Object Relational Graph with Teacher Recommended Learning for Video Captioning论文笔记
本文最后更新于:2023年2月8日 下午
Object Relational Graph with Teacher-Recommended Learning for Video Captioning论文笔记
[TOC]
占据paperswithcode.comMSRVTT数据集VideoCaption任务榜一的文章,发表在CVPR2020上。论文主要贡献是一个Object Relational Graph(ORG)编码器和一种Teacher Recommended Learning(TRL)训练方式。
整体框架
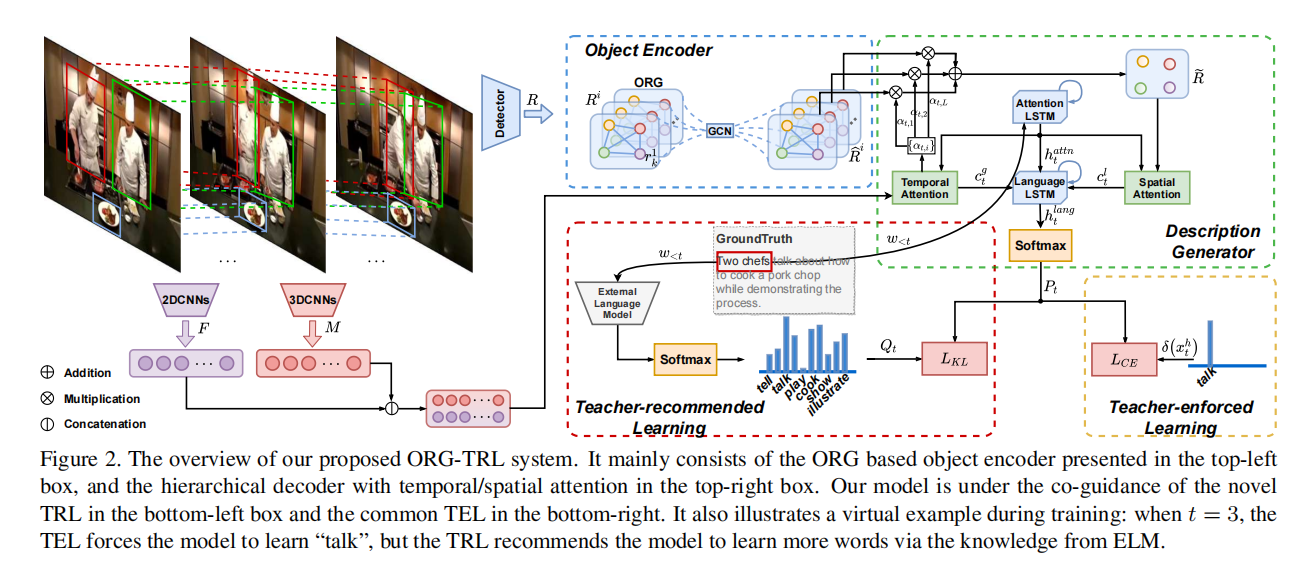
这篇论文使用了2D-CNN 3D-CNN和Object三种特征,其中Object特征通过图神经网络ORG学习到特征,然后Description Generator通过对三种特征的注意力机制,通过TRL生成句子。
Object Relational Graph编码器
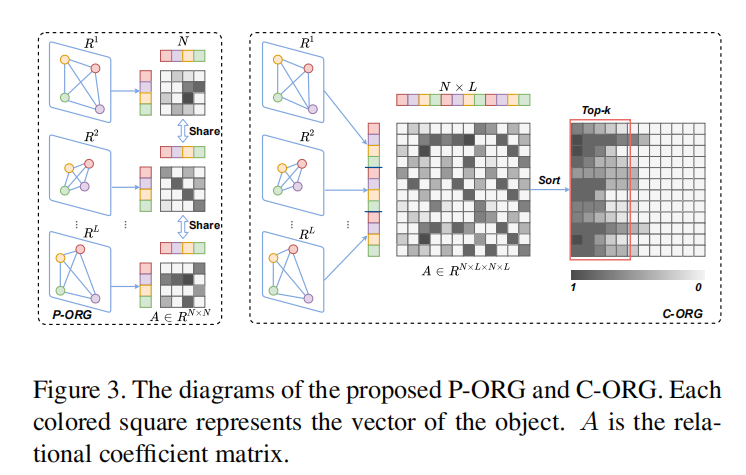
对于视频,提取个关键帧,通过2D-CNN和3D-CNN得到特征,通过预训练的object-detector得到特征,表示第帧第个object的特征,最多个特征,object层面的特征相互是独立的。
对于d维的Object特征,K个特征可以表示为的矩阵,定义为关系矩阵,其中是两个可学习的线性层,将归一化之后可以得到,类似注意力矩阵,表示每一个object对于其它object有多少的注意力。之后乘上参数和原本的特征得到加强特征。
对于关系矩阵的获取,这篇文章用了两种方法,一种是帧内的(P-ORG),另一种是全局的(C-ORG)P-ORG选择帧内的个object,编码他们之间的关系,不同帧的参数是共享的;C-ORG选择全部的个object,但是会筛选出top-k个object来减少复杂度。
Description Generation解码器
解码器部分由attn解码器和language解码器组成:
attn解码器使用LSTM网络,是降维掉时间轴的全局视频特征,是前一个生成的单词,是language解码器的上一步hidden变量。
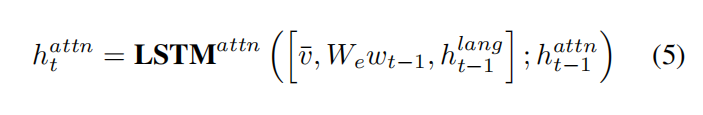
然后通过输入和得到施加注意力之后的整个视频的特征。
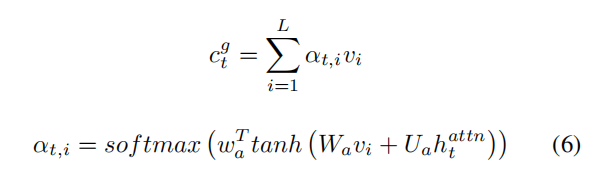
对于Object层面的特征,也使用注意力机制得到local特征。
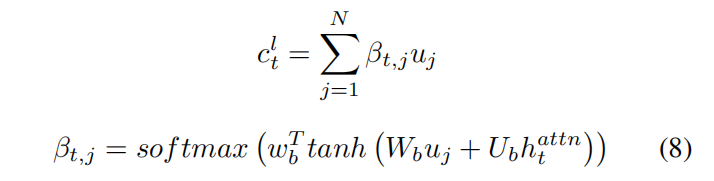
最后送入language解码器,得到输出。
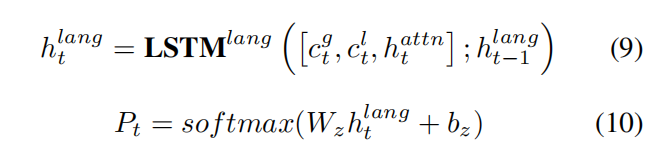
Teacher Recommend Learning(TRL)
其他的方法在生成句子的时候是期望生成Ground Truth的句子,而Ground Truth是固定的。
而TRL借助外部知识源ELM(Bert或者GPT)得到一个新的概率分布,这里有一个temperature来平滑这个概率分布。
因为中有的单词概率实在是太小,所以不管那些单词,计算KL-loss。
最终loss是两个值相加。
2023.2 意外发现一篇论文和这一部分很像,不过用的是文本的共现概率。
实验结果
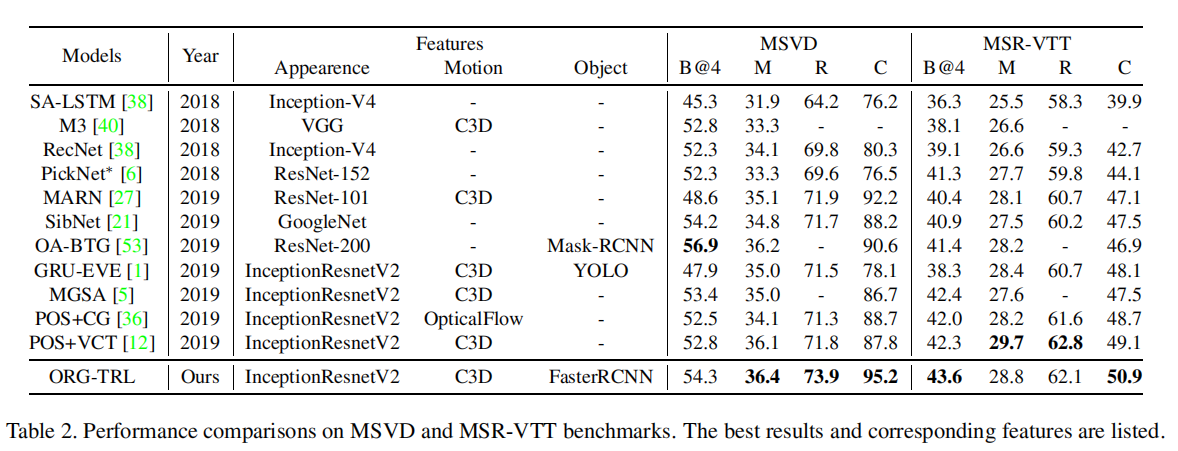
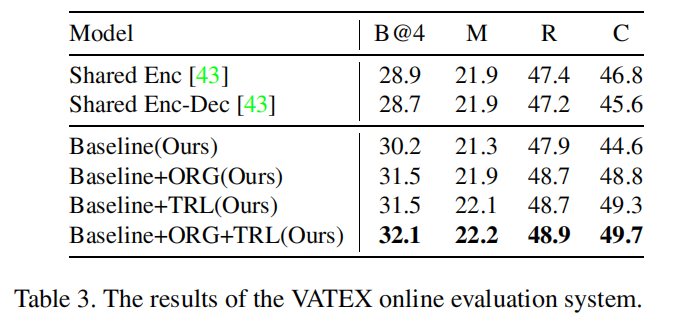
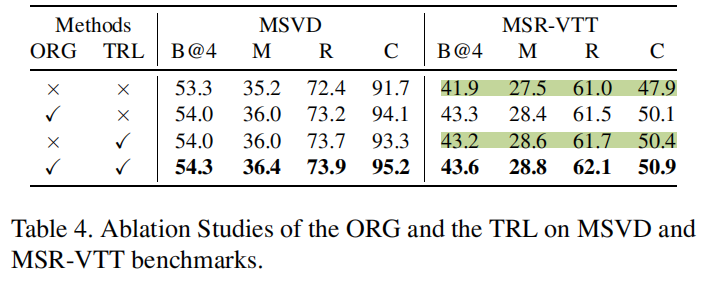

Table3和Table4可以看出TRL贡献了非常多,超过了ORG部分的贡献量。Figure 6也很直观让人感受到TRL的厉害hh。TRL算是在最后的决策部分结合大规模预训练语言模型,效果显著。
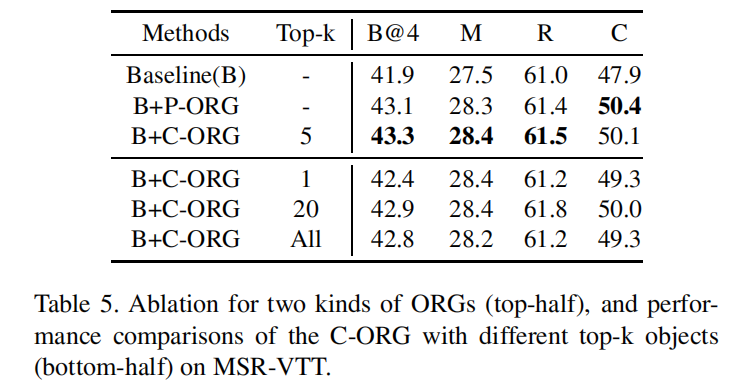
仅使用帧内Object和跨帧Object的差距并不是很大。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!