初见自监督学习
本文最后更新于:2022年7月21日 下午
初见自监督学习
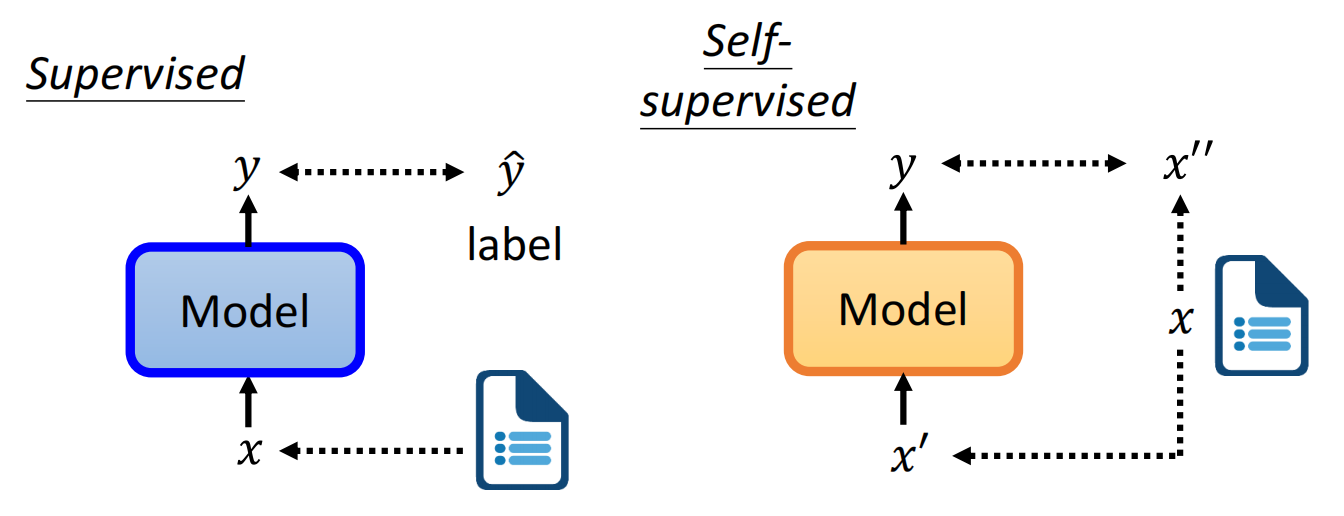
自监督学习就是把数据集中的数据,一部分作为来输入,另一部分作为来与输出比较。我理解就是找个方法无中生有来进行监督学习。
BERT
用Bert来举例子,在预训练阶段,Bert同时进行Masking Input和Next Sentence Prediction两个任务。前者就是把随机输入的一部分mask掉,然后让模型预测mask位置的字;后者就是用[SEP]分隔两句话,然后让模型判断两句话是不是连续的。
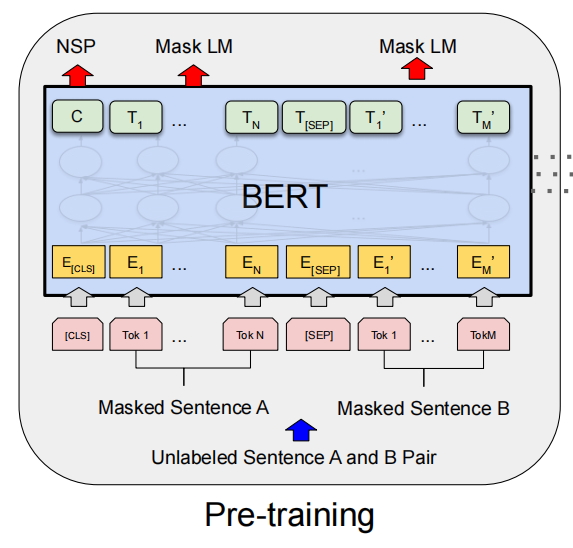
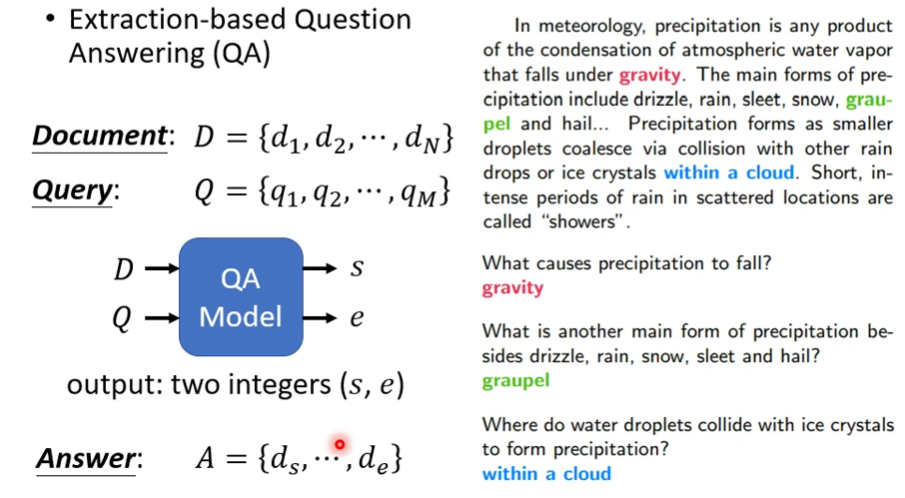
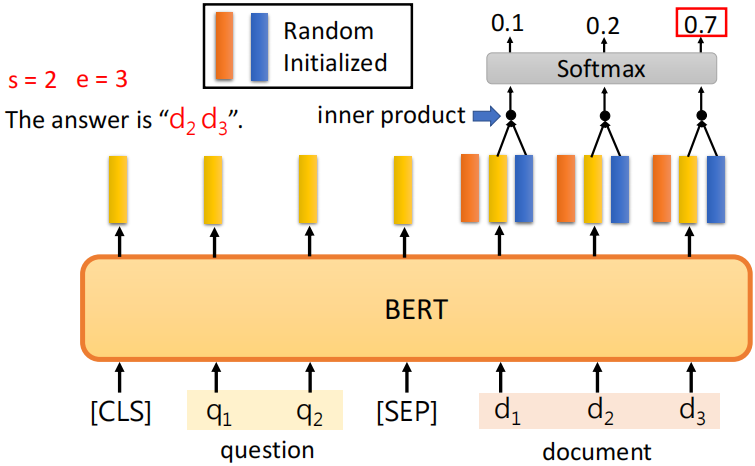
之后,预训练好的BERT就可以进行Sentiment Analysis(语义情感分析)、POS tagging(词性判断)、Natural Language Inference(自然语言推理)、Extraction-based Question Answering(基于提取的问题回复,见下图)。QA任务比较特殊,输入文档和问题,然后输出两个数字,然后答案就是第s个单词到第e个单词。
GPT
GPT进行的预训练任务是Predict Next Token(类似seq2seq),拥有Generation(生成)能力。

要用GPT进行下游任务,甚至不用fine tune,只用给出如上图这样的输入就行……但是正确率不太行。
LeCun的文章:Self-supervised learning: The dark matter of intelligence 阅读笔记
只靠监督学习,人工智能领域有局限,我们想要构建更智能的通用模型(generalist models)。通用模型指的是在多个任务上都能表现出色的模型,但是这不能通过标注数据来进行监督学习来实现,因为我们不能标注整个世界。
人通过之前对世界认知得到的常识来进行之后的各类任务(比如识别图片等),并且,面对一个崭新的任务,可能只需要很少的知识就能学会。但在目前人工智能还远远不能达到这个地步,常识(Common sense)就像人工智能的暗物质。
为了构建这种能学会常识的人工智能系统,LeCun相信自监督学习 (Self-Supervised Learning, or SSL) 是一种非常重要的方式。自监督学习不被叫做无监督学习 (unsupervised),因为自监督学习的label是从数据中诞生的。
We believe that self-supervised learning (SSL) is one of the most promising ways to build such background knowledge and approximate a form of common sense in AI systems.
Self-supervised learning obtains supervisory signals from the data itself.
而人在人工智能中起的作用从简单的标记数据转移到如何从数据中创造标签。
而一个很常用的方法就是,隐藏数据中的一部分,然后让模型预测你隐藏的部分(就像Bert的Masking Input一样)。下面这张图展示了这种方法,有颜色的是输入给模型的部分,而透明的是被隐藏起来需要模型预测的部分。
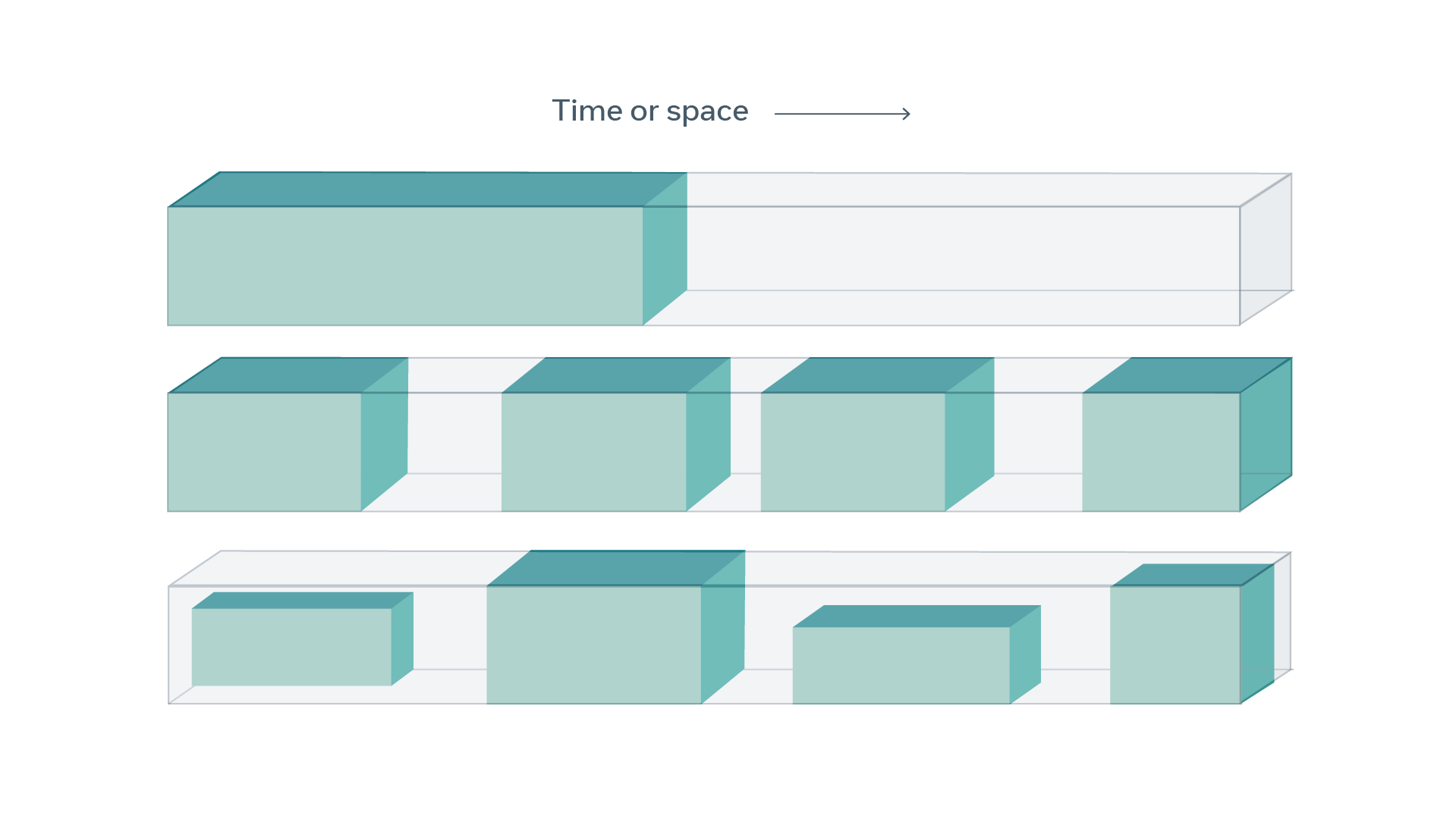
目前SSL已经在NLP领域取得了成功,然而这要延伸到CV领域就比较难了,因为图像的不确定性更大。让模型做自然语言的填空题比较简单,因为有一个限定大小的词表,模型能够给出词表中所有单词在某个位置的可能性。但是在CV领域,预测missing frame、patch或者segment是要预测一个高维连续的东西,它可能有无数种情况。
Energy-Based Model (EBM) 是指给两个输入和,通过一个能量函数 (Energy Function)来计算两者之间的能量,这代表了和之间的匹配程度(类似距离?)。训练EBM有两部分:1. 和相近的时候energy小 2. 和不相近的时候能量大。其中,后者难度更高。
实现这个的一种经典方式叫做Siamese network,他包含了两个(几乎)一样的网络(共享参数),和分别经过网络获得embedding,然后通过一个函数来比较两个embedding。
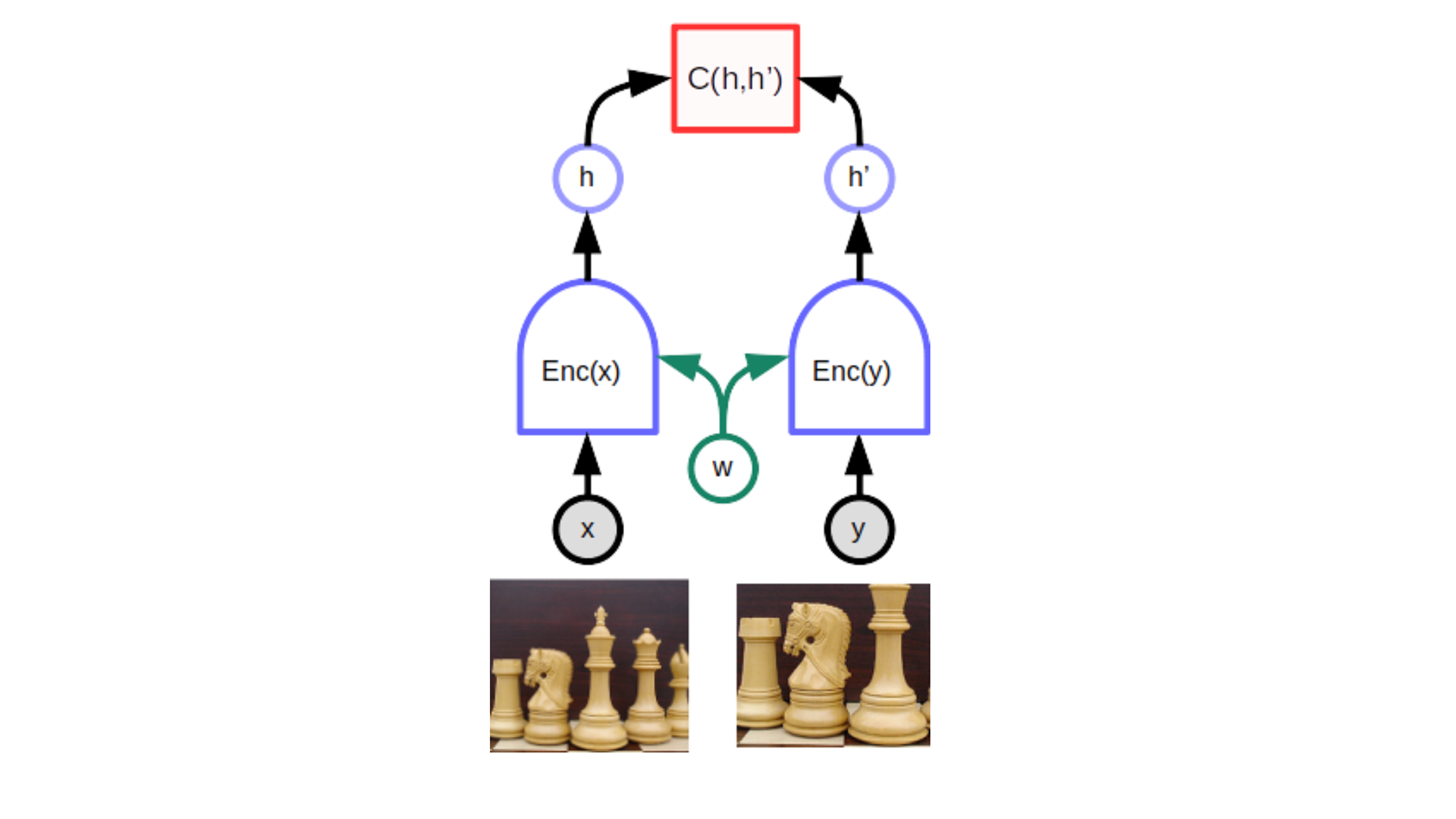
那么如何获取和呢?一种方式是对比学习 (Contrastive),另一种方式是非对比式。
-
Contrastive energy-based SSL
这种方式指的是构建不匹配的对。在NLP中,就是mask掉一些单词。
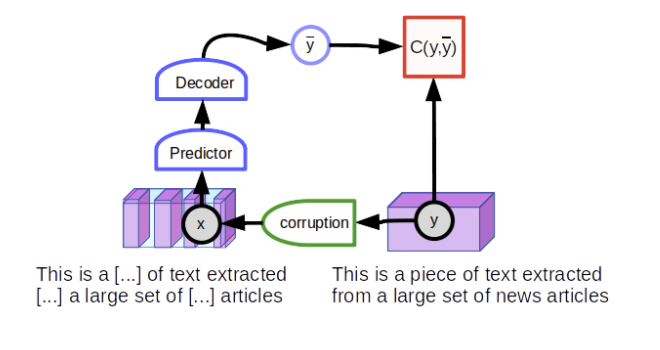
然而在CV中这种方式不太适用,但是另一种隐变量预测架构 (latent-variable predictive architectures)效果不错。隐变量预测模型包含了一个额外的输入变量,它的值不需要被观察,所以叫做隐变量。 隐变量来自于某个空间,通过值的变换,的值也会发生一些变化。用著名的GAN来距离的话,GAN没有图中到Dec这一路,而是完全用随机数来作为输入,而图中的Dec对应GAN中的generator,C对应GAN中的discriminator。
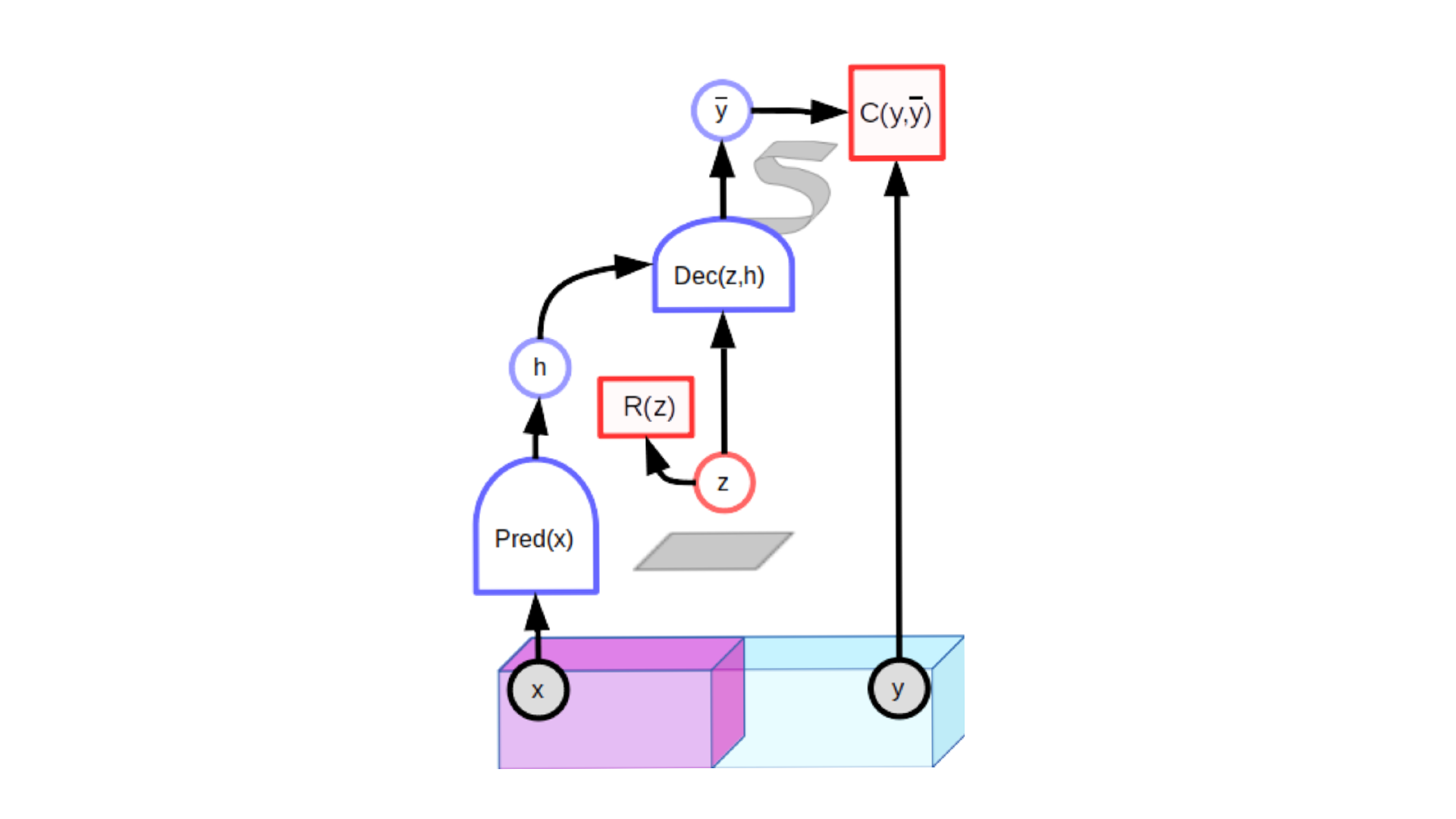
Contrastive的模型的缺点就是训练难度太大了。
-
Non-contrastive energy-based SSL
这种模型没有用对比学习那样的负样本,例子是MoCo、VAE。(不太理解)
Variational Auto-Encoder (VAE):
VAE就是把一个数据集中的图片经过Encoder进行编码,进入到一个低维的隐空间 (Latent Space),然后通过Decoder进行重建得到输出,然后这两者计算Loss。在inference过程中,图中绿色的部分被去掉,只需要从隐空间中随机选择一个点,就可以得到输出。
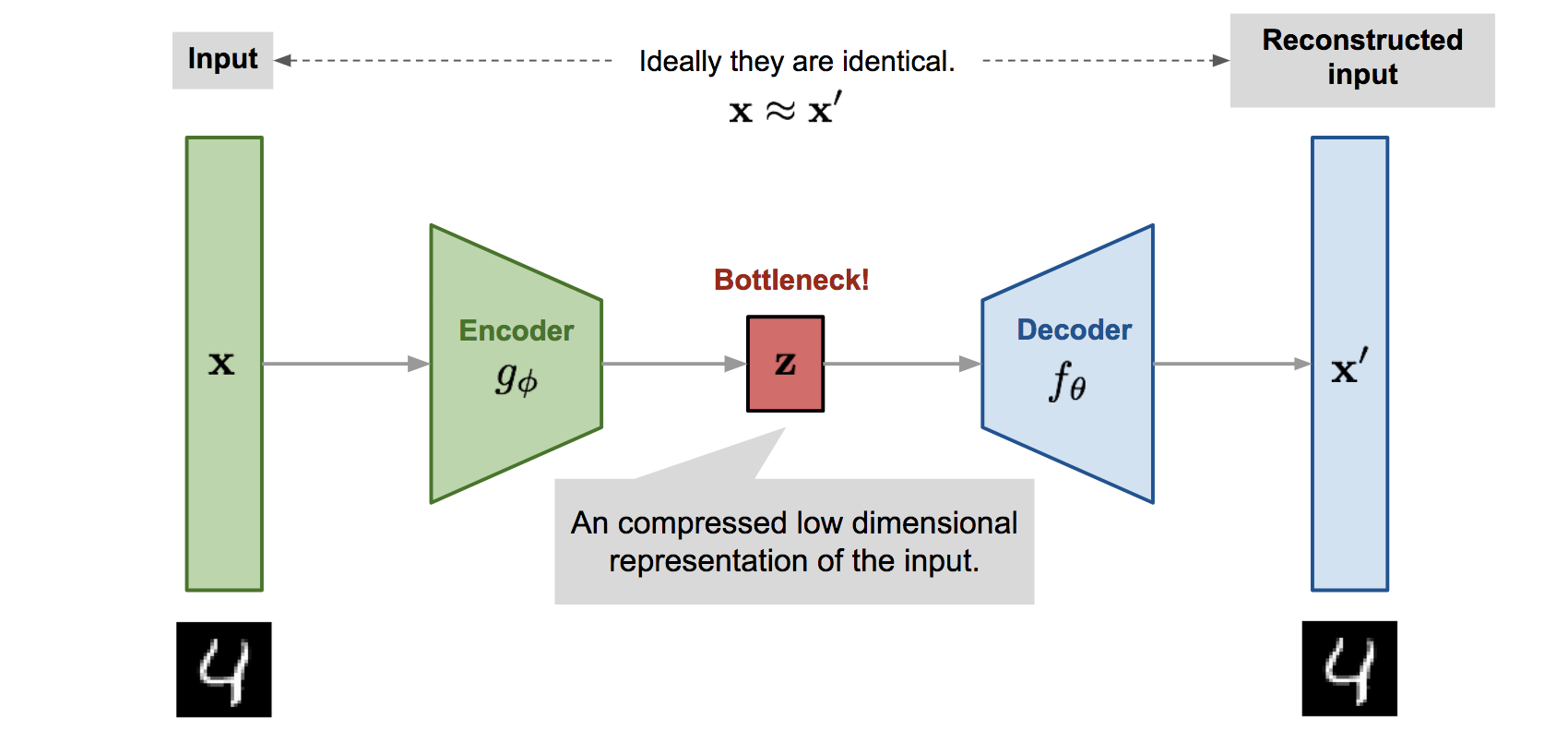
文章中说VAE的隐变量空间被限制了,所以这种结构可能发挥作用,但是目前用的是Decoder,而我们想要Encoder。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!