Hierarchical Modular Network for Video Captioning论文笔记
本文最后更新于:2022年7月21日 下午
Hierarchical Modular Network for Video Captioning论文笔记
[TOC]
论文于2021年11月24日发表在了ArXiv上,提出了一个用来进行Video Captioning任务的分层网络,从实体(Entitiy)、动词(Predicate)、句子(Sentence)三个层次来进行建模。其中作者在Entity的部分贡献更大,提出了一个仿照DETR的模块。结果在MSVD和MSR-VTT上SOTA了。
没有放出代码
总体框架
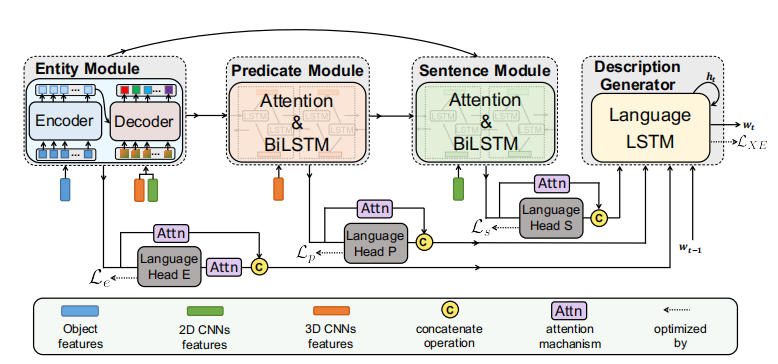
实体模块(Entity)
这个模块的输入特征由三部分组成,第一部分是Object feature,第二部分是2D-CNN feature,第三部分是3D-CNN feature。
其中Object使用Fast RCNN提取,先从视频中选择个关键帧(keyframe),从中总共检测出个objects,每个object的特征维度为。在作者的实现中,视频被分成了15个clip,每个clip有16帧,每个clip选出一帧作为关键帧,检测10个objects,并且预训练模型在Visual Genome数据集上训练。而2D-CNN使用InceptionResNetV2提取特征,3D-CNN使用C3D提取特征。以上特征都被全连映射到。
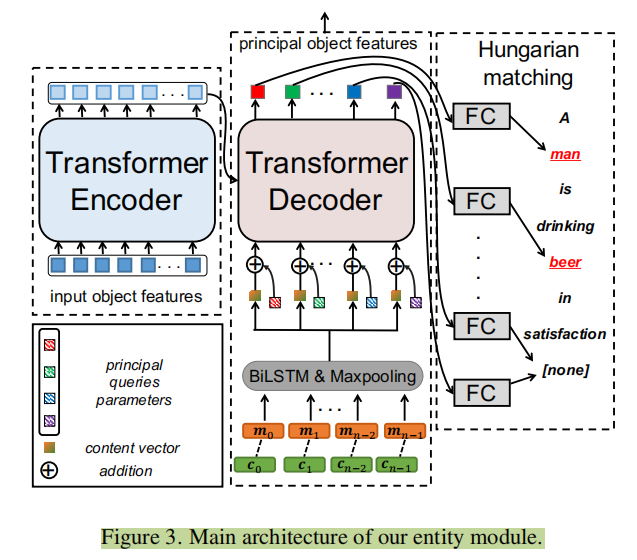
如图,object特征先送入Transformer的编码器得到特征(不做position encoding)。而2D-CNN和3D-CNN的特征在特征轴拼接之后送入双向LSTM网络再最大池化得到代表整个视频的特征。仿照DETR,论文还加上了长度为的随机初始化参数,作为解码器的target输入。解码器输出,再通过全连得到,的维度是SBERT模型的维度。
为了监督学习,论文用SBERT提取caption中的名词的特征(去掉无意义的),然后用DETR中的Hungarian algorithm匹配名词特征与object特征,计算余弦相似度作为loss:。
动词模块(Predicate)
这个模块就是一个添加Attention的BiLSTM,运动特征和目标特征作为输入,通过注意力机制得到运动关联的目标特征,然后拼接和送入LSTM得到动作特征,然后对它最大池化消除时间轴维度,再送入全连把特征维度改成,得到。
为了监督学习,论文用SBERT提取caption中的动词的特征(去掉无意义的),计算余弦相似度作为loss:。
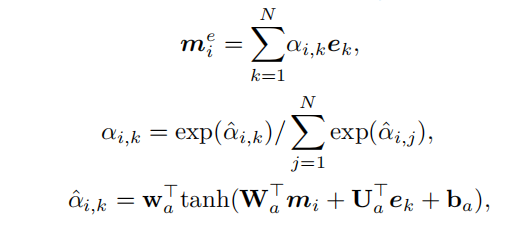
句子模块(Sentence)
这个模块是学习视频整体特征和句子语言特征的。输入2D-CNN特征、内容关联的动作特征和内容关联的目标特征。(xx关联指的是对xx使用注意力机制)
上面三者在特征维度拼接,送入双向LSTM得到全局视频特征。同样,最大池化消除时间轴,再送入全连转换成,特征维度为。然后用SBERT提取整个句子的特征,计算余弦相似度作为loss:。
句子生成模块(Description Generation)
这一部分就是使用LSTM进行句子的生成,输入比较多,如下:

这里面是前一个预测单词的embedding,是隐藏,重点在于前面三个。三者分别代表整个视频的特征、运动特征和目标特征。
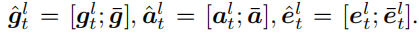
三个如上是拼接而来的,是之前获得过的视频总特征和运动总特征,而的变量都是用注意力机制得来的,从左到右分别是对的加权求和,权由和他们自己得到,如下图。

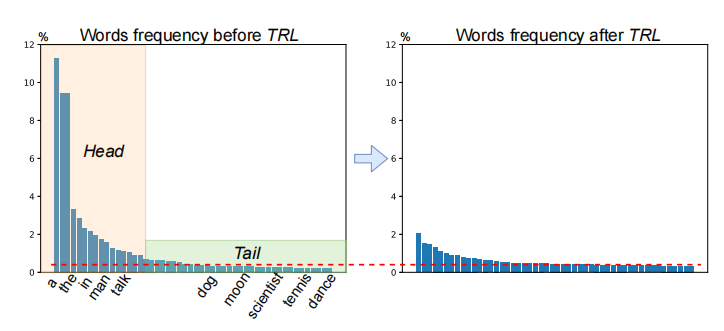
Loss使用了带ELM的交叉熵,ELM在论文Object Relational Graph with Teacher-Recommended Learning for Video Captioning中提到,引入外部语言模型来解决long-tail问题。(就是改变了一下分布)
实验结果
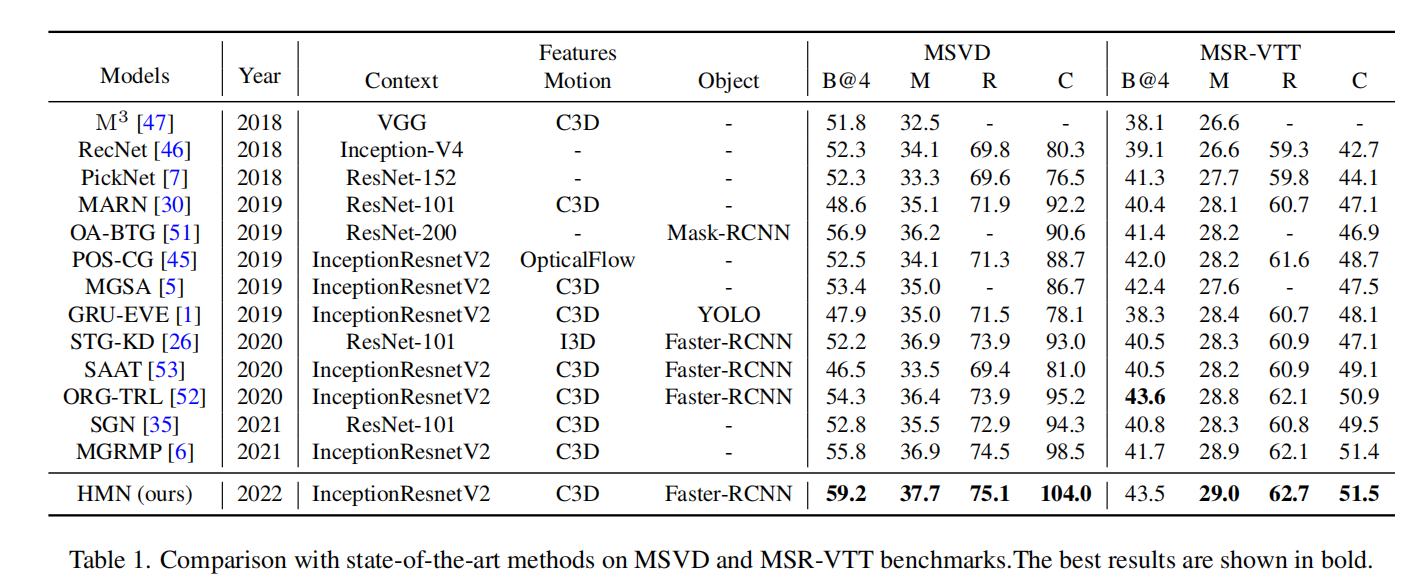
比ORG-TRL高了一点点。
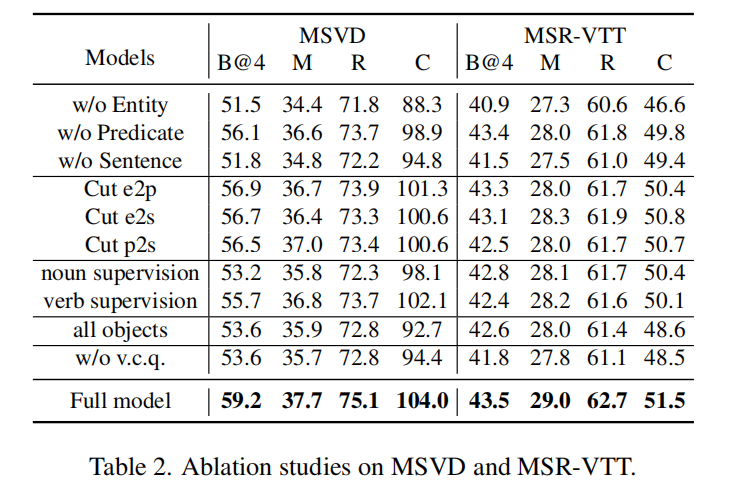
总结
这玩意太不优雅了,注意力机制可算是给他弄明白了hhhh。
而且没有做关于引入外部语言模型的消融实验,在Object Relational Graph with Teacher-Recommended Learning for Video Captioning中TRL加上已经能达到Meteor28.6的程度了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!