Transformer中的Layer Normalization
本文最后更新于:2022年7月21日 下午
Transformer中的Layer Normalization
[TOC]
参考文献:
[1] On Layer Normalization in the Transformer Architecture
[2] DeepNet: Scaling Transformers to 1,000 Layers
Post-LN 和 Pre-LN
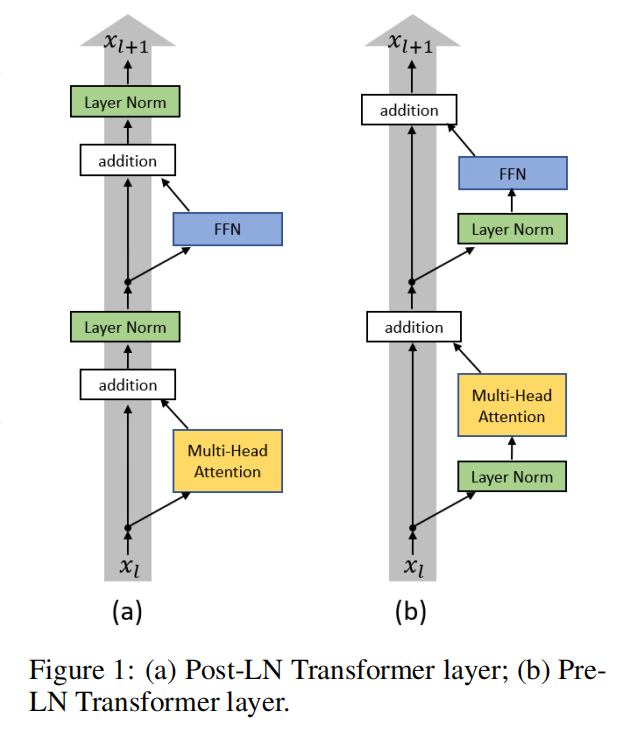
左边是原版Transformer的Post-LN,即将LN放在addition之后;右边是[1]改进之后的Pre-LN,即把LN放在FFN和MHA之前。
动机
[1]的作者发现目前使用Transformer的方法训练常使用warm-up(调低刚开始的几个epoch的学习率),所以研究发现训练开始的时候临近输出层的梯度很大,导致训练不稳定。warm-up有几个不好调的超参数,所以[1]致力于把warm-up去掉。
贡献点
- 新模型可以不用warm-up。
- Pre-LN训练时间可以节省。
实验
做了一些翻译实验,RAdam是对adam优化器进行了修改来解决transformer前期的问题的一个方法。
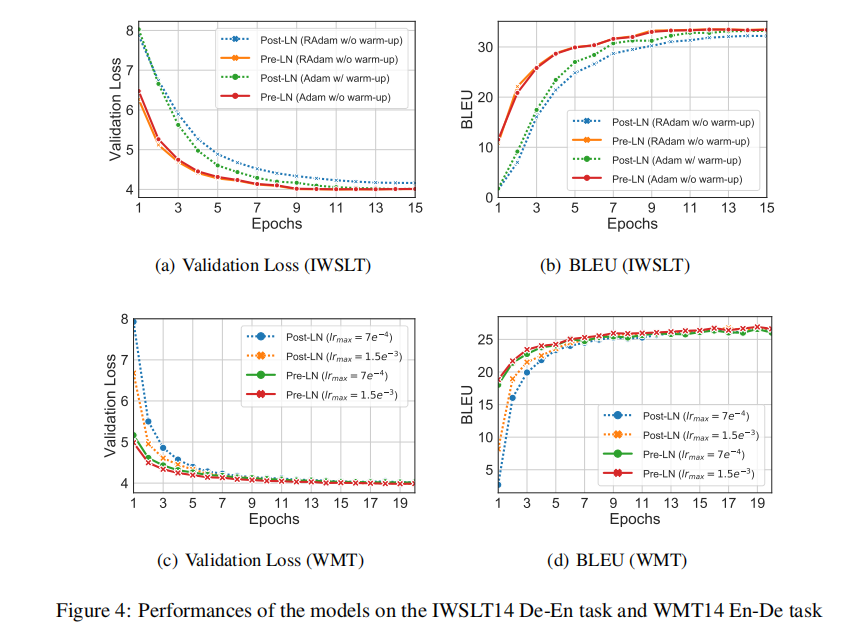
DeepNet 1000层的Transformer
文献[2]的第一张图十分惊艳,1000层的DeepNet没有做太多改动,由500层Encoder和500层Decoder组成。
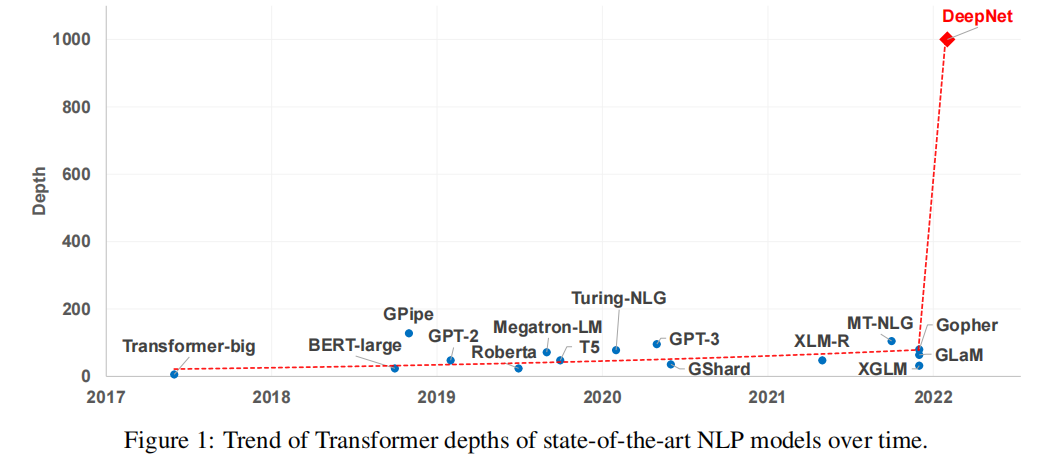
方法
方法很简单,对于一个N层Encoder,M层decoder的网络,确定了超参数。超参一般小于1,用来降低之前输出的权重。超参用来调FFN、self-attn的输入的V的变换矩阵、以及调完权重之后多头融合的out_proj矩阵。

具体方法还有专门的文字介绍:

实验
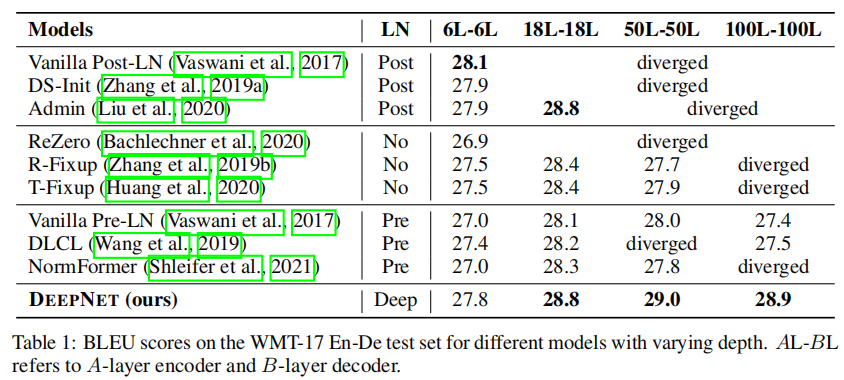
在深层网络中具有明显优势。
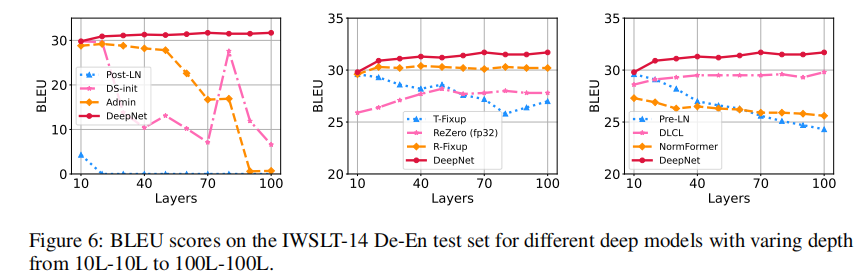
训练过程也更稳健了。

在多语言翻译任务中也用更少的参数取得了更好的效果。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!