Video Captioning任务 Transformer方向小综述
本文最后更新于:2022年7月21日 下午
Video Captioning任务 Transformer方向小综述
[TOC]
涉及的论文
TVT: Two-View Transformer Network for Video CaptioningA Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal TransformerSBAT: Video Captioning with Sparse Boundary-Aware TransformerMulti-modal Dense Video CaptioningiPerceive: Applying Common-Sense Reasoning to Multi-Modal Dense Video Captioning and Video Question AnsweringActBERT: Learning Global-Local Video-Text RepresentationsMulti-modal Transformer for Video RetrievalReconstruction network for video captioningSpatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video CaptioningCLIP4Caption: CLIP for Video Caption
Baseline
图来自文献1,基于Transformer的Video Captioning任务基本都是这种模式,可以叫做Vanilla Transformer、Base Model architecture。
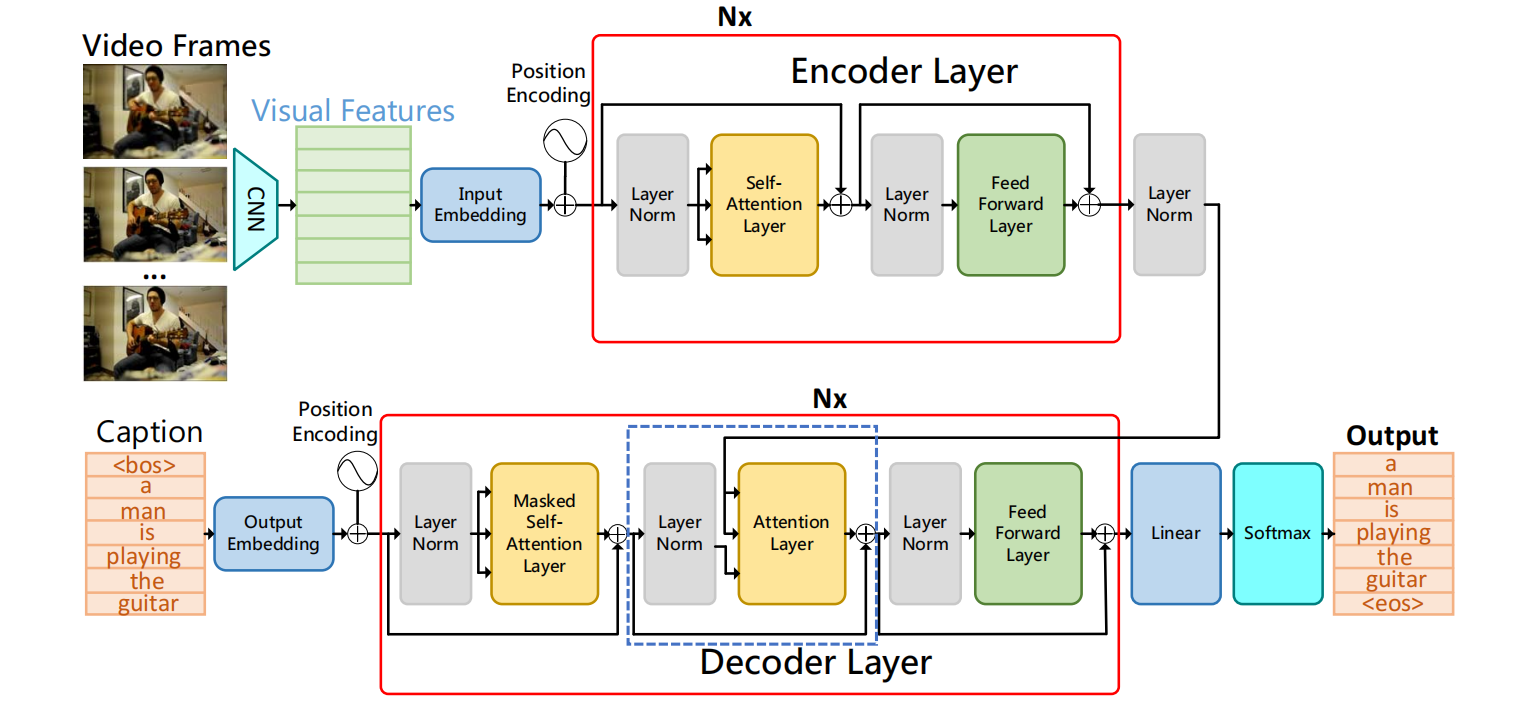
多模态特征融合
本任务使用的多模态特征包括rgb(image, frame, 不含时序信息)、motion(动作)、object(目标检测)、voice(音频)、speech(音频中人说的话)。其中RGB必备,还有很多选择motion和voice的。
文献1,2,3都使用了多种模态的特征,本节对于特征的融合进行归纳总结。
文献1 TVT Attentive-fusion block
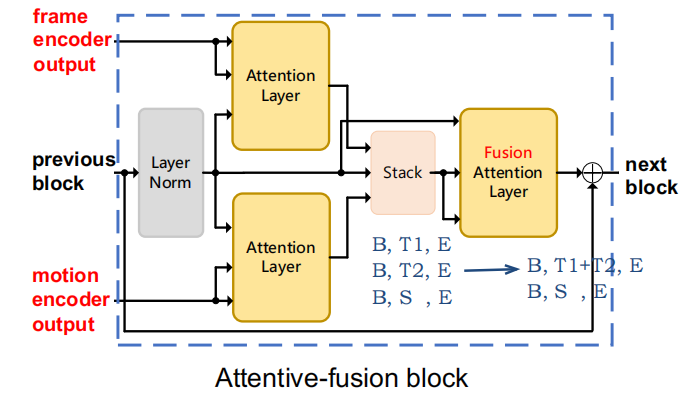
文献1对多种特征进行独立的Transformer encode,得到的输出是图中红色的frame encoder output和motion encoder output,它对Transformer decoder的中间那个SA层进行了改进。
图中3个SA层的Q都是和Baseline的Caption那一路的特征,先分配好frame的注意力,同时分配好motion的注意力,之后在时间轴堆叠,再分配好堆叠后的注意力。
文献2 Bi-modal Transformer
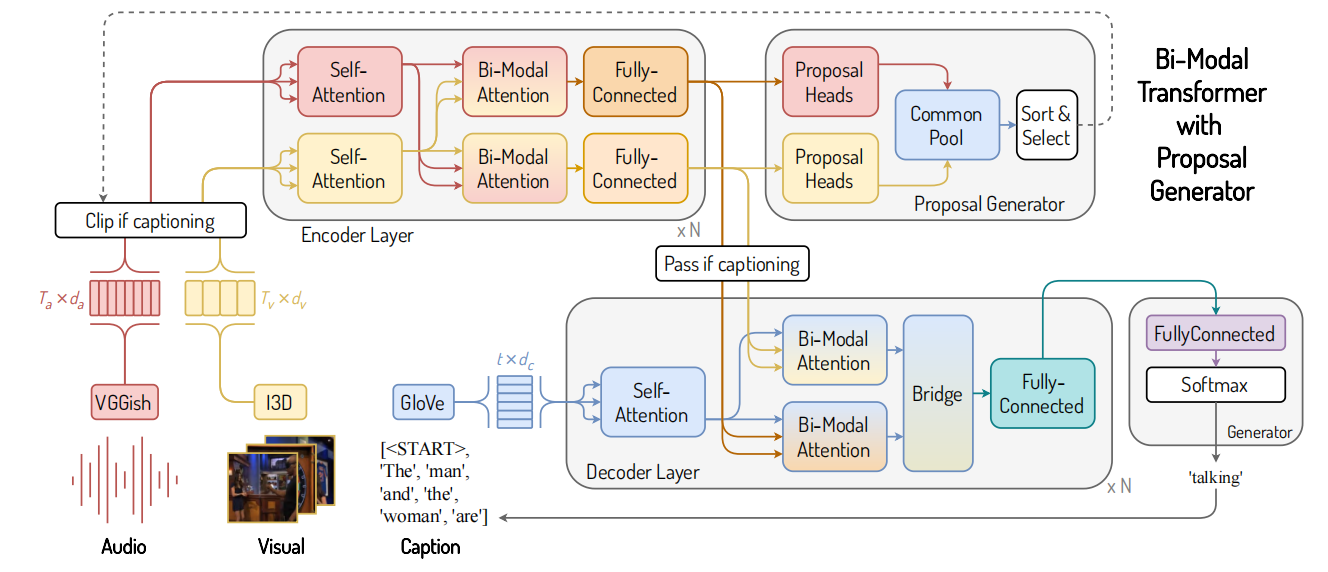
这篇论文任务其实是Dense Video Captioning,但是去掉Proposal Generator也是一个Video Captioning的模型。它不仅在Decoder进行了特征融合,还在Encoder进行特类似的特征融合。
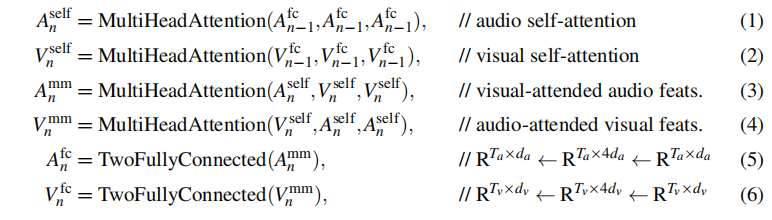
编码阶段如上图,每一个Encoder层进行完Baseline的SA层后,再进行一个交叉的Bi-Modal Attention,然后Feed forward。

解码阶段如上图,Baseline的中间SA层也改成类似的Bi-Modal Attention,然后Bridge是直接用全连接层把concat起来的特征降维。
解码阶段模态融合方法和文献1的区别就是concat后的张量用SA还是用全连来降维
文献3 SBAT Cross-Modal
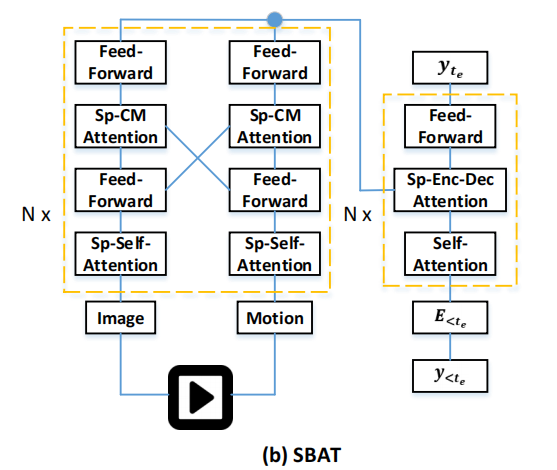
这篇论文是只在Encoder上做了特征融合,用的类似文献2的方法,但是在一个Encoder层的第一个SA层后又加了个Feed forward,参数更多了。
文献4 MDVC & 文献5 iPerceive
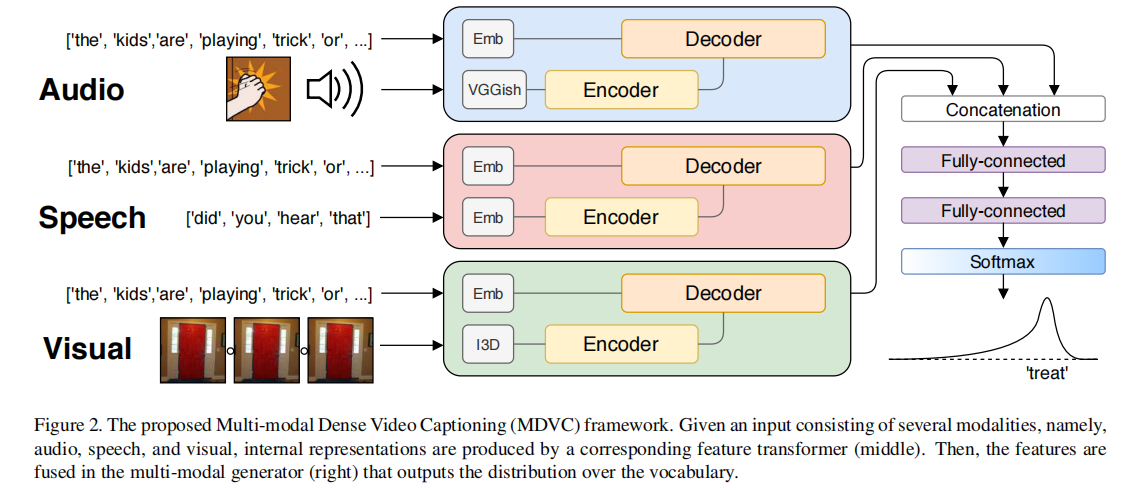
和文献2是同一个作者,这是更早的文章。算是直接train出3个Transformer,然后在最后全连决策的时候进行特征融合。文献5的方法和这个几乎一模一样。
文献6 ActBERT
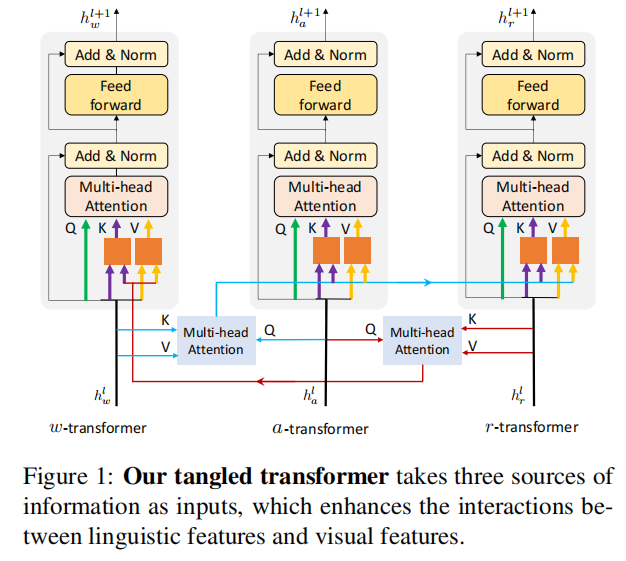
这种特征融合就很迷惑了……还没看懂。
文章说这种方法对于、和三种模态是不相等的。的KV一部分来源于本身,另一部分来源于用和进行SA的结果,两部分特征用全连降维。的KV和一样。但是的就很奇怪了,只融合了的特征?
文献7 MMT
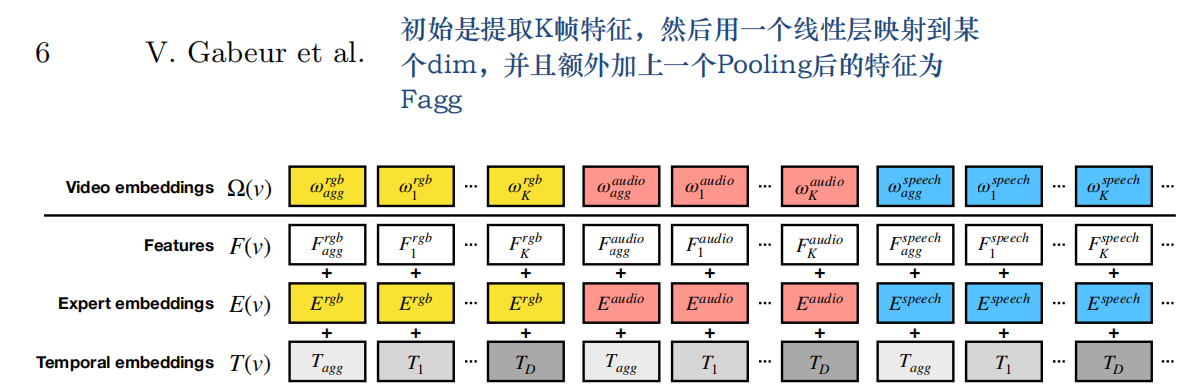
这种特征融合方法解决了文献2、3中方法不能拓展到三个及以上特征的问题,但是会导致时间维度较大。
这里就是先把多种特征先弄成同一特征维(时间维可不同),然后加上时序信息的Temporal embeddings和区分不同特征的expert embeddings,文章还给每一种特征增加了一个agg特征,这是对每一种特征的时序进行pooling得到的Global信息。
总结
在Encoder的特征融合中,文献2、3都没有做到融合第三种特征,因为使用三种特征后会出现六路encoder输出。
在Decoder的特征融合中,方法都类似,区别是用全连或者SA降维。
榜单
MSR-VTT
| 方法 | METEOR | ROUGH | CIDEr | Bleu@4 |
|---|---|---|---|---|
| SBAT(3) | 28.9 | 61.5 | 51.6 | 42.9 |
| att-TVT(N+I+V)(1) | 28.2 | 61.1 | 48.5 | 42.5 |
| att-TVT(N+I)(1) | 27.9 | 59.6 | 47.7 | 40.1 |
| RecNet(8) | 26.6 | 59.3 | 42.7 | 39.1 |
| GRU-EVE(9) | 28.4 | 60.7 | 48.1 | 38.3 |
| CLIP4Caption(10) | 30.7 | 63.7 | 57.7 | 46.1 |
VATEX
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!