CLIP4Caption论文笔记
本文最后更新于:2022年7月21日 下午
CLIP4Caption论文笔记
[TOC]
论文:CLIP4Caption: CLIP for Video Caption
网址:CLIP4Caption: CLIP for Video Caption (acm.org)、https://doi.org/10.1145/3474085.3479207
代码:无
这篇2021年10月发布在MM’21的论文提出了一个基于CLIP、CLIP4CLIP(1)和Uni-VL的模型,用来做视频描述任务(Video Captioning),效果拔群,METEOR和CIDEr指标都是SOTA。文章主要想利用已有的vision-language预训练模型来帮助下游任务。同时文章还提出了一种集成学习方法,效果也有提升。作者还发了一篇CLIP4Caption++: Multi-CLIP for Video Caption主要在VATEX数据集上实验,并且添加了subtitle的多模态,放在另一篇文章中讲吧.。
整体架构
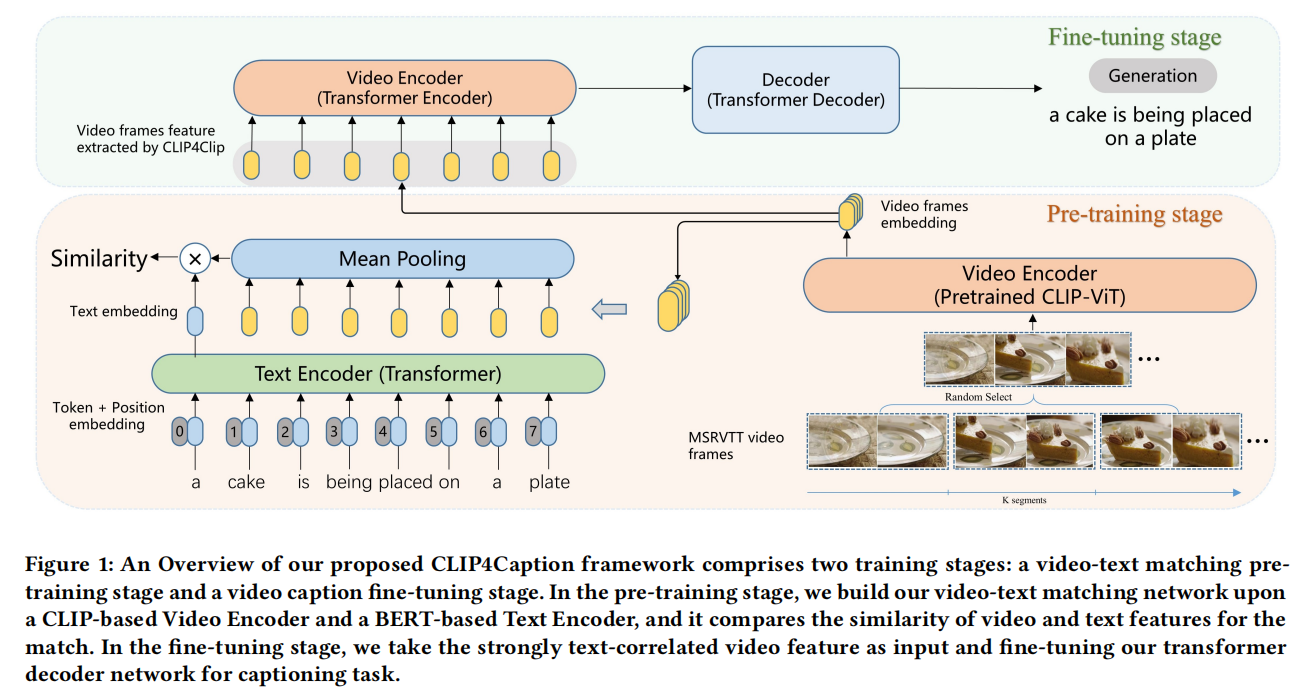
模型分成两部分——预训练阶段和微调阶段,预训练阶段就是用CLIP4clip的方式在MSR-VTT数据集上进行视频检索任务的学习,这一部分要非常多的算力资源,目的是训练出一个更强大的CLIP Video Encoder。微调阶段就是用Transformer的Seq2seq架构,以CLIP video特征作为输入来训练,其中Decoder用Uni-VL(2)的Caption Generation任务的Decoder的权重进行初始化。
Video-Text匹配预训练
这一部分被作者叫做video-text matching network (VTM),本文使用了TSN的帧取样方法,K是超参数,作者在之后有对比实验,并且分成K份后从每份里只抽1帧。
TSN sampling (3)
假设原视频是V,现在把V分成K份(原文K=3)得到{S1 ,S2,S3},然后又从Sk中随机采样n帧(令n=1),得到snippets:{T1 ,T2,T3}。
训练完全仿照CLIP4Clip,Loss使用symmetric cross entropy loss
训练方式是在一个Batch内进行匹配,一个text对所有video进行相似度计算,然后能得出匹配的概率分布,同时也有真实分布,即输入的pair是1,batch内构成的其他pair是0,t2v同理。
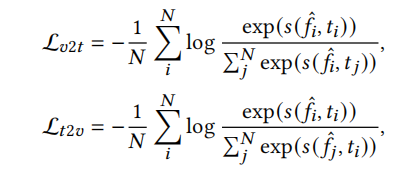
注意这个loss和Symmetric Cross Entropy for Robust Learning with Noisy Labels, ICCV2019提出的loss同名,但不是同一个loss!
Video Captioning训练
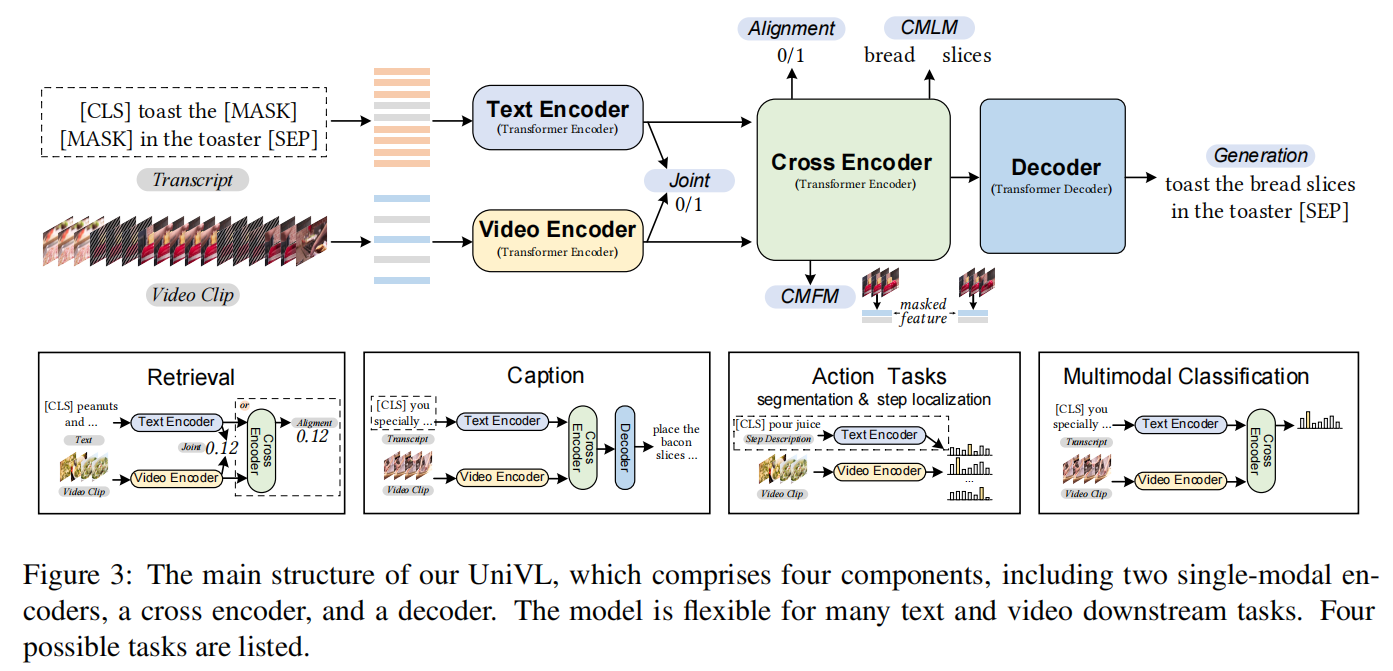
文章使用了Uni-VL的部分权重,本文使用的是1层的Transformer Encoder和3层12头768的Transformer Decoder。(Decoder还好,但是暂时没懂这篇论文加载的是Uni-VL哪里的Encoder)
Ensemble strategy
文章训练出了多个模型来集成学习,多个模型之间通过voting来决定最终输出,而每个模型的权重由一个综合的metric来决定。将METEOR、BLEU等metric归一化后取平均就是综合metric。通过统计哪个模型更接近真实值,哪个模型更不接近可以得出importance score,就是每个模型的权重。
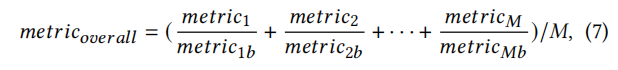
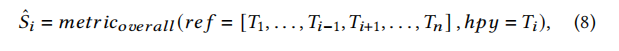
结果分析
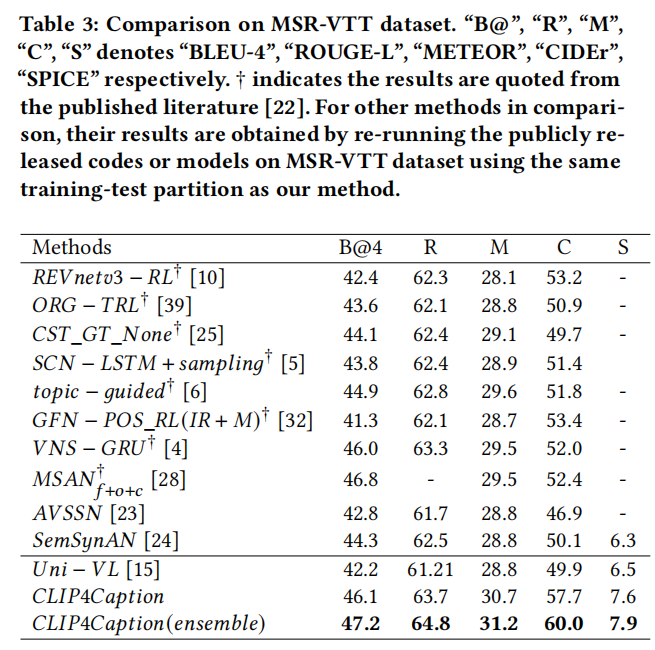
在MSR-VTT上的效果绝对SOTA了,之前没有论文METEOR超过30,去掉Ensemble也有31.2了,而且这还只是单模态的使用。
参考文献
Clip4clip: An empirical study of clip for end to end video clip retrievalUnivl: A unified video and language pre-training model for multimodal understanding and generationTemporal Segment Networks: Towards Good Practices for Deep Action Recognition
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!