的作用可以从第4、5行证实,Pretrain的作用可以从5、6行证实。
作者最后还发现OCC能够带来更好的效果,也就是说,OCC这种只用正常视频数据进行训练的也应该被看做是一种“监督学习”,而和本文提出的无监督学习应该分开。
可视化


Fig6发现使用了Negative learning的AutoEncoder更能够将红色的异常数据区分开来。Fig8是4个视频的异常分数图,第一个是正常视频,分数都很低,第二个和第三个异常视频都表现不错,而第四个视频在开始和结尾有预测失误,作者说是因为这个视频开头结尾出现了浮动的文字,这在训练集中很少见。
限制
系统是根据已有数据来进行学习的,假如以往都没有异常事件发生,那系统可能把罕见的正常事件当做异常。比如某个机器每三个月要换一次电池,前两个月的数据被用来训练模型,而模型没有见过换电池的数据,所以很容易把换电池看作异常。
没看懂的地方
作者的GCL的Weakly Supervised版本是咋改的???
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!