mixup数据增强方式
本文最后更新于:2022年7月21日 下午
mixup数据增强方式
参考文献:
在PyTorch中用Mixup增强神经网络 - 知乎 (zhihu.com)
mixup: Beyond Empirical Risk Minimization (Paper Explained) - YouTube
一般的深度学习模型训练的方式是这样的:,其中是输入,是参数,是预测结果;然后计算loss,其中是Ground Truth。而的分布和真实分布是不一样的,所以最小化的不是真实风险,而是经验风险。所以,论文mixup:BEYOND EMPIRICAL RISK MINIMIZATION中提出了一种方式来增强模型拟合能力。
论文mixup的基本思想是将数据混合构建虚拟样本,如下图所示,有两个数据点A、B,其中A是class 0,而B是class 1,他们的ground truth对应就是一个one hot向量。mixup就是通过混合AB来构建虚拟数据点,同时标签也进行混合得到概率分布,这样就得到了新的样本。
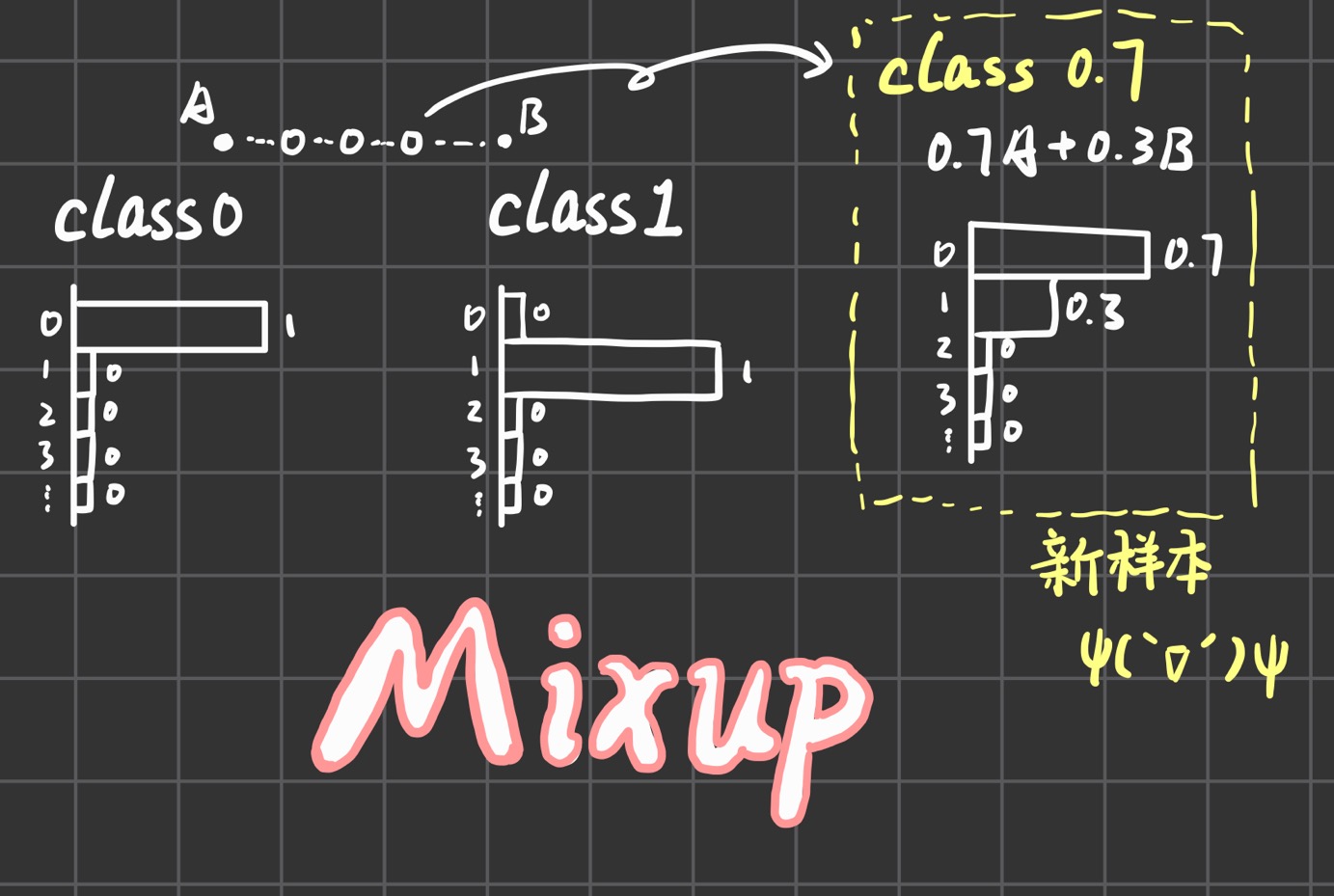
具体效果如下图所示,用公式表示的话:设是原始输入向量、是新数据,则;设是原始one-hot标签,是新标签,则。
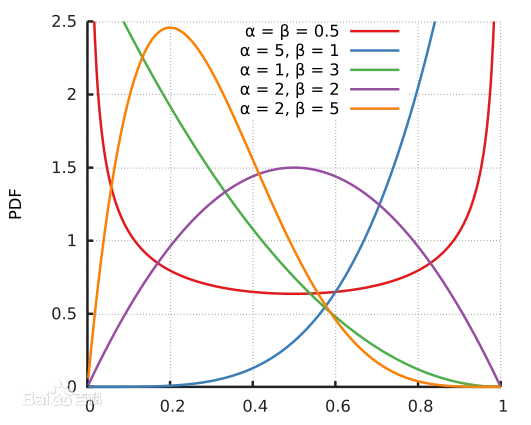
对于的取值,论文使用的beta分布,也就是说,大概率靠近0或者1,少数情况是将两张图片进行混合。
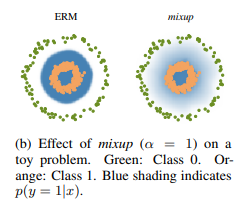
这张图展示了使用mixup的效果,左边的图在没使用时,可以发现蓝色的边界非常尖锐,而使用mixup之后蓝色边界更平缓。也就是说,模型对于不确定的图片更加不确定。
AlignMix
最开始的mixup方法只使用简单的插值来混合两张图片,然而这个效果可能并不是很好,所以cvpr2022上有一篇新的论文来更好地混合两张图片。
AlignMixup: Improving Representations By Interpolating Aligned Features


论文效果如左图(论文原图像素有点低看着也看不出啥……),他们的贡献点1. 提出AlignMixup,能在特征空间中进行局部结构差值 2. 可以用自编码器来提升效果 3. SOTA

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!