Video Swin Transformer
本文最后更新于:2022年7月21日 下午
Video Swin Transformer
[TOC]
简介
Swin Transformer分为两篇论文,一篇是21年5月的Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,另一篇是21年6月的Video Swin Transformer。其中Swin Transformer是对ViT的改进,使用分层的Transformer和偏移窗(shifted window)来提升效果并节约算力。Video Swin Transformer则是像3D-CNN对于CNN的改进一样,Video Swin Transformer将这种方法拓展到了视频上,为同一个团队研究成果。
模型基本结构
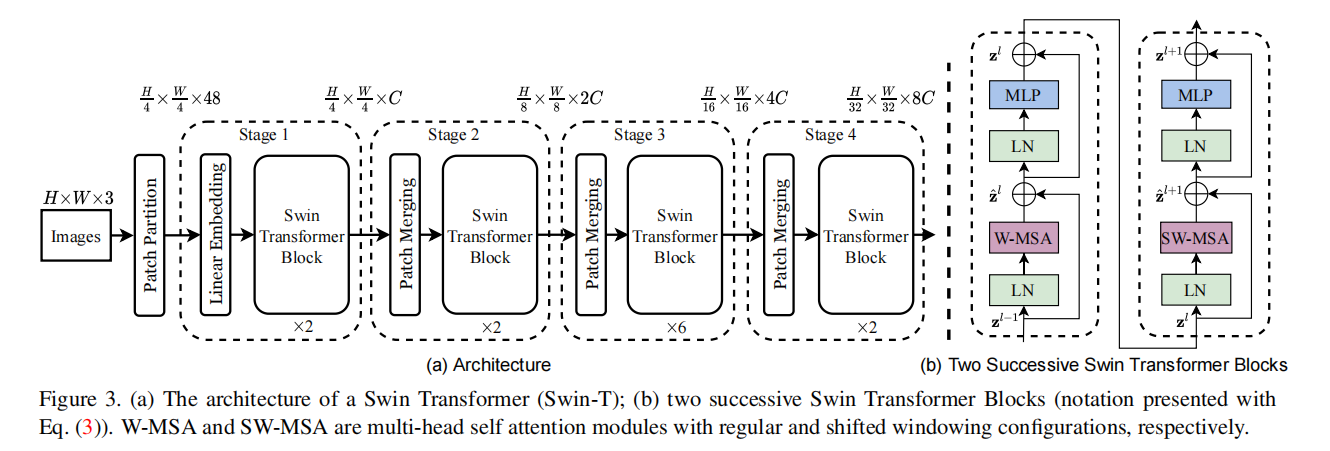
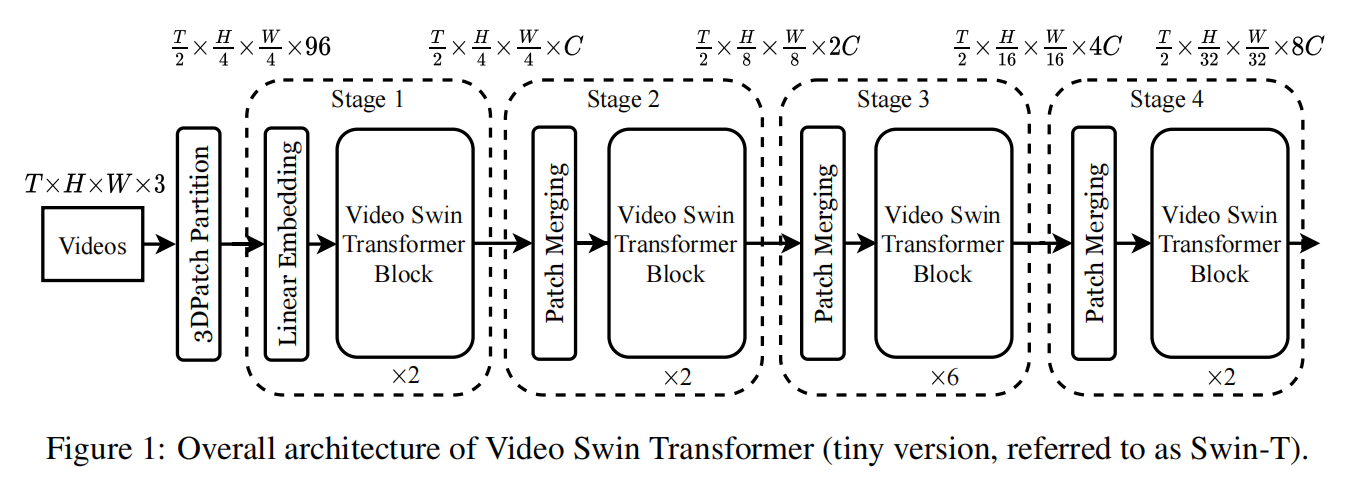
第一张图是处理图像的Swin Transformer,第二行图是处理视频的Video Swin Transformer,以图像为例:
- 初始的是RGB图片三通道,经过Patch Partition之后,每16个像素合成一个Patch,此时维度变成,
- 再经过一个**全连(Linear Embedding)**控制通道的维度为可变值C,此时维度为。
- 之后每个Stage还会有个Patch Merging层,将4个Patch合成一个新的Patch,所以分辨率又下降了,再进行全连来控制通道维度为,此时维度变为。
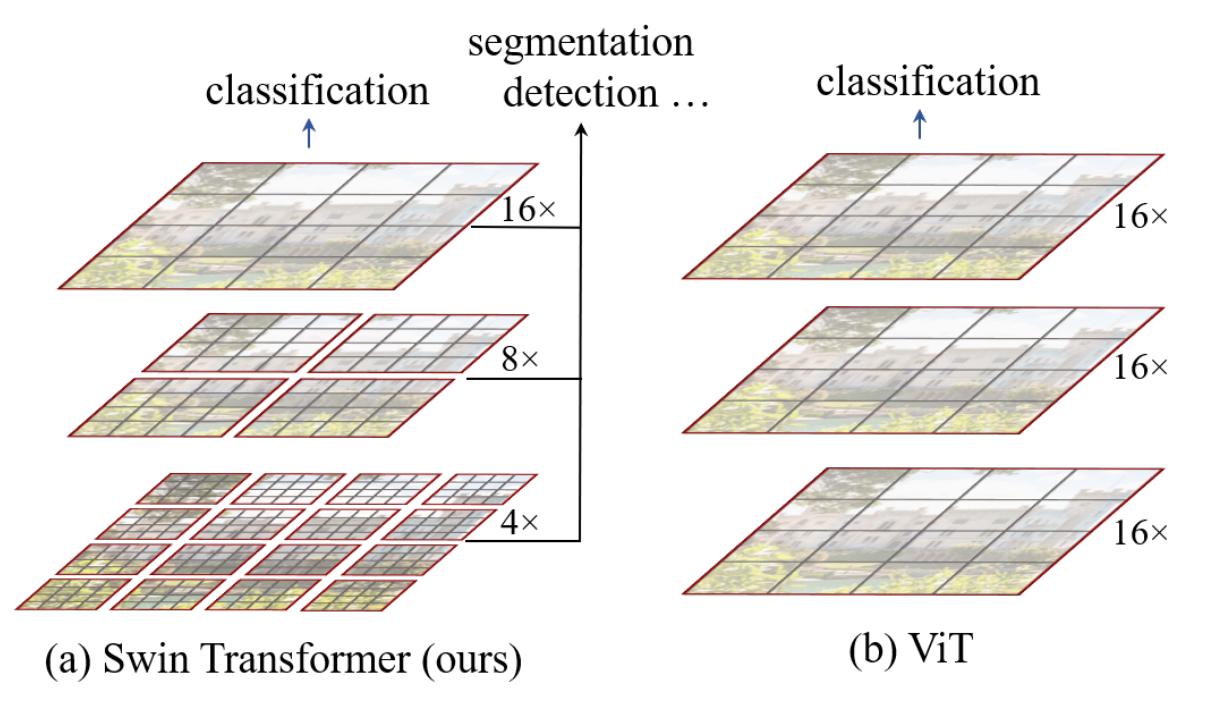
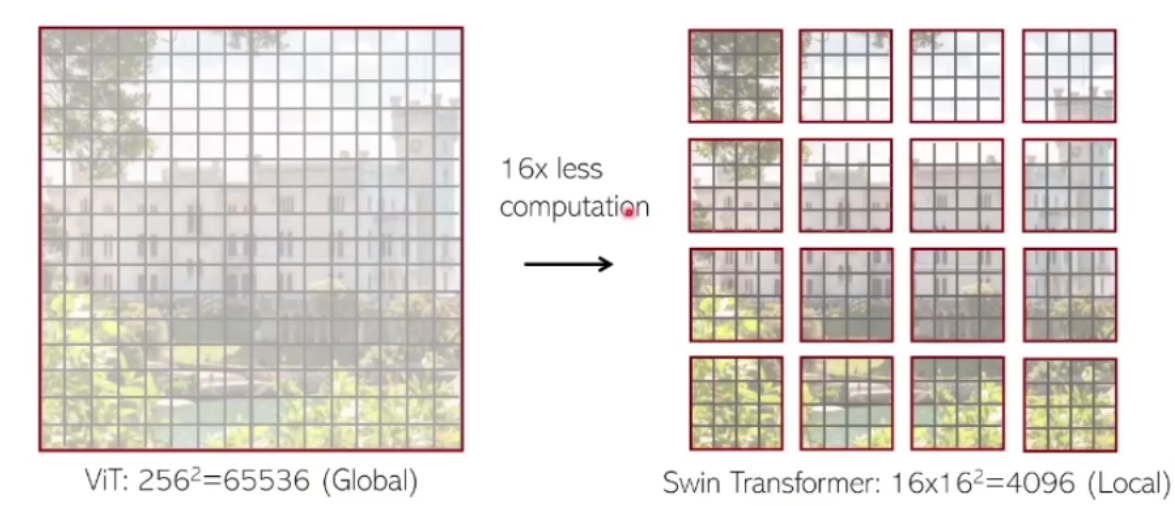
这一步是Hierarchical的体现,模仿的是ResNet和其他CNN,不断缩小图像并加深channel。如上图,好处就是比较ViT能够对更细微的Local特征进行学习,并能减少需要的算力。
Swin Transformer block
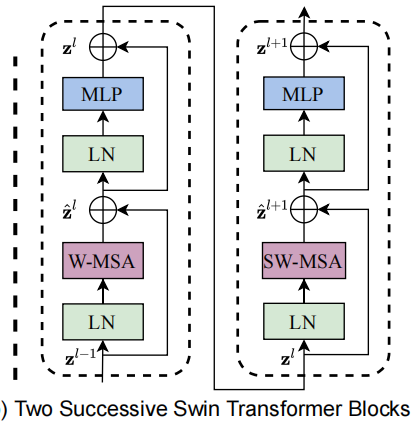
这就是一个Swin Transformer Block,由LN(Layer Normalization)、MLP(多层感知器)、MSA(多头self-attention)组成,其中MSA有window和shifted-window两种。
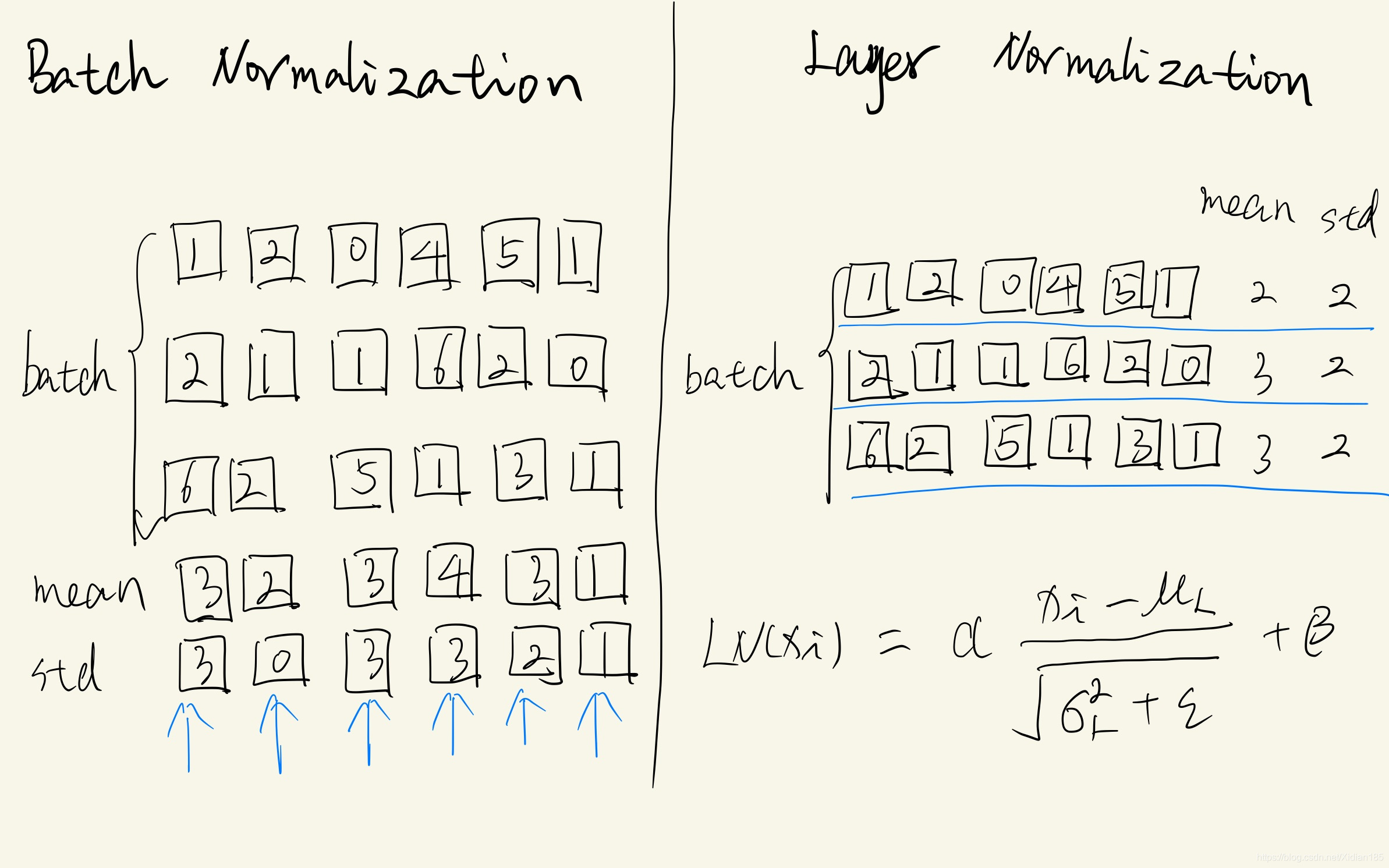
LN就是与batch无关的标准化,用均值和标准方差对数据进行标准化处理,如下图。Transformer代码详解与项目实战之Layer Normalization_Xidian185的专栏-CSDN博客
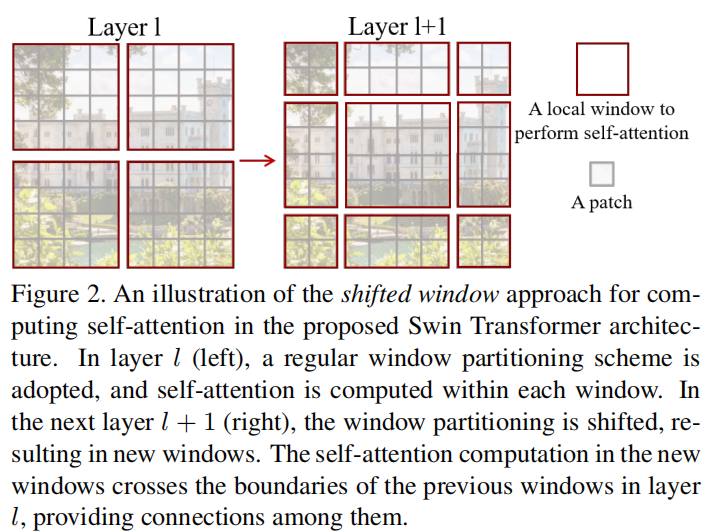
W-MSA是在一个window里的自注意力模块,图中每个灰色小方格都是由若干像素组成的,用来计算self-attention的最小处理单位。在W-MSA里可以通过指定window大小来在小范围进行self-attention。两个MSA的不同之处在于有没有shifted window,如图。这种shift是将整体往右下循环移动(2, 2),左上角的4x4就到了中间,右下角的4x4就分到了四个角。虽然window的数量从4变成了9,但是作者在算法上证明了这两种需要算力相同。

相对位置偏置(relative position bias)
self-attention的原始公式是
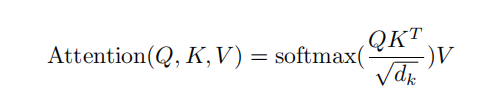
swin-transformer里面改成了这样
通过增加一个Bias来体现一个window内不同patch的相对位置(local),类似Transformer里的Positional-Encoding。
对于二维的swin-transformer,,即结果和dim无关,是原特征的各维度相乘,Attention张量形状为(M*B, num_heads, M*M, M*M),也就是说,我们需要一个类似的矩阵B。
下面结合二维Transformer源码来理解,假设。
首先形成relative_position可学习参数,用0初始化。
1 | |
构建每个点的坐标coords,总共16个二维坐标。
1 | |
获取relative_position_index。
1 | |
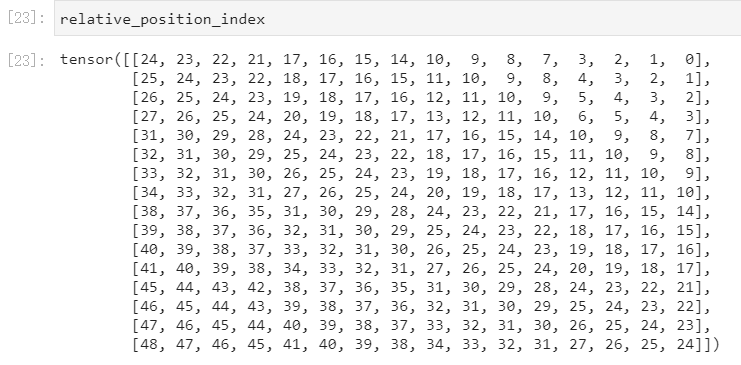
relative_position_index的范围是0~48,即49种数,对应relative_position_bias_table的49,dH。这个table就是相对位置编码,每个数就是偏移量,值为0的和值为1的相对距离就是1,对应着不同的bias。
在forward中的(部分)代码如下
1 | |
预训练模型

作者调出了4种大小的模型。
Video Swin Transformer用Swin Transformer进行初始化
略
最终能得到的
Video Swin Transformer
简介
相比于图像的,多了T轴,Patch等元素也都变成3D的了。
shifted window

token可以看作是最基本的像素,红色透明立方体是窗,为了减少计算量,swin transformer在单独的窗内计算self-attention而不是在整张图。
通过两种window来链接不同的token,这两种的计算效率经过验证是一样的。
模型类型
作者train出了这么几个

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!