深度学习之半监督学习
本文最后更新于:2022年7月21日 下午
深度学习之半监督学习
**半监督学习(Semi-Supervised Learning)**指的是一部分数据有标签,一部分数据没有标签下进行的学习,通常无标签的数据量远多于有标签的。这种数据比较符合实际情况,因为标注数据比较困难,往往能够够收集到很多数据但是无法全部标注,此时就能用到半监督学习,而且人的学习也类似,老师先告诉小孩一些知识,然后小孩自己学习更多的知识。
半监督学习可以细分为
Transductive和Inductive。前者是说你用测试集的数据来作为半监督学习的无标签数据,后者是说你的训练集就是一部分有标签一部分无标签的。就比如比赛的时候下发了训练集的图片和标签,然后还给了一份测试集的图片,那把测试集拿过来进行半监督学习就是
Transductive。
假设基础
半监督学习基于一些假设,只有符合这些假设半监督学习才work!
-
The Smoothness Assumption:
简单来说是平滑相似的样本得到相似的输出。但是有些歧义,李宏毅的视频在大概34分钟开始时介绍这个假设。这里只是简单概括一下他的解释:
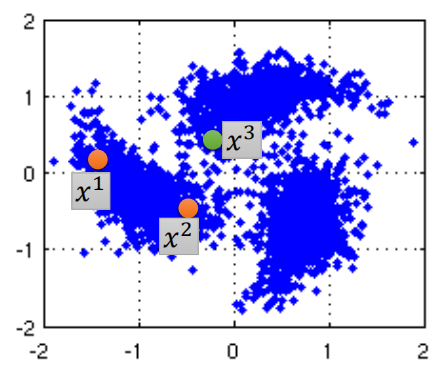
举例:假设和是“相似”的,他们与不相似,那么根据The Smoothness Assumption,图上的橙色的两个点也应该“相似”,但是貌似对应的点离对应的点更近?所以“相似”定义为在高密度区域更接近,即和对应的点之间是高密度区域,所以他们相似,而和虽然距离更近,但是其间是低密度区域,所以不相似,符合The Smoothness Assumption。

再举个例子:如箭头所示,中间的
2和最左边那个2看上去其实比较不像,反而和最右边那个3比较像,但是这不是我们定义的“相似”,Smoothness指的是中间的2和最左边那个2中间会有很多过渡状态,他们都属于2这个类。虽然有人会把2写得像3,但毕竟是少数,所以2到3的过渡状态很少,很稀疏(或者叫变化很sharp)。 -
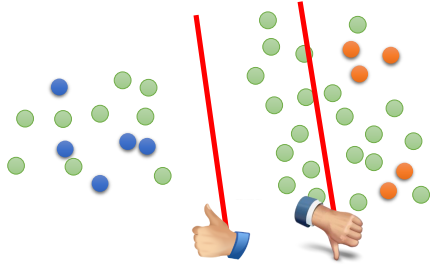
The Cluster Assumption
输入点属于同一个cluster时,他们应该属于同一个class,也就是决策边界位于低密度区域。
-
The Manifold Assumption
这个可以参考这个回答,同样我也简单概括一下,就是存在于高维的数据其实大概分布于一个低维的Manifold上。

举个例子,假设你在一块平玻璃板上画了很多个点,那么这些点就存在于一个二维空间上。现在你把这个玻璃板的一端拿起来,那么这个斜着的玻璃板上的点就位于一个三维空间内了。然而,即使在更高维的空间(三维空间),数据还是分布在一个低维的Manifold上(二维平面)。
再举个例子,声音是多种多样的,事实上,你随便画一个波形都可以看作是一段声音,所以声音的维度非常大。然而,人能发出的声音是受限的,是通过声带和声道发出来的,人不可能发出一个纯400Hz的声音,人声具有它特定的一种规律,也就是处在一个低维的Manifold上。假如我们要半监督学习来进行语音识别,那么标签数据可能就是一段话和对应的文字,无标签数据就是许多人说的音频,这些无标签数据虽然没有标签,但是它包含内在的规律,学习到这种规律的模型比只用标签数据训练得到的模型更强。


再再举个例子,上面这两张图,假如只用标签数据训练得到的是第一张图的判决边界,而加上了无标签的数据(绿点)就会得到第二张图的判决边界。我们可以看到在无标签数据的帮助下,分布从有误差的椭圆变成了圆。
常用方法
伪标签法(Pseudo-Label)
也叫做Self-training,这种方法非常直观,第一步先使用标签数据训练出一个模型;第二步用这个模型来为无标签数据进行预测,得到伪标签;第三步将一些带有伪标签的数据转移到有标签数据中(比如一些置信度比较高的预测),然后回到第一步重复。
可以通过给伪标签的数据分配更低的loss权重来改进,也可以通过设置置信度阈值来改进,但是不能像下面这样soft-label改进,因为预测出[0.7, 0.3]后确定[1, 0]的过程就是这个方式work的核心,soft的方式为何不起作用?李宏毅老师讲得很明白了,你本来是想让伪标签降低一些确信度,但是要知道现在模型预测的结果就是[0.7, 0.3],你在下一轮还是说要达成相同的[0.7, 0.3]的目标,那模型能有啥改变?同时,李宏毅老师也说了这种方法在回归问题上肯定不能用的,也是同样的道理,因为没有从[0.7, 0.3]后确定[1, 0]的过程。
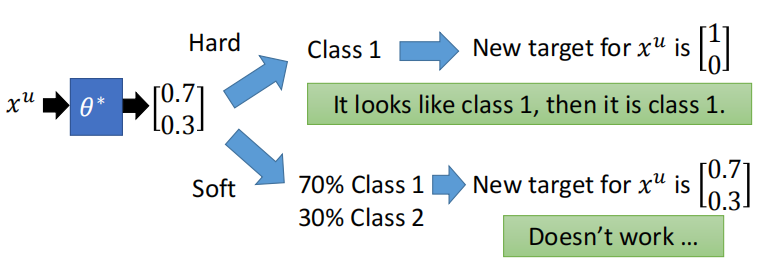
那么正确的改进方向是什么呢?也借用李宏毅老师的一页PPT,在Loss上增加一项,来惩罚不确定的伪标签。假如对于某个没有标签的图像我90%确信它是猫猫,那它真正的标签可能就是猫猫,而假如我只有50%确信它是猫猫,那这个情况的预测的Entropy就会很高,Loss就会变高。

一致性正则法(Consistency Regularization)
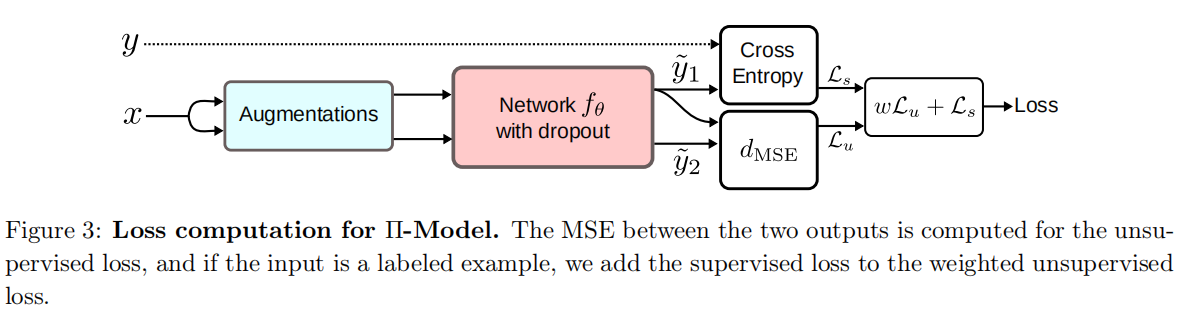
核心思想:将输入进行轻微扰动得到,那么模型得到的两者的输出应该尽可能接近。
进行怎么样的扰动和使用什么方式测量距离是这种方法的改进方向,下面是一个实例(来自An Overview of Deep Semi-Supervised Learning),不同的augmentations和dropout能带来扰动。
参考文献:
【机器学习基础】半监督学习简介 - Uniqe - 博客园 (cnblogs.com)
伪标签(Pseudo-Labelling)——锋利的匕首 - 知乎 (zhihu.com)
伪标签还能这样用?半监督力作UPS(ICLR 21)大揭秘! - 知乎 (zhihu.com)
李宏毅 ML Lecture 12: Semi-supervised - YouTube
长文总结半监督学习(Semi-Supervised Learning) - 知乎 (zhihu.com)
An Overview of Deep Semi-Supervised Learning
What is the manifold assumption in semi-supervised learning? - Cross Validated (stackexchange.com)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!