近期看的一些论文#1
本文最后更新于:2022年7月21日 下午
近期看的一些论文#1
[TOC]
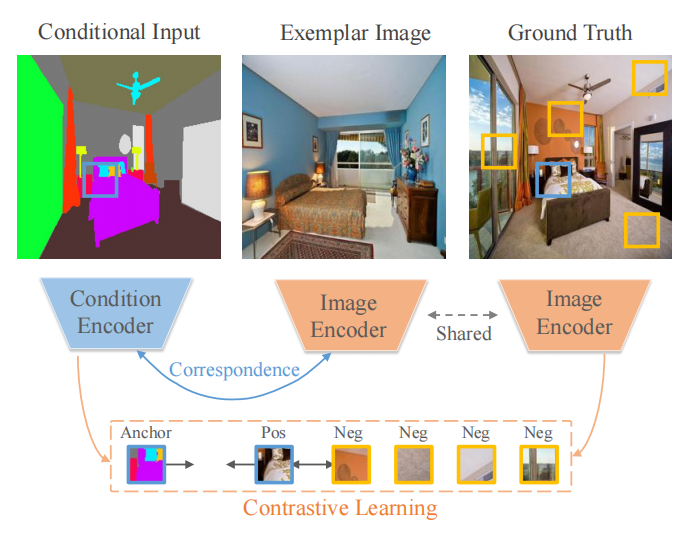
Marginal Contrastive Correspondence for Guided Image Generation
说的是用条件输入和示例风格图片输入生成和条件输入形状一样,和风格输入的风格一样的图片的任务。
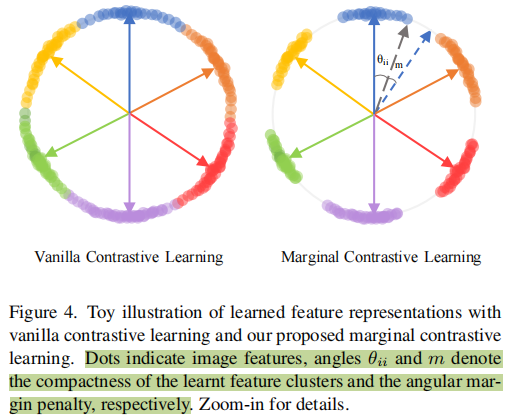
这里说的Contrastive是在Conditional Input和Ground Truth的编码特征进行对比学习,这里用来一个marginal contrastive loss比较有意思,大概意思是小明考了100分但是我只给他90分从而让他不要骄傲。伪代码如下图,就是在相乘得到的余弦相似度分数矩阵对角线上加一个角度,对于正确预测的例子给一个惩罚,从而得到margin的效果。

In Defense Of Pseudo-labeling: An Uncertainty-aware Pseudo-label Selection Framework For Semi-supervised Learning (ICLR 2021)
针对使用伪标签(Pseudo label)方法进行半监督学习的改进。贡献点有两个:1. pseudo-label selection 2. uncertainty-aware pseudo-label selection
首先是伪标签选择机制(Pseudo label selection):主要思想是:“我不确信这个数据属于哪个类,但是我确信它不属于哪个类!”。如下图,对于一个类计算loss要。其中,是模型生成的伪标签,是模型这次预测的概率,判断是否对该类计算loss,由下面这个式子得出:
其中 是判断函数,符合条件为1,不符合条件为0。是两个阈值。就是将确信属于某个类或者确信不属于某个类的标记为1。对于多标签任务,论文里也有适用的Loss的变种。

然后,作者通过预测模型的不确定性改进了上面的伪标签选择机制(uncertainty-aware pseudo-label selection)。
其中是模型预测出概率的不确定性,是两个不确定性的阈值。
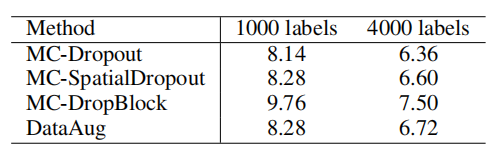
而如何预测模型的不确定性有很多方法,作者尝试了很多,效果如下:
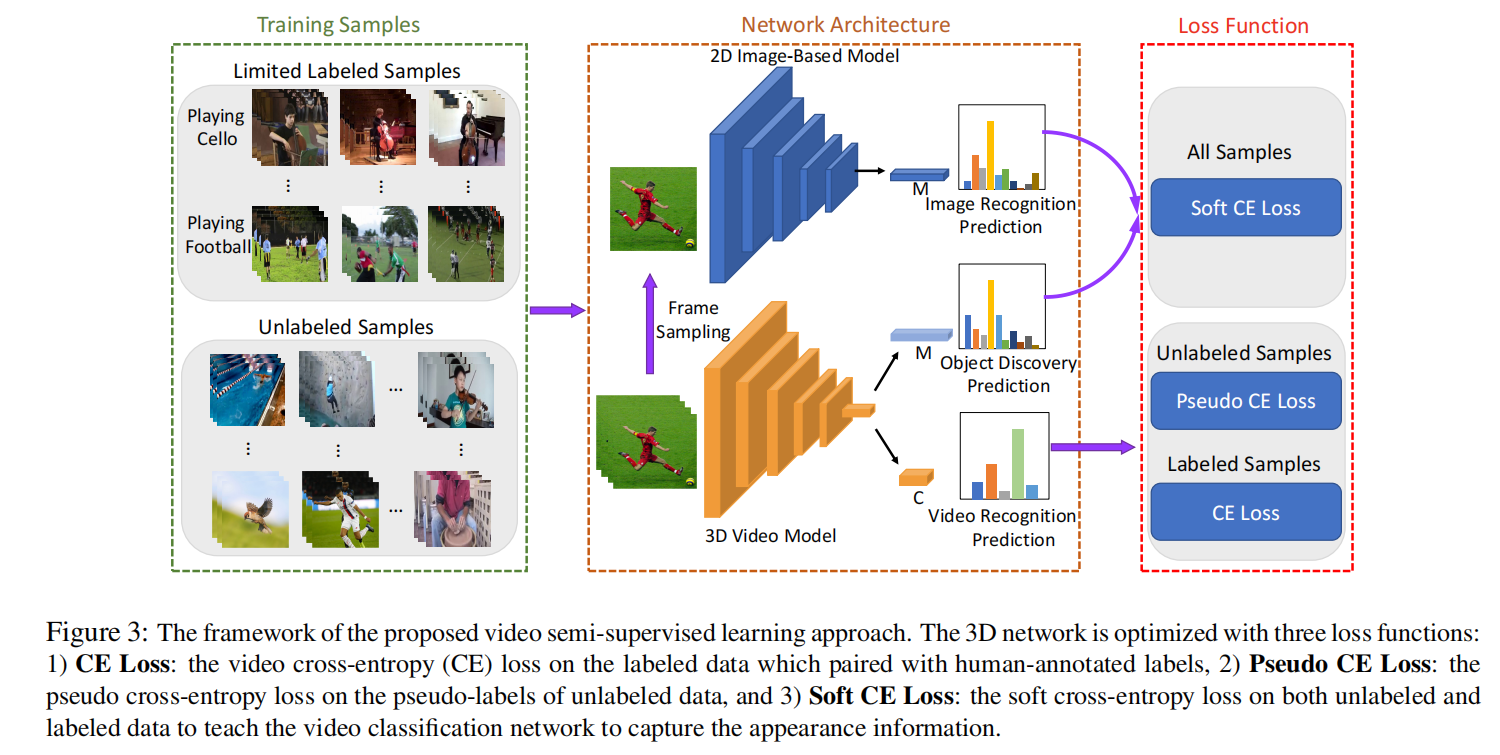
VideoSSL: Semi-Supervised Learning for Video Classification
半监督视频分类学习任务,有标签的数据直接用3D CNN进行CE Loss,然后无标签的生成伪标签后Pseudo CE Loss,顺便还进行一个知识蒸馏,3D CNN的概率输出逼近一个预训练好的2D CNN的概率输出,论文中M是ImageNet的1000类,那个Soft CE Loss就是计算互信息。
方法挺简单的但是也没放出代码来……
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!