VideoSSL相关论文(视频分类、动作识别、半监督、自监督)
本文最后更新于:2022年7月21日 下午
VideoSSL相关论文(视频分类、动作识别、半监督、自监督)
总共收录
【1】VideoSSL: Semi-Supervised Learning for Video Classification (WACV2021)
**简介:**半监督视频分类/动作识别任务,进行两路任务,第一路是知识蒸馏,视频通过自己的3DCNN模型然后1000ImageNet分类,视频中随机选一帧通过2DCNN也做1000ImageNet分类,然后两个概率求交叉熵。第二路是伪标签半监督学习,先对有标签的数据进行监督学习,然后生成伪标签,计算伪交叉熵。
无代码
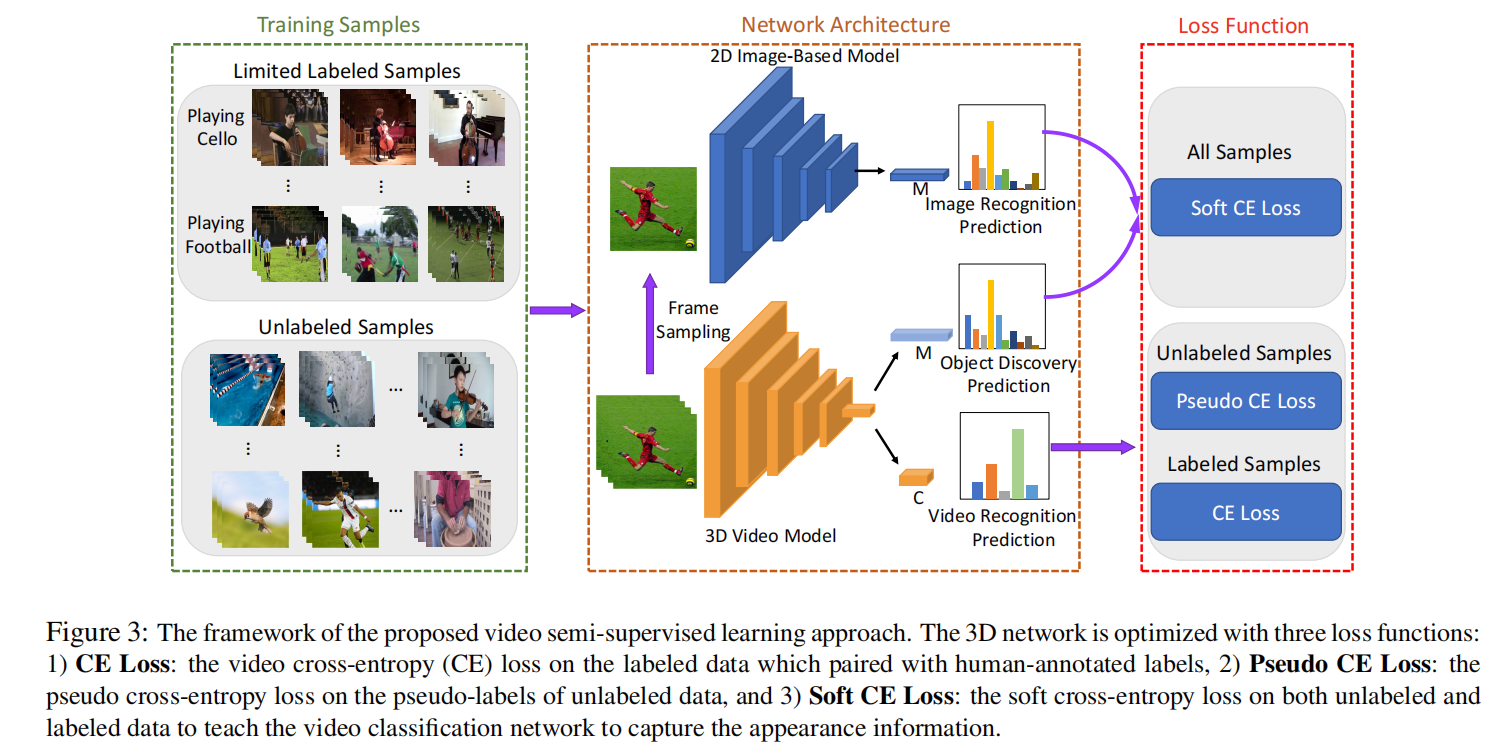
几个loss
所有数据都可以知识蒸馏,是图片分类器,是视频分类器
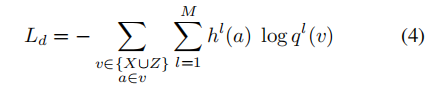
无标签数据,大于阈值的概率,是1,其它保持。
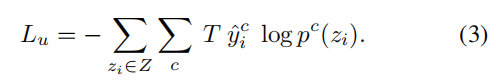
还有一个普通的CE loss。
训练策略
训练的时候,Batch一半是有标签的,一半是无标签的。所有数据计算蒸馏loss,有标签的计算普通CE loss,无标签的计算pseudo CE loss。
效果
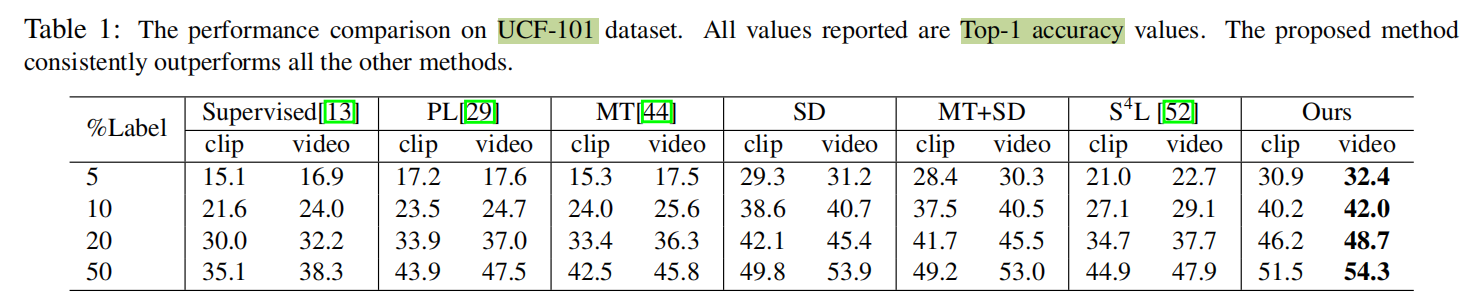
在UCF101、HMDB51、Kinetics三个数据集上学习,和一些2D分类的作比较。由于这几个数据集是有标签的,所以这篇文章选择了5%、10%、20%、50%的标签进行试验。评价标准用Top-1 acc。


【2】Self-supervised Video Transformer (CVPR 2022)
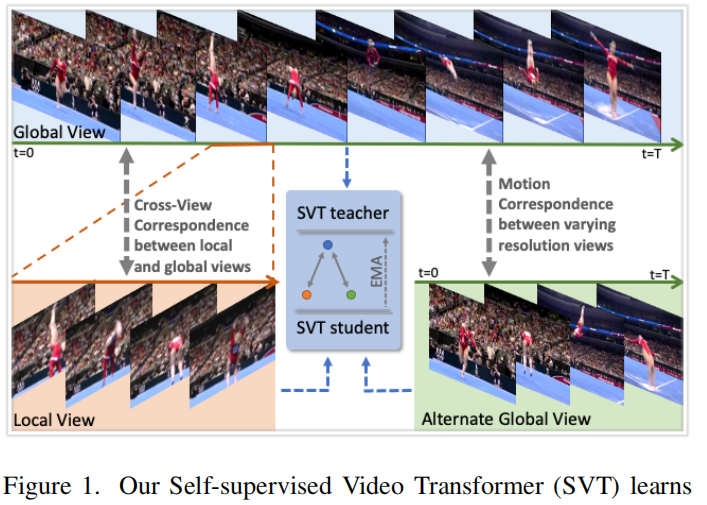
**简介:**用自监督方式的Transformer进行视频动作识别任务,使用的是两种不同view(local, global)的信息差来自监督的。Global View是长的整个视频,然后Local View是节选的其中一段(并且画面大小也会截),Alternate Global View是更少采样率的一段,两个包含更少信息的经过student网络,更多信息的经过teacher网络,然后学生网络输出逼近教师网络,这两个网络之间通过EMA共享参数。
方法的一些细节
Global View有两种,是时长为8的,是时长为16的,大小是224x224。Local View长度是2,4,8,16,节选的部分随机,并且画面大小是96x96,总共生成8个。
这些View通过ViT网络得到[CLS]位置的单个向量再过一个MLP得到,然后他们可以算loss。
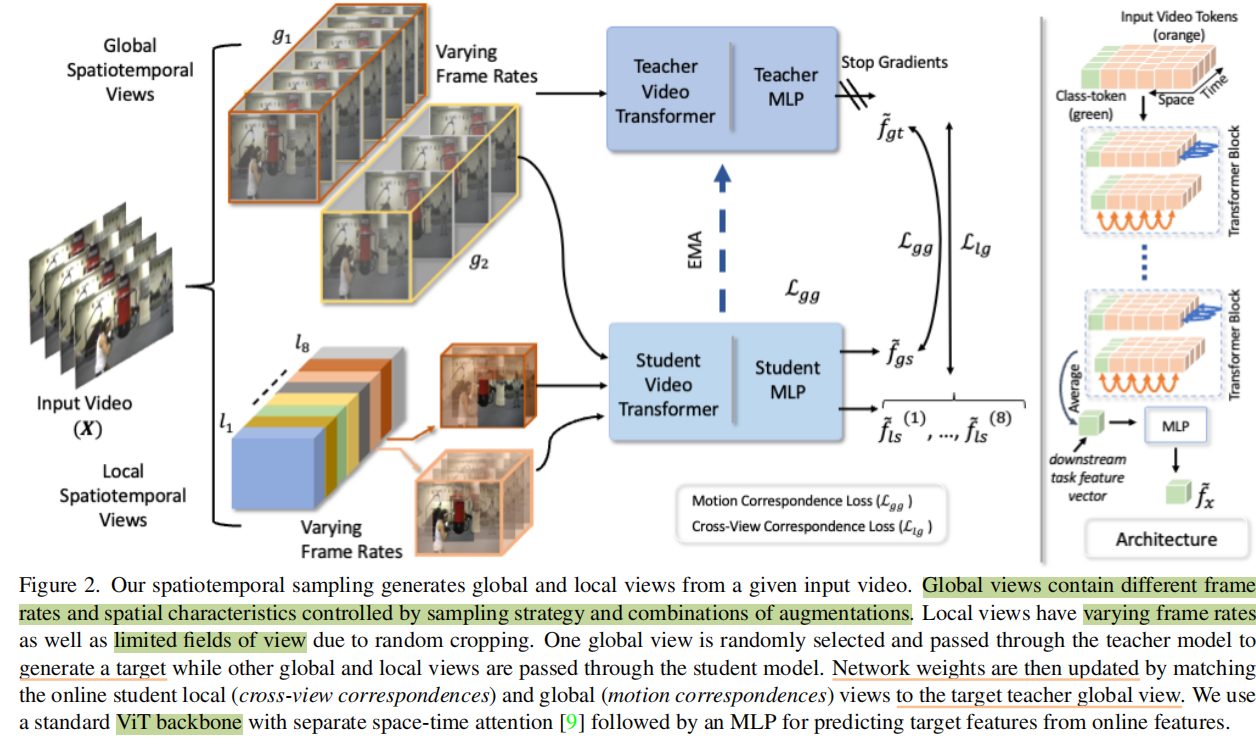
那么问题来了,同一个网络怎么处理不同大小的输入呢?作者在3.2.3节里使用了动态Positional Embedding,就是把缺失的地方补全,比如缺失了1 2 3帧,那1 2 3帧的位置就只有本来的PE,空间上同理。
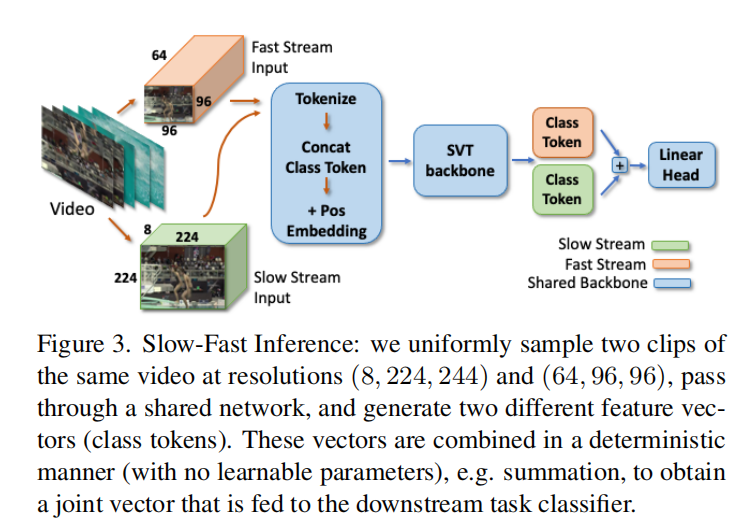
推理阶段这个论文使用slow-fast的模式,就是把视频分成画面小但时间细和画面大但时间粗的两路出入,然后送进网络,然后在综合两个输出(相加)进行推理。
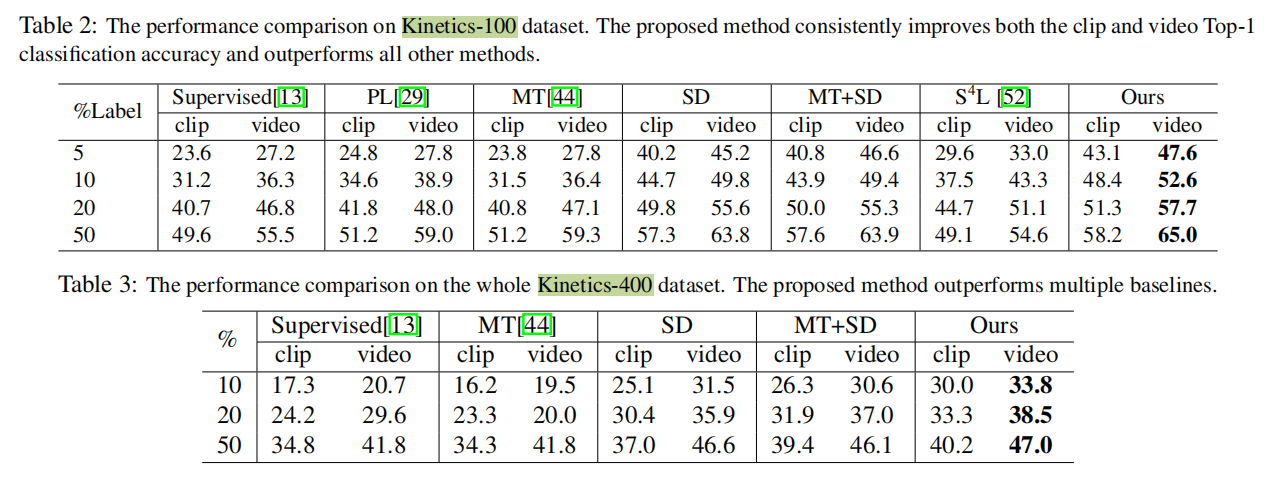
结果
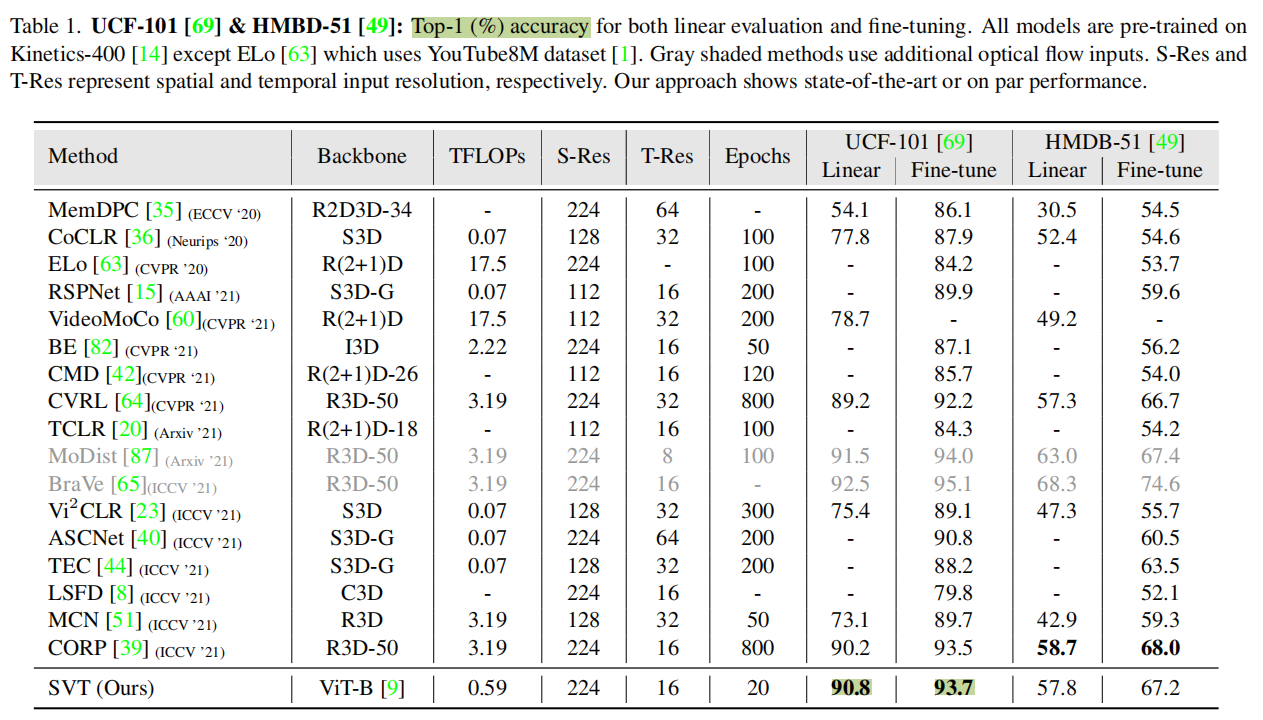
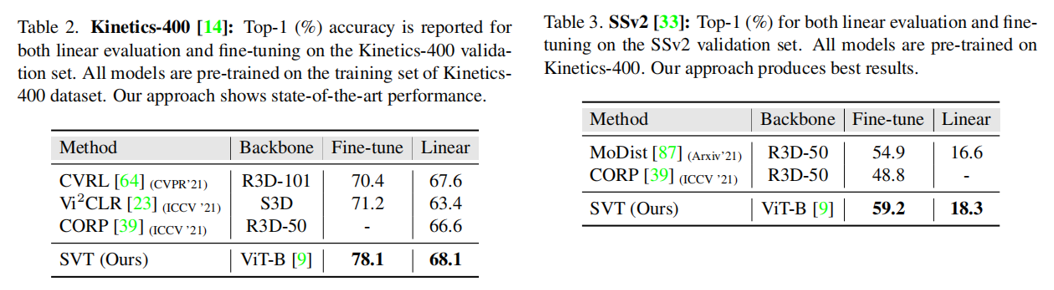
Table1 2 3是先在K400上自监督预训练后,再进行监督学习下游任务得到的结果,Linear是保持backbone不变只train线性层,fine-tine是用改变ViT的projection head然后用初始化参数进行end2end的训练。
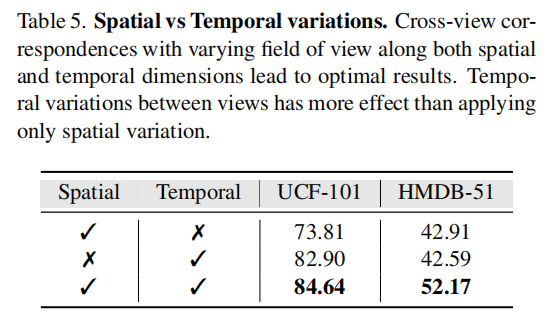
下面这个是消融实验中控制空间时间变量的结果,可以看到不用空间效果会下降一些。
【3】Anomaly Detection in Video via Self-Supervised and Multi-Task Learning(CVPR 2021)
**简介:**自监督多任务学习进行异常检测任务,这里主要关注多任务自监督的方式。自监督有4个任务:
- 预测视频是倒放还是正常
- 预测帧顺序是否正常,有没有跳帧漏帧
- 对缺失视频帧进行预测
- 知识蒸馏,预测YOLO的分类和ResNet的最后一层

【4】Multiview Pseudo-Labeling for Semi-supervised Learning from Video (ICCV 2021)
**简介:**用伪标签的方法,使用multi-view进行半监督学习,进行动作识别任务。这里的multi-view类似多模态,作者用了RGB、光流和相邻帧差值作为三个view,但是只需要训练一个模型,在推理的时候也只用RGB。在生成伪标签的时候,对于同一个视频,三种view得到的概率分布会通过加权平均的方式综合起来计算。并且,本文还用weakly-augmented得到的概率分布sharpen之后作为strongly-augmented的监督信号。
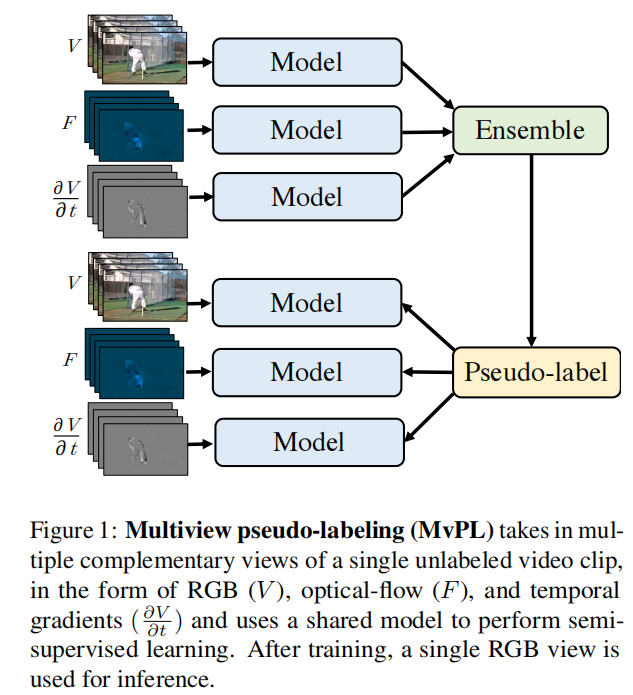
一些细节
Q:为什么要用这样三种view?
A:这样可以直接在输入空间内对外观特征和运动特征进行编码,让模型学到不同的知识。
Q:如何结合三种view的结果?
A:作者探索了四种方式(自监督、随机监督、交叉监督、集成监督)。自监督就是RGB的view得到的结果用来作为RGB的伪标签监督信号。随机监督就是RGB得到的结果可能用来作为其他view的伪标签监督信号。交叉监督就是把随机变成固定的一种映射。集成监督就是把所有view的结果加权求和得到一个集成结果,然后用这个结果作为伪标签监督。(实际上这个权重三个view相同)
Q:三种view是怎么输入进去的?
A:RGB是HxWx3,差值也一样,问题是光流图是HxWx2,所以增加一维是另外两个维度的平方和。这样输入就统一了。
Q:有标签和无标签怎么结合的?
A:一个batch内控制无标签数据是有标签数据的倍,这个设置成3或者4。
Q:伪标签怎么选择的?
A:用了三种方法(Pseudo-Label、FixMatch、UDA),Pseudo-Label是最简单的方法,用模型预测出伪标签然后作为自己的监督信号。FixMatch是改进方法,先从比较弱扰动的数据中得到更可信的伪标签,然后用这个作为强扰动的数据的监督信号。UDA和FixMatch很像,区别在于得到的伪标签不是取极值而是sharpen后作soft-label。
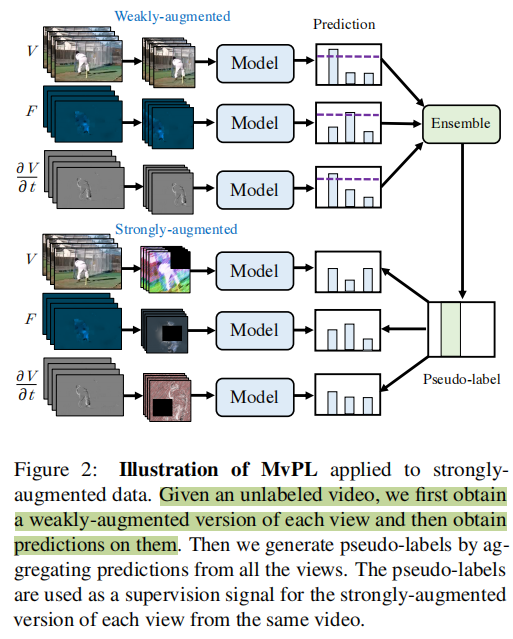
效果
效果貌似有点太好了,比【1】VideoSSL的好了非常多,甚至这里Supervised的都比【1】好(有点不自然,不知道是哪篇有问题),都没代码。
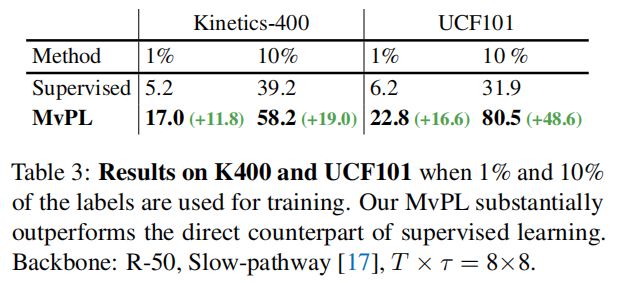
(a)可知FixMatch的方法挺好,(b)可以发现最大贡献点来源于multi-view,无论是加上Flow还是TG,(c)可以发现多个view的伪标签结合方式是Agg最好。
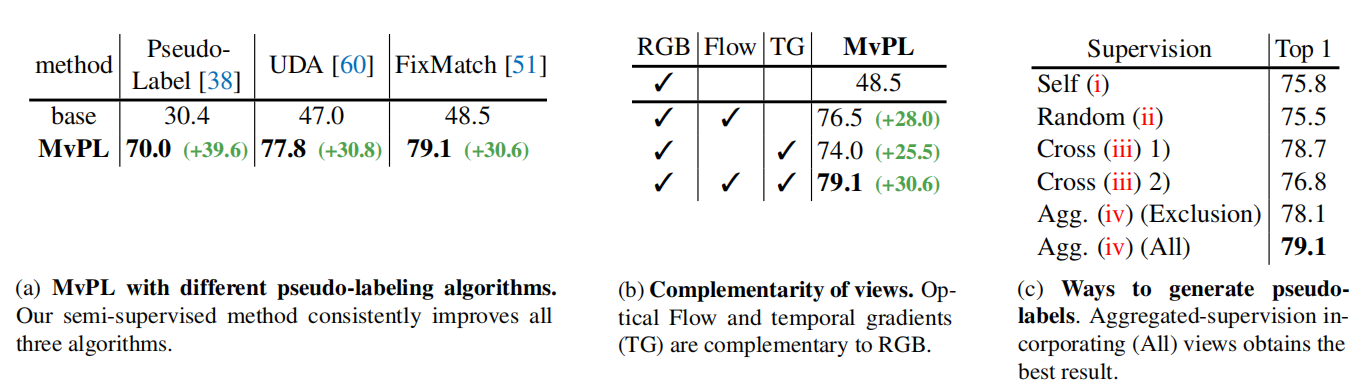
和自监督方法的比较
目前很多自监督方法是在K400上预训练,然后在UCF和HMDB上微调得到指标,本文的半监督把K400看作无标签数据,UCF和HMDB看作有标签数据,然后和他们比较,发现效果挺好。
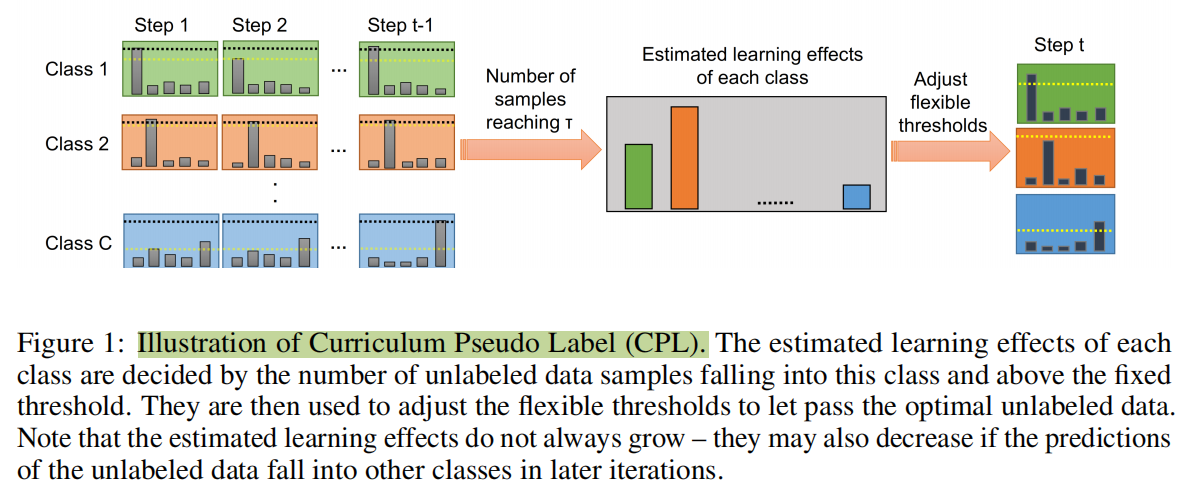
【5】FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo (NeurIPS 2021)
NeurIPS 2021 | 助力半监督学习:课程伪标签方法FlexMatch和统一开源库TorchSSL - 知乎 (zhihu.com)
**简介:**基于FixMatch的增强,但是也适用于其他SSL算法,有开源工具库TorchSSL。之前算法选择伪标签都是设置一个固定的高阈值,但1. 不同类别的学习难度不一样应该有不同的阈值,2. 起步阶段模型结果的置信度不高, 3. 起步阶段模型预测的概率普遍低,大部分数据都超不过阈值,导致收敛慢。所以这篇文章给予每一个类动态阈值,并且让阈值从小到大(threshold warm-up)。作者在图片分类任务进行实验。
一些细节
如何为每一个类设置动态阈值呢,这个问题即估计每一个类的学习情况,而学习情况可以通过高于固定阈值且预测正确的样本个数来估计(即模型确信是某个类别的且预测正确)。这里的固定阈值就是之前方法通常设置的一个高阈值,学习情况用表示类别在时间的情况。然后时刻的动态阈值为:
为了让阈值从小到大(threshold warm-up),改写了上式:
表示符合高于固定阈值且预测正确的样本个数,那么就是不符合条件的样本数,在早期这个数字比较大,所以会导致结果阈值更低。那么为了更好的自定义,还可以加非线性映射,他们实验效果好。
实验结果
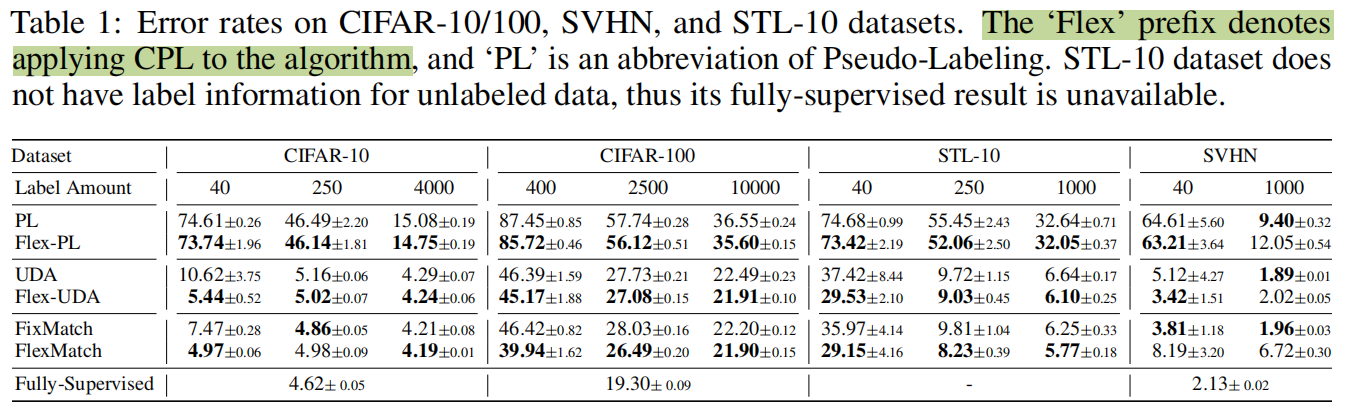
在不同的SSL上面加上CPL效果都有提升
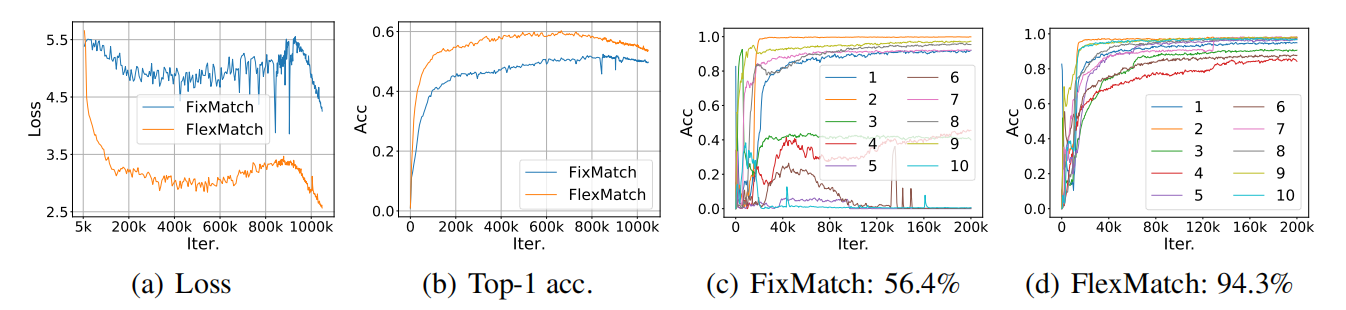
(a)(b)可以发现FlexMatch收敛更稳定也更快更好,©是其他方法对于一些难分类效果不佳,(d)能看出本文方法所有类效果都挺好。
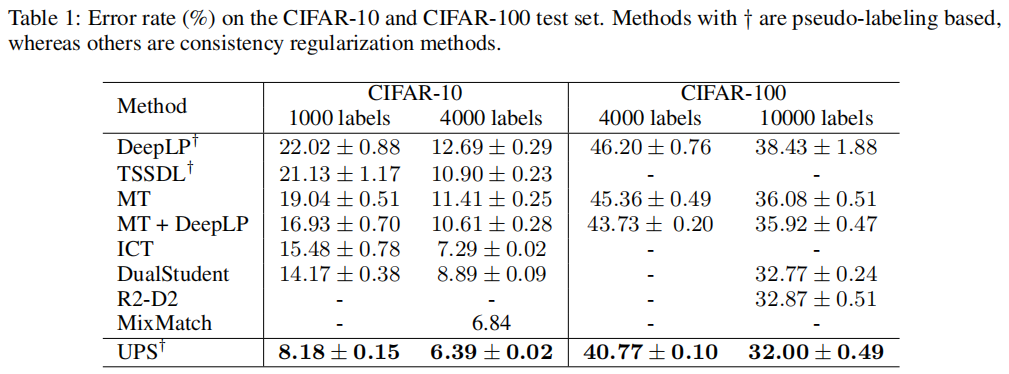
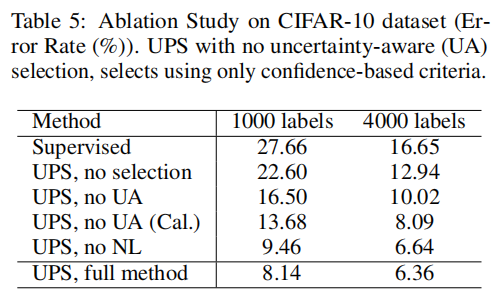
【6】In Defense Of Pseudo-labeling: An Uncertainty-aware Pseudo-label Selection Framework For Semi-supervised Learning (ICLR 2021)
**简介:**一种通用的分类问题的基于伪标签的半监督学习方法。改进的方向是选择更好的伪标签。改进方式是1. 利用模型对数据不属于某个类的信息 2. 根据模型预测的不确定性过滤伪标签。代码:nayeemrizve/ups。
细节
-
首先介绍
利用模型对数据不属于某个类的信息,主要思想是:我不确信这个数据属于哪个类,但是我确信它不属于哪个类!。如下图,对于一个类计算loss要。其中,是模型生成的伪标签,是模型这次预测的概率,判断是否对该类计算loss,由下面这个式子得出:
其中 是判断函数,符合条件为1,不符合条件为0。是两个阈值。就是将确信属于某个类或者确信不属于某个类的标记为1。

-
然后是
根据模型预测的不确定性过滤伪标签是模型预测出概率的不确定性,是两个不确定性的阈值。
只有模型对于结果的不确定性低于阈值才选择,那么如何得到不确定性呢,作者使用MC-Dropout效果最好,是论文Dropout as a Bayesian Approximation:Representing Model Uncertainty in Deep Learning中提到的方法。
就是在生成伪标签的时候,开启网络中的Dropout层(model.eval()会默认关闭),然后前向传播10次,得到10个结果
[10,B,C],然后平均结果求出模型预测的类,并求对应的十次结果的标准差,用标准差作为不确定性。
实验结果
虽然加上了不确定性来过滤label会导致伪标签数量一开始较少,但Acc保持较高水平,且在后期伪标签数量也会上来。

效果还行,没有上面的Flex-Match好。
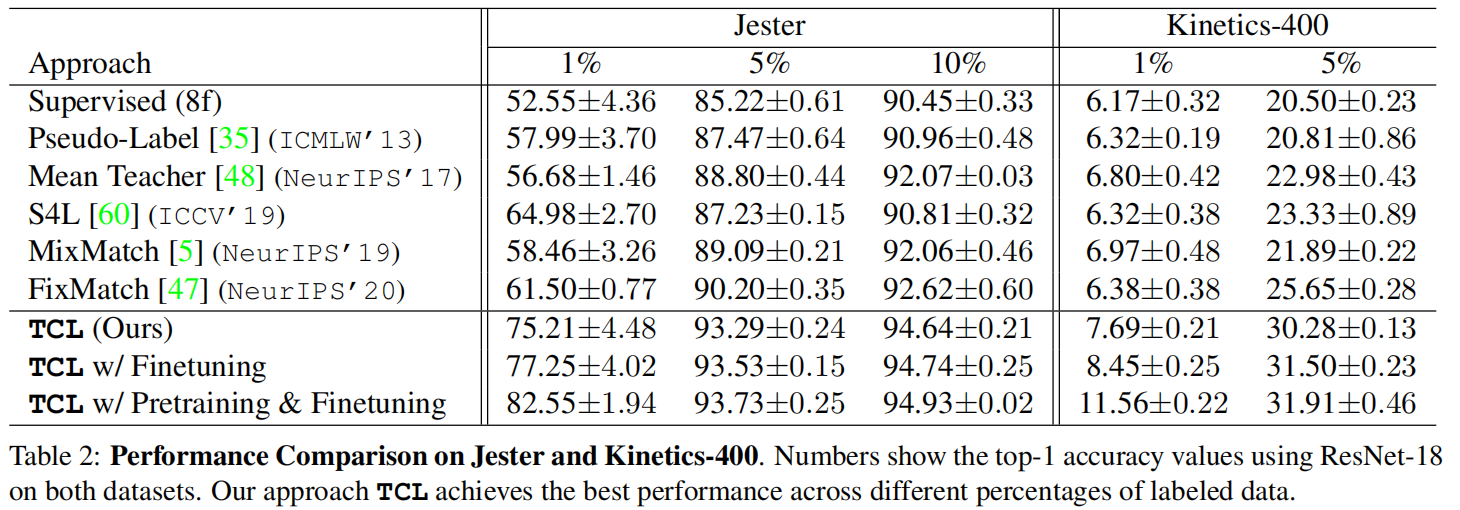
【7】Semi-Supervised Action Recognition with Temporal Contrastive Learning (CVPR2021)
简介:半监督动作识别任务,无标签数据通过相同视频不同速度和不同视频不同速度之间计算对比Loss来利用。创新点主要在于Group的对比学习,平常对比学习就是自己和自己构建正样本,自己和batch里其他数据构建负样本,但是这样其实可能其他数据和自己是同一个类,构建负样本不太合理,所以这里通过生成伪标签来把batch里的样本分成好几个Group,每个Group平均后互相之间构建负样本来对比学习。

一些细节
论文好像没说batchsize有多大,github库里给的示例是8,假如真是8那一个batch也没多少同一类的吧……
作者训练的时候分三个阶段,1是用所有数据进行自监督学习,2是如图的TCL方式,3是生成伪标签来fine-tune。
效果
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!