Pytorch DDP使用方法以及注意点
本文最后更新于:2022年7月21日 下午
Pytorch DDP使用方法以及注意点
[TOC]
Pytorch的DDP指的是DistributedDataParallel,位于torch.nn.parallel中,用于多GPU的模型训练。相比于之前的DP,DDP的速度快了很多。DDP支持多卡多机器,但我没有多机器,所以本文针对最常用的单机器多卡。
原理
DDP加速的原理是通过启动多个进程,提高同时训练的batch size来增加并行度的,每一个进程都会加载一个模型,用不同的数据进行训练之后得到各自的梯度,然后通过Ring-Reduce算法获得所有进程的梯度,然后进行相同的梯度下降。注意在训练前和训练后,所有进程的模型参数都是同步了的。
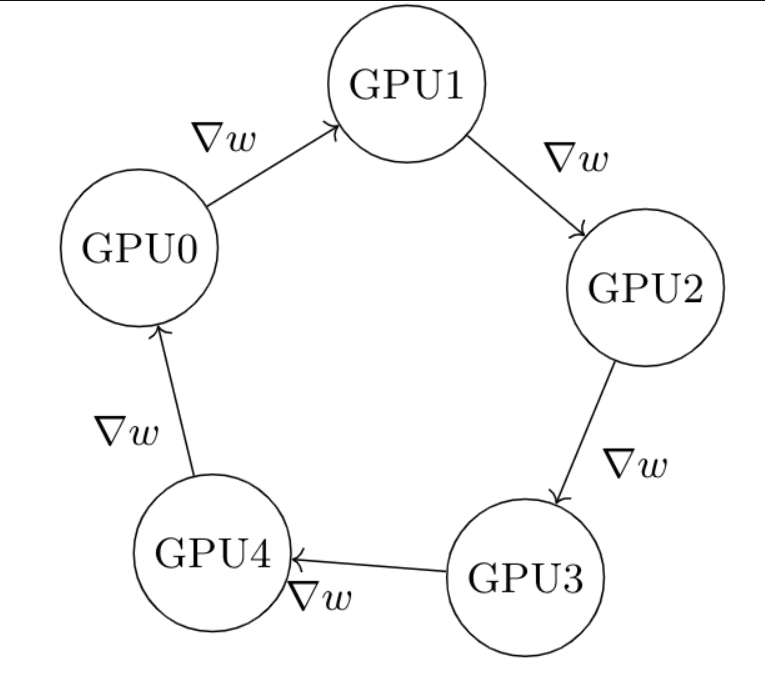
Ring-Reduce是很简单理解的一个算法:每个进程都从左手边获得一份梯度,然后从右手发送一份梯度(一份指的是一个GPU得出的梯度),经过次迭代之后,所有进程都获得了相同的完整的梯度。如下图,假设梯度是GPU0算出来的,第一次被发送到GPU1,第二次被GPU1发送到GPU2,第三次被GPU2发送到GPU3,第四次被发送到GPU4,第五次被发回给GPU0。这样每个进程都只需要接收一个,发送一个,而且能够清楚知道什么时候结束。
基础概念
先来了解基础概念:
world_size:并行数,即总共用的卡数。rank:当前进程全局序号,范围0~world_size。local_rank:本地序号,由于本文介绍单机器,所以和上面一样。master_port:DDP需要进程间传递数据,所以需要使用端口。master_address:同上,需要使用IP地址。
使用方法
基本逻辑是这样:
graph
A[初始化多进程并获取rank号]-->B[使用DistributedSampler提供数据]
B --> C[将数据和模型都放在GPU上]
C --> D[将模型用DDP包裹]
D --> E[训练]
E --> F[loss.backward同步梯度]
F --> G[保存参数]
初始化多进程、获取rank号
1 | |
数据
对于张卡上的个模型,我们当然希望将数据分成不同的部分,分别送给它们训练,所以需要使用torch.utils.data.distributed.DistributedSampler帮助我们自动分配数据。
**注意!只有训练集才要用Sampler!**在train之后,经常使用验证集对数据集进行验证得到validation_loss,此时没有必要使用多卡,只需要在一个进程上进行验证。
在多卡模式下要进行只在一个进程上的操作,通过
model.module(inputs)而不是model(inputs)来调用forward()前向传播,而其他进程通过torch.distributed.barrier()来等待主进程完成validate操作。假如要多卡推理,参考这篇文章写一个新的sampler[原创][深度][PyTorch] DDP系列第三篇:实战与技巧 - 知乎 (zhihu.com)
1 | |
把数据和模型放在GPU上
1 | |
把模型用DDP包裹
1 | |
训练、同步梯度
1 | |
保存参数
1 | |
运行
1 | |
DDP注意点复习!
- 要把模型和数据放在进程对应的那张卡上
- 要使用Sampler来分发训练数据,并且shuffle不设置在Dataloder中而是Sampler中,每个epoch还需要调用Sampler的
set_epoch()方法。 - 训练和验证区分较大,验证一般在主进程中进行一次验证即可,不需要sampler,操作和单卡一样,之后将数据同步给其他进程。
- 在多卡时要调用模型的其他方法或者使用单卡的模式,需要用
model.module来获得原始模型,同样保存参数时也保存的是model.module的参数而不是DDP包裹的。
DDP小技巧
数据同步
使用dist.all_reduce(loss, op=dist.ReduceOp.SUM)可以同步tensor的数据,由于算法限制,要算平均值只能用求和运算dist.ReduceOp.SUM之后再除以world_size。
假如要同步的不是tensor,可以创建Tensor然后放进对应的GPU,再同步。
假如需要获得每个进程的某个tensor的值(即有n个GPU就获得n个值),那么使用dist.all_gather可以获得tensor列表。
1 | |
同步数据时假如要控制所有进程同时,可以使用torch.distributed.barrier(),让快的进程等一下慢的进程,假如timeout了,可以看看代码是否能优化,或者在运行之前提供参数提高timeout的值。
假如dist.barrier()失效,可能是这种情况DistributedDataParallel barrier doesn’t work as expected during evaluation - distributed - PyTorch Forums
参考文献:
[原创][深度][PyTorch] DDP系列第一篇:入门教程 - 知乎 (zhihu.com)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!