如何构建数据集?大佬们都这么干的……
本文最后更新于:2021年10月23日 下午
如何构建数据集?大佬们都这么干的……
当下深度学习对数据的要求越来越高,更好的数据往往就能训练出更好的模型,为了得到更好的数据,各路大佬们都绞尽脑汁,本文将介绍5种不同的构建数据集的方法。
从最普通的开始吧——MNIST
MNIST数据集由2018年图灵奖得主、CNN之父——Yann LeCun大佬收集得到,包含数万个20x20的手写数字图片组成,一般用在机器学习识别手写数字的任务上,学习卷积神经网络的人大部分都从这个数据集入门的。

LeCun大佬收集数据的方式很简单,先是从500位高中生中收集到了58,527个图像,这就是SD-1数据集,但是这样数据来源不够随机,所以后面又从人口普查局的员工中抽选了250个人构建了SD-3数据集,把这两个数据集混合之后,构成了MNIST数据集。虽然没有特别说明,但是人口普查局的员工大概是分布在各个地方的,而且混合了成人和高中生的数据集也更加精确。
构建数据集方法1 Get√👍:
找一堆工具人创造数据、标记数据。
优点:想要啥就有啥
缺点:假如要获取海量数据,成本就非常非常非常高
自动化获取数据——网络爬虫
目前的大规模数据集基本都离不开网络爬虫,通过网络爬虫,可以自动化获取存在于互联网上的海量数据,比如用于图像识别的ImageNet数据集、用于视频描述的MSR-VTT数据集、用于动作识别的Kinetics数据集等等。
包含视频文件的Kinetics和MSR-VTT数据集都是使用网络爬虫在YouTube上搜索关键字爬取到视频数据的,假如你也想用这种方式构建自己的数据集,可以使用这个工具或者这个带界面的工具。
构建数据集方法2 Get√👍:
用网络爬虫获取数据,但是还是得找一堆工具人标记数据。
优点:能获取到很多数据
缺点:标注成本很高
找不到那么多工具人——那就众包吧
众包指的是一个公司或机构把过去由员工执行的工作任务,以自由自愿的形式外包给非特定的(而且通常是大型的)大众志愿者的做法。Amazon Mechanical Tuckers (AMT)是目前很多人使用的众包平台,发布者把任务发布在平台上,想要做这项工作的人就能接受任务并获取报酬,与外包不同,众包的特点是发布的任务可能由成百上千个来自全球各地的人完成。
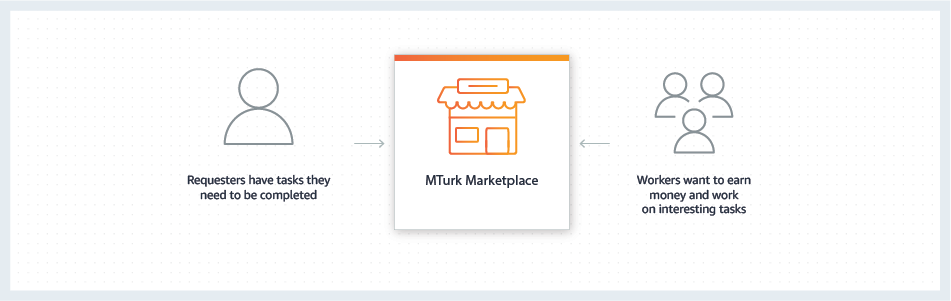
ImageNet数据集就是由AMT平台上的来自167个国家的四万九千个人完成标注的。为了保证数据的可信度,同一张图片可能由四五个人进行标注,然后选出最多人选择的那个标签。

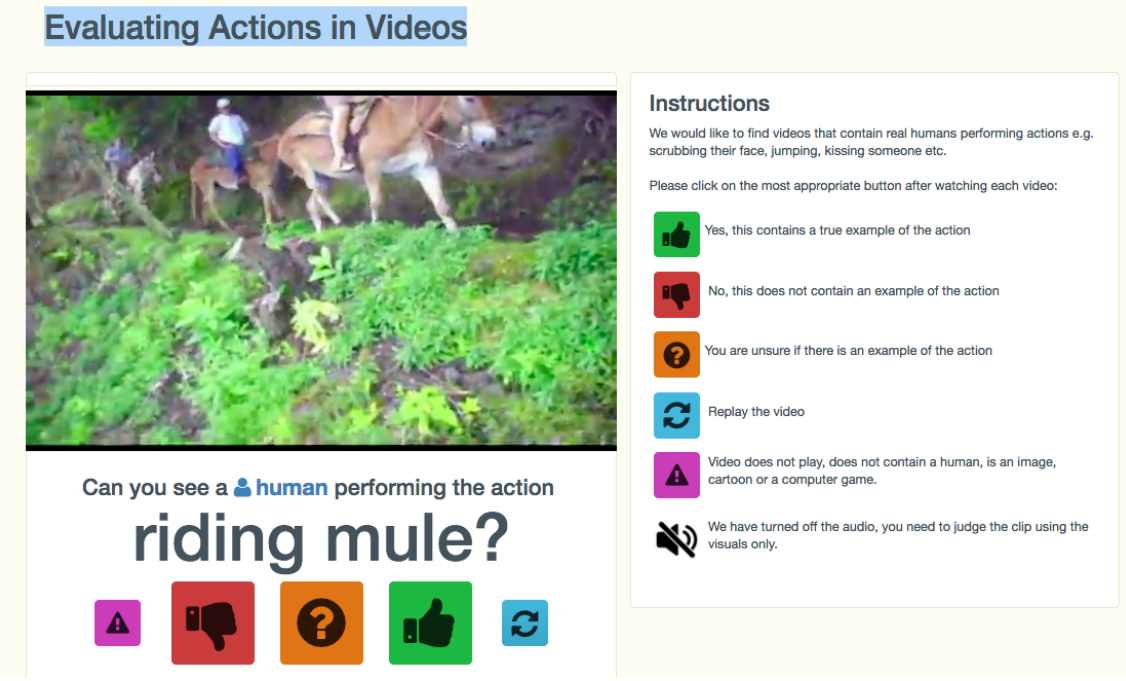
构建数据集方法3 Get√👍:
使用“工具人“平台来对数据进行标注。
优点:Money is all you need
缺点:No money
我不想花那么多钱——那就白嫖!
reCAPTCHA是由卡内基梅隆大学所开发的验证码系统,这个系统不仅能为网站抵挡住一部分的网络爬虫,同时也能白嫖访问用户的智力。
刚开始,reCAPTCHA是这样的,用户被要求输入两个单词,其中一个单词是能被计算机识别的(即知道答案的),另一个单词是无法正确识别的(即不知道答案的),假如访客答对了已知答案的那个单词,那么就能够判断访客不是爬虫,并且也能基本判断访客对另一个单词的回答也是正确的,这样就获得了一个新图片的标注。使用这种白嫖方法,reCAPTCHA成功把《纽约时报》几十年的纸质资料数字化。
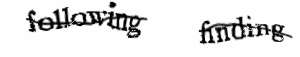
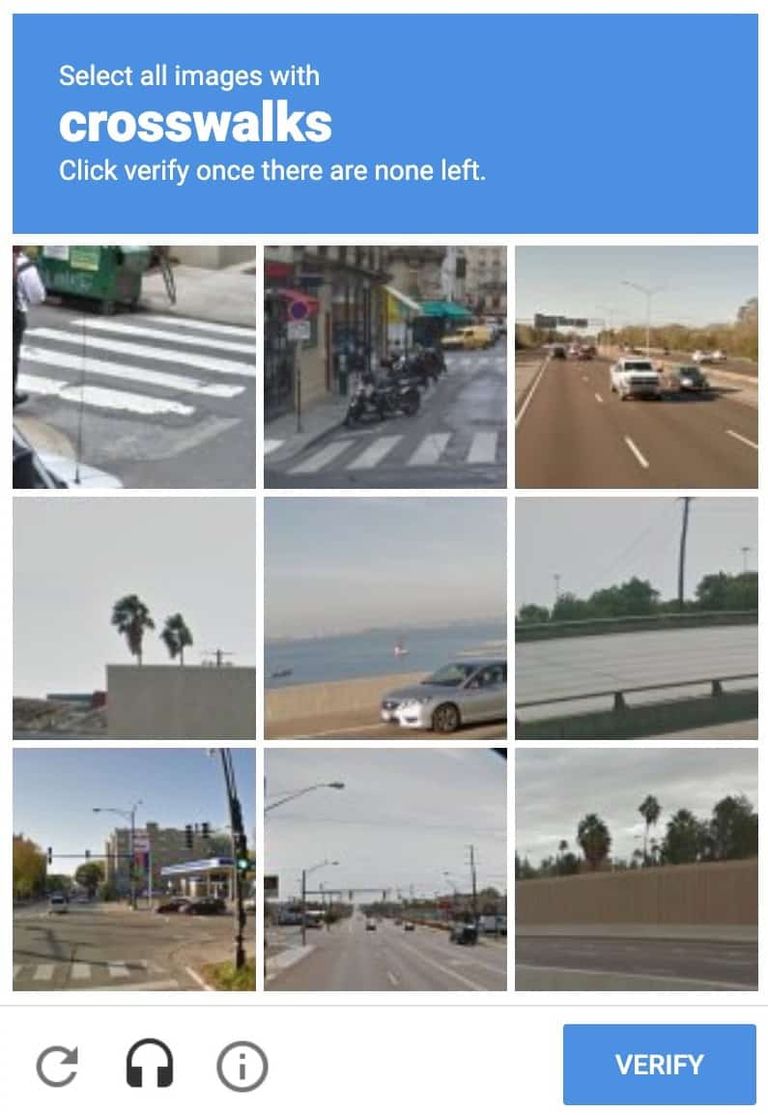
Google看到了这个方法,于是在2009年把reCAPTCHA收购了,现在大家在上网时时常能够看见下面这种验证码,这就是Google改进之后的reCAPTCHA,可以让你对图像识别、图像分割、语音识别所需要的数据进行标注,同时,改进后的评分算法也能更加精准地判断访客是爬虫还是真人,以避免爬虫带来的标注噪声。

构建数据集方法4 Get√👍:
用验证码白嫖标注,不用花钱。
优点:成本极低,并且会有很多很多人来标注。
缺点:只有用户流量大的公司才能使用这种方法,并且始终存在噪声。
我甚至都不想写爬虫——自动生成数据集
现在出现了一种”合成数据集“,这种数据集里面的数据是通过计算机程序生成的,生成方式可以是3D建模、图片拼凑,还可以使用已有的深度学习网络生成新的数据集图片。
MPI-Sintel数据集是由华盛顿大学和佐治亚理工学院的研究人员通过截取3D动画电影**《寻龙记》(Sintel)**不同场景而制作的数据集,相比较爬虫爬取到的数据,这种计算机创作出来的视频数据能够具有更清晰的画面(YouTube上用户上传的视频质量不一),并且标注也非常容易获得,通过不同的3D渲染还能增加/去除一些Shader上的噪声。

而FlyingChairs数据集更进一步,它在一些背景图上加入几张奇奇怪怪的运动3D椅子,并以此来得到视频—光流图数据,用来训练一些预测光流的神经网络,后面他们还让加入的东西不局限于椅子,构建了一个FlyingThings3D数据集。这种生成数据的方式基本没有版权或者隐私上的问题,但是由于生成的数据与实际数据是有差别的,所以依此训练出的模型也有可能是过拟合的,需要研究人员进行优化或者调整。

构建数据集方法5 Get√👍:
直接建模生成数据集和标注。
优点:避免了数据的隐私问题和版权问题,数据集规模可以随意调整,并且想要什么就能做什么,对于比较难获取的数据也可以直接生成,噪声方差也能调整。
缺点:生成数据集与真实情况可能存在差异,导致模型学习到偏差(bias),
总结
| 方法 | 举例 | 优点 | 不足 |
|---|---|---|---|
| 用工具人创造数据、标记数据。 | MNIST | 想要啥就有啥 | 假如要获取海量数据,成本就非常非常非常高 |
| 用网络爬虫获取数据 | ImageNet MSR-VTT | 能获取到很多数据 | 还是得找一堆工具人标记数据,标注成本高 |
| 使用众包平台来对数据进行标注。 | ImageNet MSR-VTT | Money is all you need | No money |
| 用验证码白嫖标注 | reCAPTCHA | 成本极低,并且会有很多很多人来标注。 | 只有用户流量大的公司才能使用这种方法,存在噪声。 |
| 直接建模生成数据集和标注 | MPI-Sintel FlyingChairs | 避免了数据的隐私问题和版权问题,数据集规模可以随意调整,对于比较难获取的数据也可以直接生成,噪声方差也能调整。 | 生成数据集与真实情况可能存在差异 |
参考文献:
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
reCAPTCHA - 维基百科,自由的百科全书 (wikipedia.org)
FlowNet: Learning Optical Flow with Convolutional Networks
A Naturalistic Open Source Movie for Optical Flow Evaluation
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!