网络爬虫进化史,原来你是这样的爬虫:第3期
本文最后更新于:2022年7月21日 下午
网络爬虫进化史,原来你是这样的爬虫:第3期
前言
上一期,万维网经历了发展最迅速的时期,也经历了泡沫破裂的时期,而爬虫却在背地里偷偷壮大起来,仅仅1994这一年,爬虫的爬取能力就扩大了好几倍,而随着Google的天才工程师们的加入,爬虫也学会团结在一起集体行动。
不知道读者们还记不记得第一期的“常胜将军”
我们可以把爬虫想象为一位攻城掠地的常胜将军,他带着初始的补给去攻打一个个城池,每攻下一个城池就能获得新的补给,然后他就带着新的补给去攻打新的城池……直到他征服了全世界。

在经过几年的磨砺之后,常胜将军手下的军队越来越强大,他的脑袋也越来越灵活,他已经能够率领军队同时进攻几个城池,在新的世纪到来之时,世界的变化越来越大,城池越来越坚固,将军是否还能经受住考验呢?
Mercator
Google爬虫是20世纪的王者,而它并不是完美的,假如说Google爬虫是为了Google搜索而生的专业搜索引擎爬虫,那么诞生于1999年的Mercator就是能为各类人员所用的万金油。
在上世纪90年代的程序设计界,Java和C++是最热门的两门计算机编程语言,而他们的共同特点就是OOP(Object Oriented Programming),也就是面向对象,而面向对象又常伴随着模块化编程,模块化编程,是强调将计算机程序的功能分离成独立的、可相互改变的“模块”的软件设计技术,它使得每个模块都包含着执行预期功能的一个唯一方面所必需的所有东西。
我们要介绍的Mercator爬虫就是采用模块化设计思维,由Java语言实现的可拓展性爬虫。Mercator为爬虫领域带来了模块化设计,现在热门的Scrapy就是一个高度模块化的爬虫框架,当我们使用这种模块化设计的爬虫来进行某个爬取任务时,我们只要改动某一个模块的几十行代码就可以实现,并不需要动爬虫的核心(core)代码。
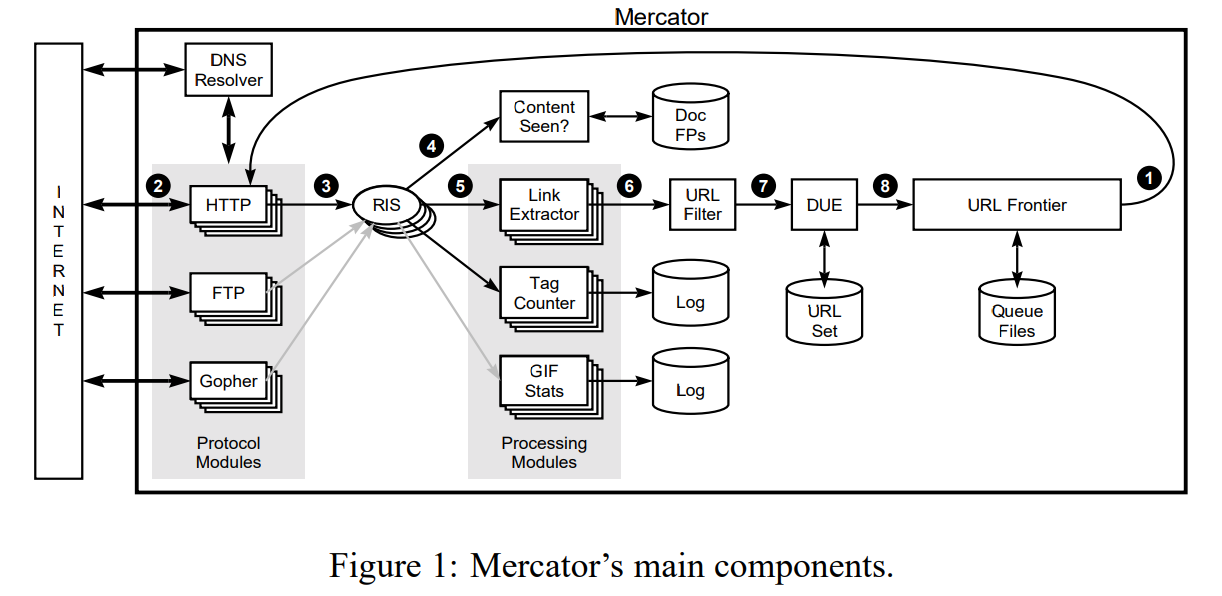
Mercator爬虫的可拓展分为规模可拓展性(scalable)和功能可拓展性(extensible)两个方面,规模可拓展指的是无论你想用Mercator爬取一个小网站还是想爬取整个万维网,这个爬虫都会以正常的效率工作,而功能可拓展性指的是Mercator支持第三方来添加新模块来拓展功能,类似现在很多游戏都会加入的创意工坊(steam workshop)或者是Chrome浏览器的插件(Chrome plugins)。
除了上面提到的可拓展性以外,Mercator还有其他优点
- Mercator和Google一样可以在多台计算机上同时运行来提高效率,在四台Compaq DS20E 666 MHz Alpha服务器和160M的宽带下,Mercator每天就能够下载五千万个页面。
- Mercator遵守爬虫礼仪,它的URL Frontier模块专门设计了前端(front-end)和后端(back-end)两个队列,前端队列负责给URL优先级排序,而后端队列负责保证爬虫礼仪。
- Mercator具有可移植性,由于它是用Java实现的,所以它可以轻松地运行在任何装有Java虚拟机的系统上。
这些优点让Mercator变得非常热门,再加上Mercator是当时公开信息和技术最多的爬虫,有非常多的人使用Mercator来进行研究,AltaVista搜索引擎就将它整合进去用来为美国和欧洲提供服务,还有人用它爬取了全网超过12TB的数据,甚至还有人用它来监控调查2000年美国总统选举时的与选举有关的网站。
Polybot
虽然Mercator靠着它的可拓展性红极一时,但是它有着一个很大的缺点——对硬件的需求高。Mercator虽然是个模块化的爬虫,但是要扩大规模就必须要多台相同的高性能机器一起运行多个Mercator程序,并且在Java尚未得到充足优化的时代,用Java写的程序普遍比C/C++更慢且占用内存更多,这使得使用Mercator的门槛很高。
2002年,另一个爬虫Polybot横空出世,它专门为低端机器进行了优化。
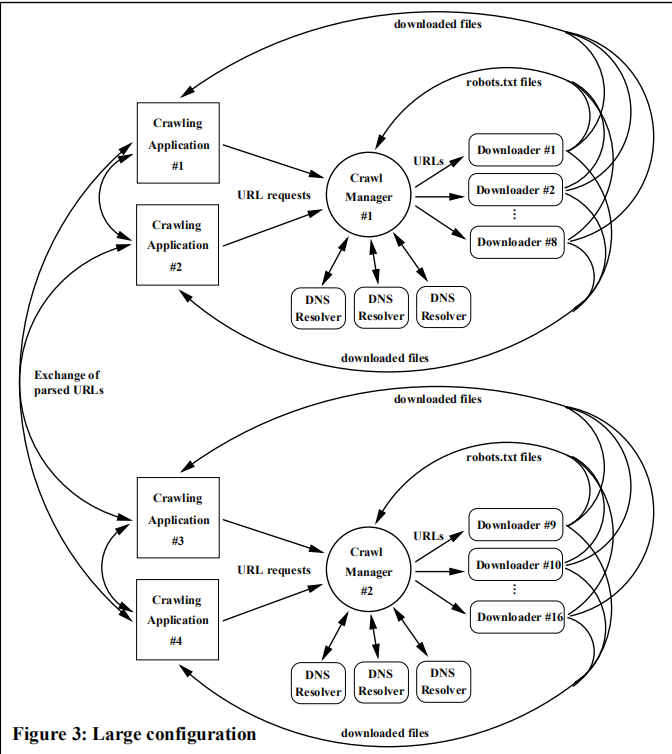
Polybot也是精心使用模块化设计的爬虫,比起Mercator,它的模块化程度显然更高,Mercator虽然能在多台机器上同时进行爬虫任务来提高效率,但是每台机器都运行的是同样复杂的任务,包括下载、提取、DNS解析等等,而Polybot则将它的每个模块完全分开,下载模块和DNS解析模块可以运行在不同的机器上,通过网络来交流和分配任务,这种方式让每台实体机器所负担的任务量大大减少,所以Polybot的使用者可以用更多台低成本机器来提升效率。
既然机器增多了,可能的故障也增多了,Polybot采用断点(checkpoint)技术来避免机器出问题导致爬取要从头开始。在开发者进行爬取试验的时候,由于各种因素程序崩溃了很多次,但是之后Polybot读取断点又继续进行任务了,实验结束后,Polybot总共在18天内爬取到了超过1.2亿个页面。
P2P
在1999年5月的美国东北大学(NEU),一个叫做Napster的软件免费软件在学生中流行起来,音乐爱好者们不用再担心没有钱去商店里买他们最喜欢的歌手的专辑了,Napster可以让他们互相分享MP3歌曲,在最火的时候,Napster拥有高达8000万的注册用户,无论是歌曲的数量还是下载速度,Napster都远远超过了他的竞争者们。
Napster的主要技术就是P2P(peer-to-peer),也就是点对点网络或者对等网络。这种网络的特点就是没有中心服务器,仅依靠用户群来交换数据的互联网。这种网络的优点就是用户越多,效率越高,而且其中任何一个节点(用户)掉线了也不会影响整个网络。QQ、Skype(即时通话app)、SETI@home(利用全球各地计算机提供算力来寻找地外文明的项目)、BT下载(包括迅雷等)和比特币都使用了P2P技术。
P2P的成功也引起了爬虫开发人员的注意,在2002年UbiCrawler爬虫率先使用了P2P网络来进行爬取任务。UbiCrawler和Mercator一样都是100%使用Java来实现的爬虫,然而UbiCrawler出色的设计让Java运行速度慢的劣势消失了,它在使用五台普通个人电脑的情况下,就实现了1000万每日的页面爬取量。
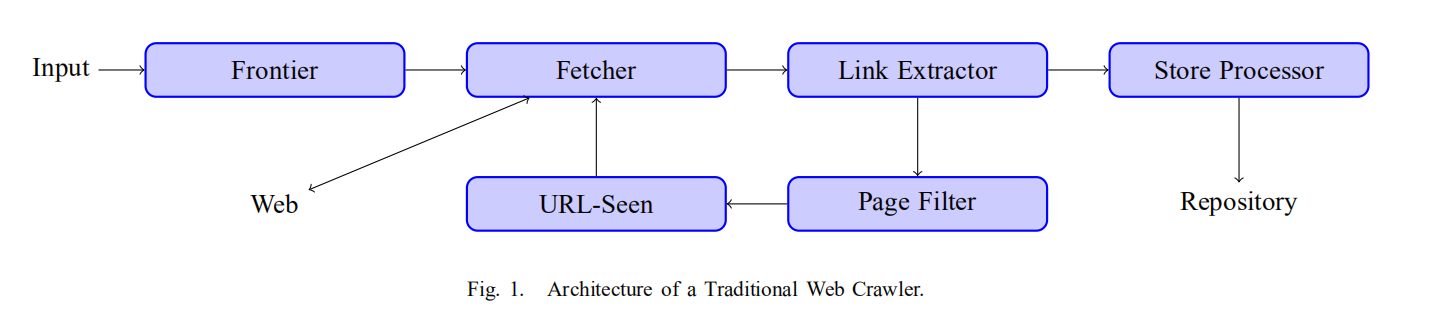
UbiCrawler使用到P2P技术的地方是URL-Seen模块,也就是爬虫从页面中提取到了超链接之后,需要判断这个链接是否已经被访问过,而随着不断爬取,已经访问过的链接数量可能是几百万几千万,高性能爬虫都会在这里遇到瓶颈。UbiCrawler通过一致性哈希算法(consistent hashing),在爬虫的某个节点遇到一个URL之后,这个节点会将算出URL的hash值,然后判断这个URL应该由哪个节点负责处理,最后传递给那个节点,这样每个节点都只用处理总URL-Seen的一部分。
在之后有很多研究团队在UbiCrawler的基础上进行了改进,pSearch项目采用分布式哈希表(Distributed Hash Tables)来进一步提升P2P爬虫的性能,随着P2P的节点遍布全球,还有人通过考虑节点的地理位置来分配任务从而提升效率。
除了分布式爬虫,也有一些特立独行的爬虫只在一台机器上运行并发挥最大效率,比如2008年的IRLbot,在一台装有四核AMD皓龙处理器的服务器上,用41.27天爬取到了超过63亿个页面!
Wayback Machine
爬虫能做什么?从第一期到现在,开发爬虫的目的好像无非就是构建搜索引擎和对万维网进行规模研究,然而有一个组织使用爬虫制造了一个网站时光机,允许用户“回到过去”,这就是Wayback Machine。
这个时光机通过爬虫将从万维网上爬取到的页面存档下来,创始人Kahle和Gilliat希望以此能为整个互联网“普及所有知识”。时光机于1996年开始存档网页,在2001年正式公开时,它已经存档了超过100亿个页面,截止2018年9月,时光机已经存有了超过25PB的数据。
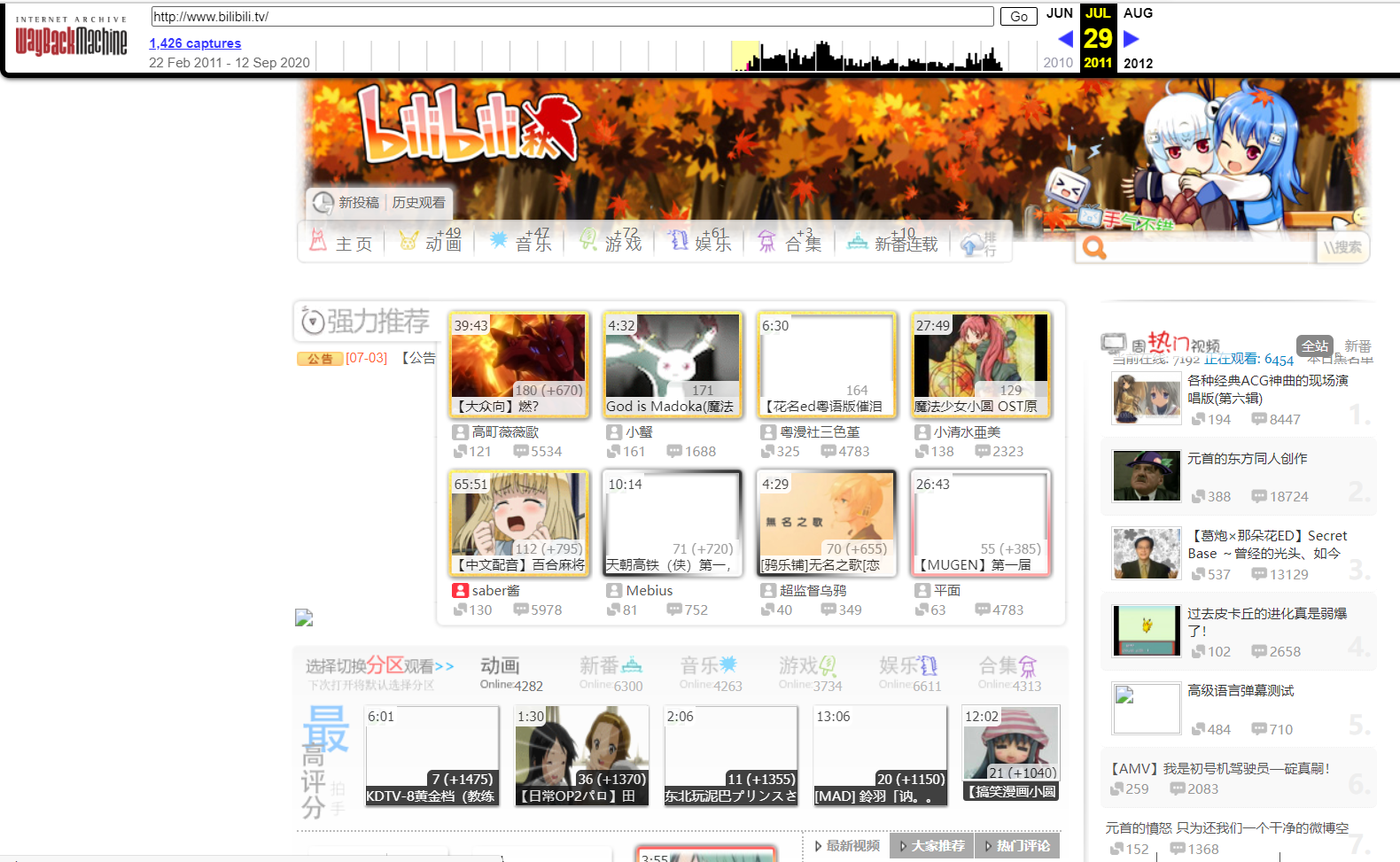
这是一个很有趣的网站,我们可以在上面找到很多网页之前的样子,比如B站在2011年的样子
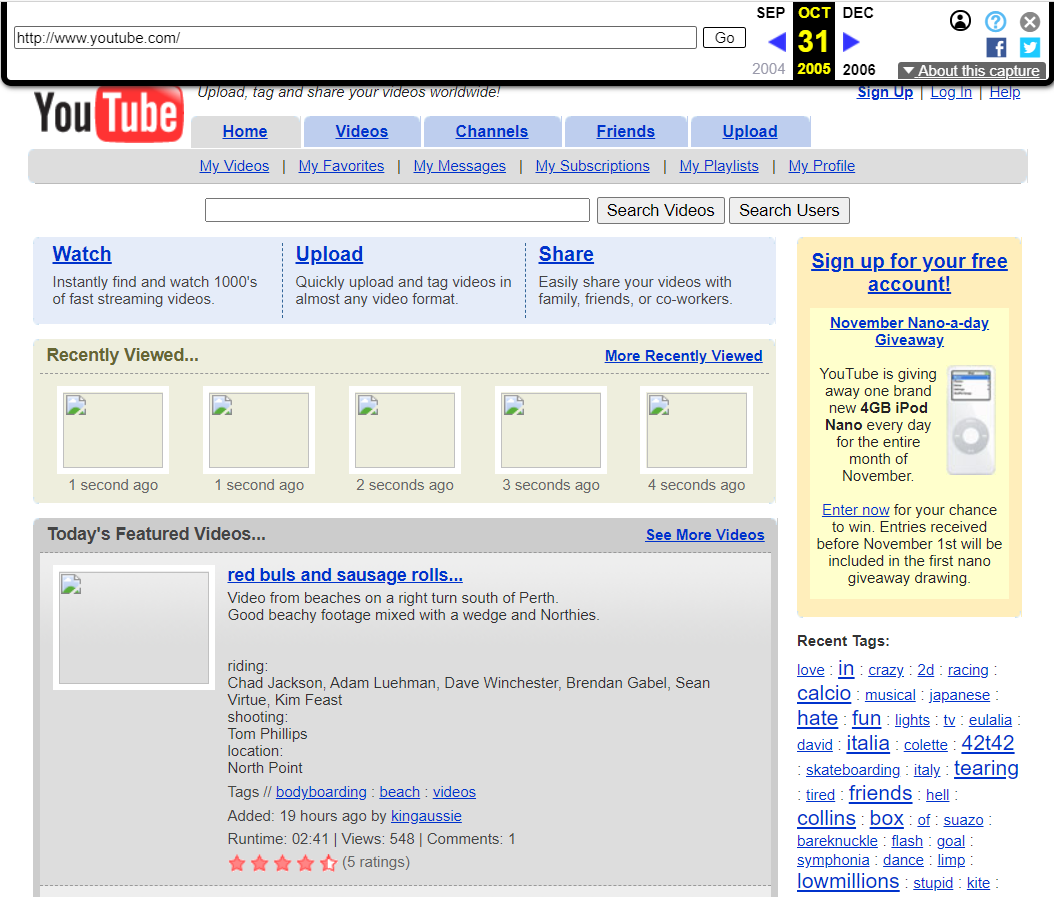
还有Youtube在2005年的样子
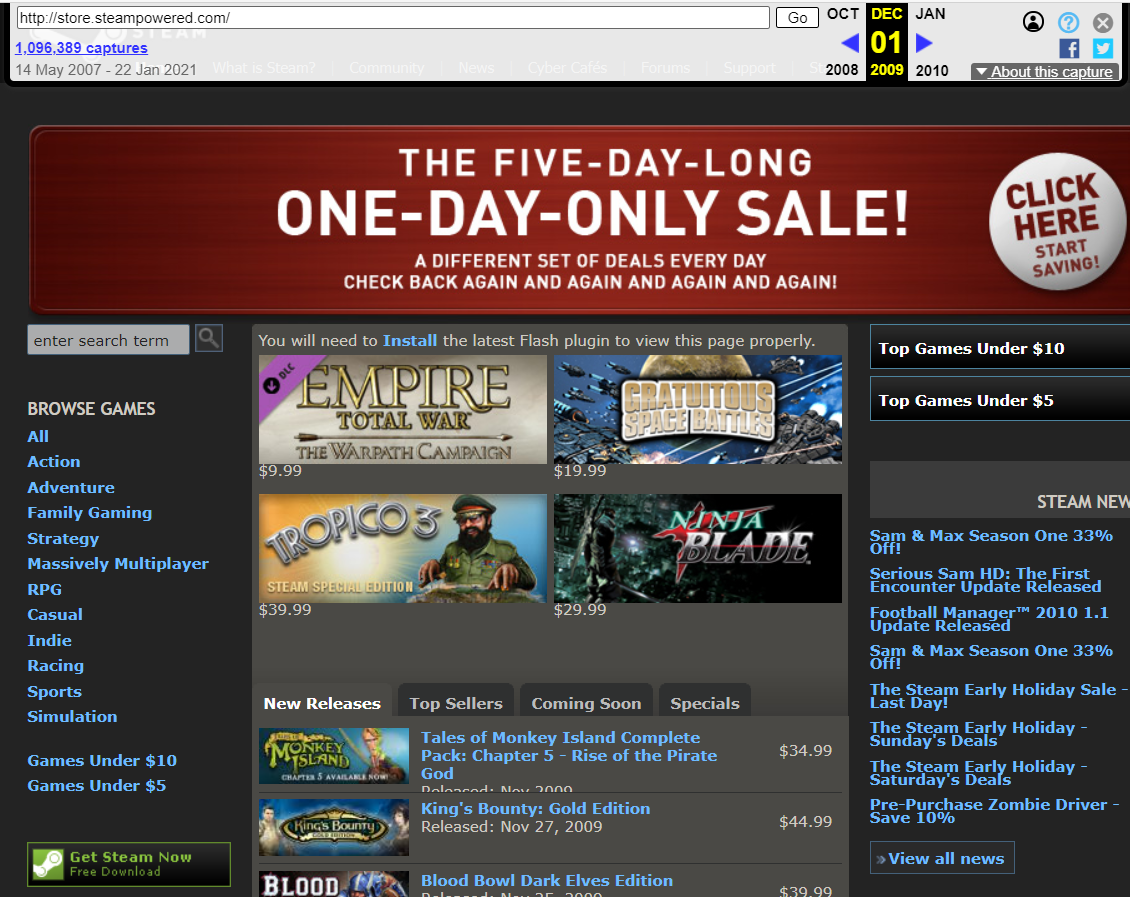
还有2009年的steam

接下来?
这一期,我们的爬虫不仅开始成群结队了起来,而且他们的阵型变得更加灵活,我们的常胜将军带领的爬虫大军既能分散作战,用庞大的数量攻略城池,也能派出名将用高效的数据结构和算法来攻略城池,就算有几位将军倒下了,也会有其他将军顶替……纵使万维网的页面从最开始的一个页面发展到几百万几亿个页面,成千上万个站点,也避免不了爬虫爬取到每个角落。
然而,万维网并不是只在数字上有增长,当这些爬虫兴奋地在网上爬来爬去时,殊不知万维网已经成了一座冰山,掩盖在海底的不可见数据越来越多,这让传统的爬虫束手无策,他们需要进一步的升级才能看清水底的数据……

这篇文章也发布在下面这个公众号数媒极客,公众号里面有其他很有趣的文章,可以扫码看一看~

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!