Self Attention详解
本文最后更新于:2022年7月21日 下午
Self Attention详解
对于Self-attention的原理进行充分的解释
参考资料
Google本家论文:Attention Is All You Need
Pytorch官方Transformer实现:torch.nn.modules.transformer — PyTorch 1.9.1 documentation
动机
这一块李宏毅老师讲的很好。李宏毅-Transformer_哔哩哔哩_bilibili
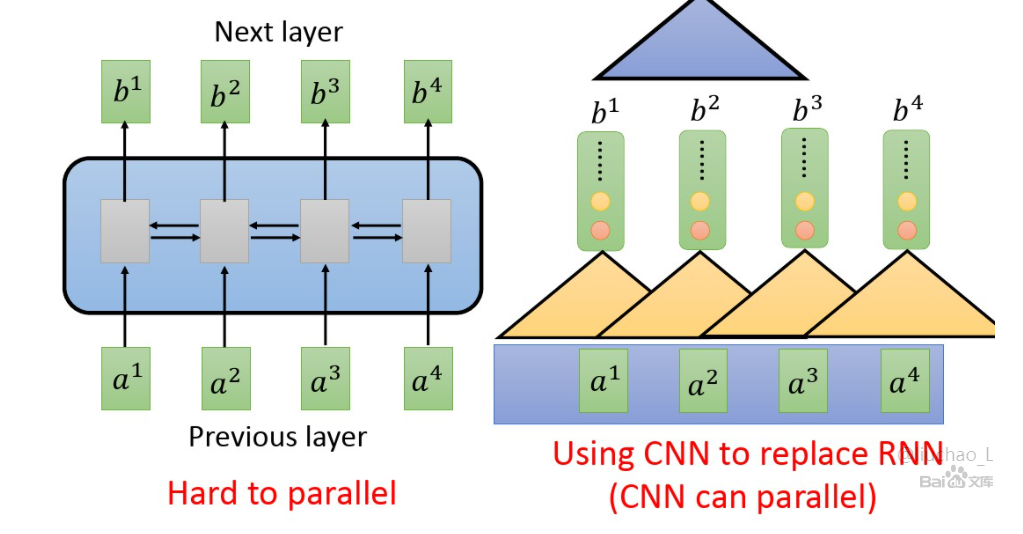
从Seq2Seq的角度来说,深度学习开始用的就是RNN类网络,但是这种做法很难并行计算,并且每个状态传递的信息用的是一个hidden向量。之后有人用CNN代替RNN,CNN的卷积操作可以实行并行计算,但是由于卷积核的大小不能太大(否则计算太复杂),感受野范围受限,要像RNN那样感受到全局信息就要多层CNN卷积,就像VGG那样不断缩小H、W维度,增厚C维度,但是这样计算量还是会提高很多。
因此,Google想弄出一个既能关照到每个输入的信息,也不需要太多计算的网络。
数学原理
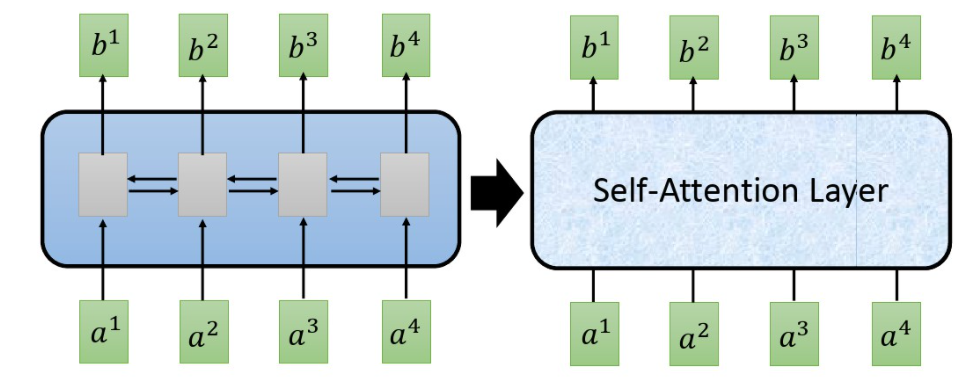
这块也借用李宏毅老师的PPT,和RNN类似,自注意力也是一个Seq2Seq的模型,输入序列,输出也是序列,可以把内部想象成一个黑箱,SA(Self Attention)的输入和输出与RNN相同。
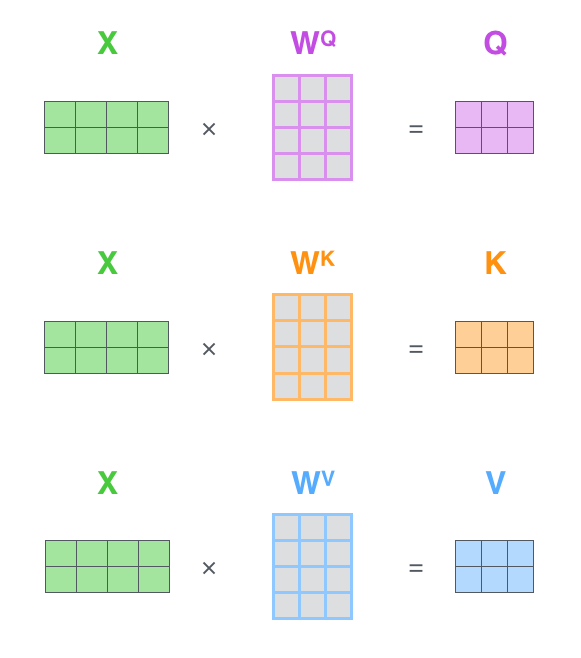
论文中的公式如下,注意力由三个张量Q、K、V得到,而QKV是由输入张量X作三个相似的矩阵运算得到的。Q代表Query,K代表Key,V代表Value(其中K和V的长度一定要相同,和V可以不同),这是一个类似查询的结构:我们用Q的每一个值(Q是有长度的),去查询每一个,然后通过Softmax函数得到注意概率α,再用这个α来重新分配对V的注意力。我们最终要的是(一个参考了V的)崭新的Q(或者是X)
数学上,用Query查询Key的过程是Q、K两个矩阵的内积,内积这个操作能够计算两个张量的相似度,余弦相似度的分子就是内积。这个地方的具体解释先挖个坑,总之我们能通过这个乘法操作,把得到的embed维度给消掉,得到一个的矩阵(如下图,假设Q的长度和KV不一样)。这个矩阵的每一行就可以看作是Query的某个元素对K的每一个元素的”注意力“。从深度学习的角度,这个注意力得到的方式是对矩阵的学习。
上一段”注意力“打引号是因为这还不是真正的注意力,注意力的特点是对于T长的张量的每个元素的注意力总和为1,就像有100块钱给T个人分,每个人分到的钱数的总和就是100,不能多也不能少,**这个操作通过函数实现。**而公式中除以的操作是为了归一化,用人话说就是让矩阵的值不要太大。这里的详细解释也挖个坑。假如要对自注意力层进行可视化的话,一般被可视化的就是这个α矩阵。
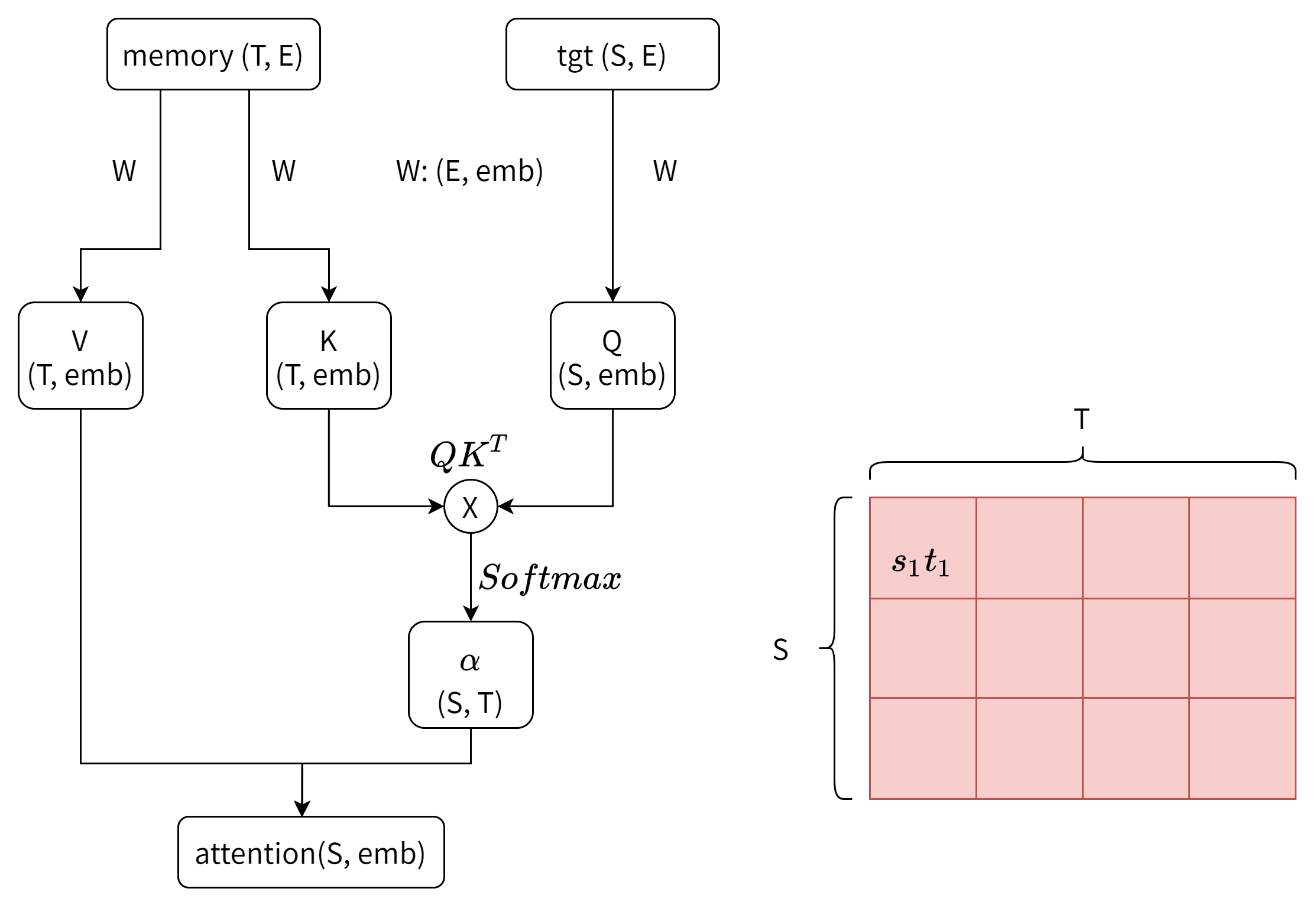
公式最后一部分与V相乘的操作就很容易理解了,我们要的是新的tgt,所以要通过分配注意力到V上来实现。加入tgt和memory像图中一样是不同的,那么tgt的信息融入在了α矩阵,然后通过最后这个操作结合上memory的信息。
更进一步 Multi Head
多头注意力就是通过设置多个W来得到多种QKV,然后进行上面的运算,是增加模型复杂度(拟合能力)的一种手段。但是这样就会得到d_head个attention,维度是,我们可以通过一个全连接层将后两个维度降维回。
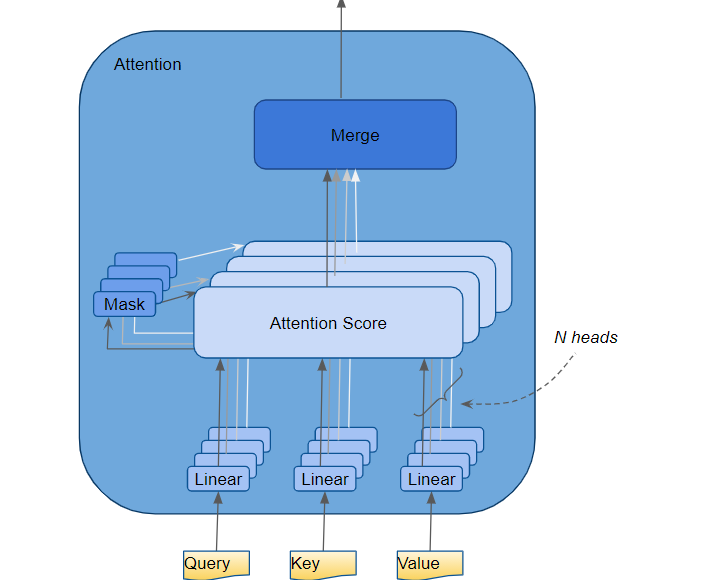

但是多个头真的能关注到不同的信息吗?
Analyzing Multi-Head Self-Attention:Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned写了可以把几个头斩掉,挖坑以后写。
Multi-Head Attention with Disagreement Regularization写了可以通过正则化让多个头关注不同的地方,挖坑以后写。
术语解释
看文献的时候可能遇到一些术语,专门在这里解释一下
- SA:self attention 自注意力
- MSA:multi-head self attention 多头自注意力
- d_head, d_model:pytorch中分别表示头数和的隐藏维度。要和后面的dim_feedforward区分开。
- tgt,memory:Transformer里面Decoder的self attention层,Q和KV不一样,tgt是Q,memory是KV。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!