通过transformer实现的细粒度分类模型——TransFG
本文最后更新于:2022年7月21日 下午
TransFG
TransFG: A Transformer Architecture for Fine-grained Recognition
关键词:计算机视觉、Transformer、细粒度分类、ViT
(前置)ViT:Vision Transformer
用来取代CNN,优点是节约计算资源。其适合在超大规模数据集(14M~300M)上训练。
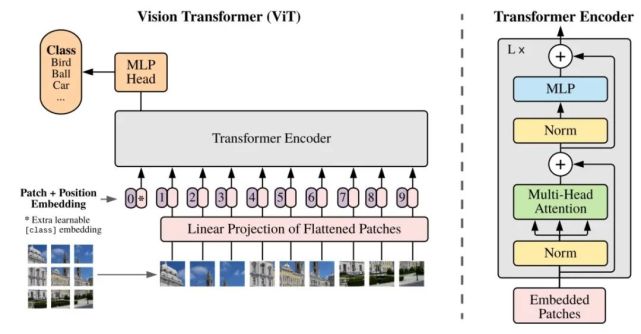
输入由于要是序列,就将图像切分成一系列patch。
pretrained model命名:
B:base 参数最少 L:Large 参数多 H:Huge 参数最多
一些可能用到的术语:
- R50+:结合Resnet50,将Resnet50的特征map输入
- ViT-L/16:这里的16指的是patch的大小是16
- BiT:改动的ResNet,用来做对比的

论文要解决的问题
传统的计算Fine-grained的方法是将图像的特定区域过CNN后区分,并且可能需要额外标注。
TransFG可以减少复杂度,提高性能。(减少复杂度……然鹅这模型还是很大)
率先尝试使用Vision Transformer来解决细粒度分类问题。
模型主体架构
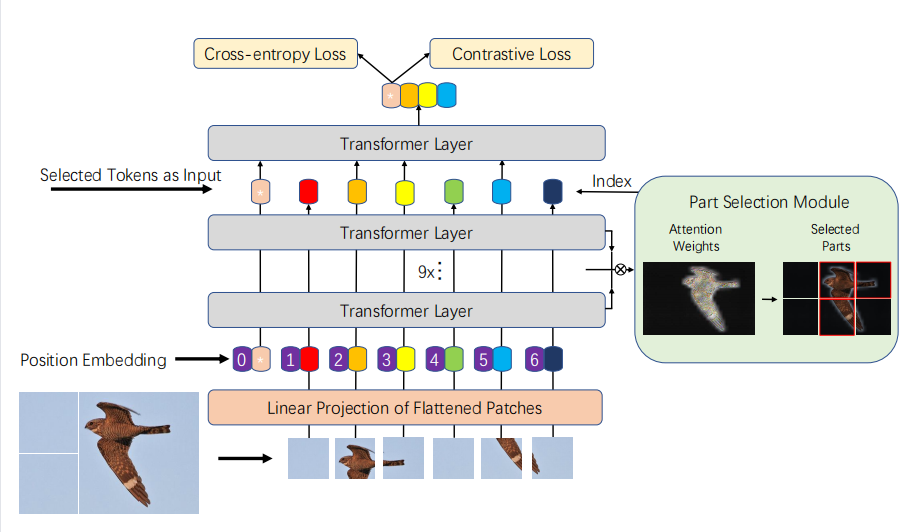
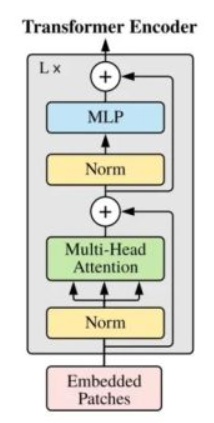
这里面每一个Transformer Layer都是下面这种多头self-attention,作者通过加载ViT的权重使用预训练模型,不冻结权重。(论文图是12 Layer)
作者针对Fine-Grained做出的优化
-
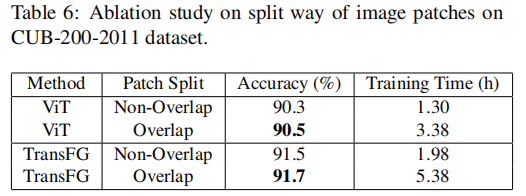
原ViT是粗暴的切分原图像成16patch,作者增加了重叠部分overlap,设置超参数S来控制重叠的多少。S越小效果越好但耗算力越多。
-
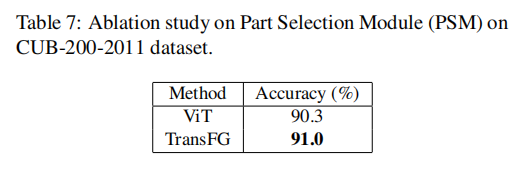
PSM(Part Selection Module) 选择模块。作者在前11层提取每一层输出的
α,然后在Layer的维度相乘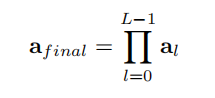
得到了Seq个,获取了所有层对信息的注意力。
然后选择最大的K个(Multi-head的个数)信息作为下一层的输入。
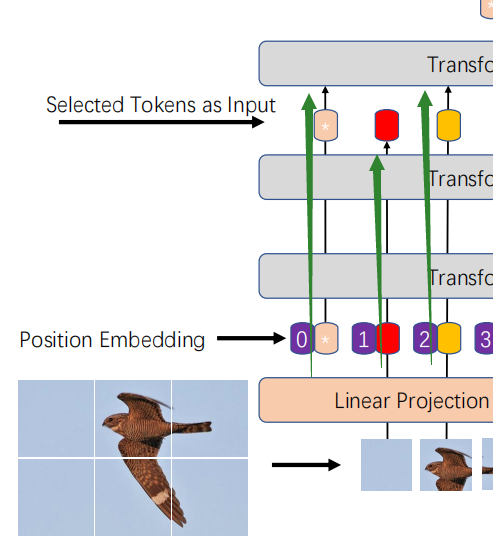
原本ViT会在0位置新加一个额外的Token,叫做classification token,用来保存总信息。
所以用PSM之后,最后一层attention变得hard了起来,之前层的总体信息保存在0号token中,而每一个patch对应的特征则经过选择之后再送入最后一层。
-
Contrastive feature learning 对比特征学习
作者认为交叉熵不够,还加入了
Contrastive Loss。
详见笔记Contrastive Loss与Triplet Loss

假如要改进,也许可以改成
Triplet Loss
实验
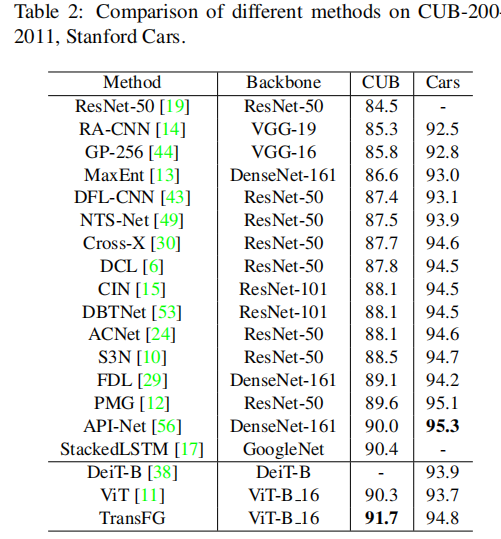
除此以外还有iNat2017、Dogs、NABirds等数据集,都是state of art。
-
重叠patch的提升
-
PSM的提升
-
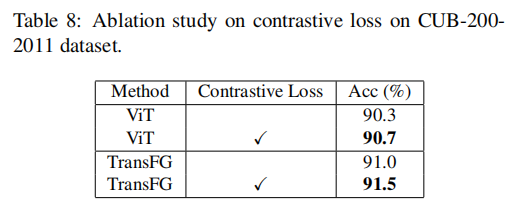
Contrastive的提升
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!