Video Captioning相关论文调查
本文最后更新于:2022年7月21日 下午
Video Captioning相关论文调查
不是一个综述,不会全面解析论文,只是一个调查笔记,而且本人水平不高,部分地方可能有错误。
对目前基于深度学习的Video Captioning(视频描述)的论文进行调查,统计现在得到的最好结果。
S2VT
S. Venugopalan, M. Rohrbach, J. Donahue, R. J. Mooney, T. Darrell, and K. Saenko. Sequence to sequence - video to text. In ICCV, 2015
代码实现:
- 官方caffe:https://github.com/vsubhashini/caffe/tree/recurrent/examples/s2vt
- 复现pytorch:xiadingZ/video-caption.pytorch: pytorch implementation of video captioning (github.com)
- 我的复现(pytorch)(暂未完成,最新可看readme):Kamino666/S2VT-video-caption: the recurrence of paper “Sequence to Sequence – Video to Text” (github.com)
论文简介:
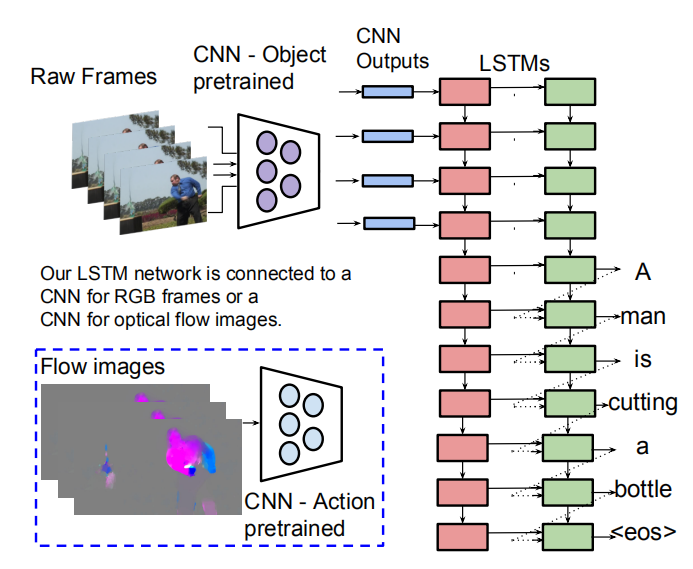
大概结构如图,对于视频图像,使用预训练的CNN网络,对视频的每一帧进行特征的提取,每个视频会得到一个[len, feat_dim]的特征,其中每个视频的len不相同。视频的图像输入,可以是RGB图像也可以是光流图。论文中RGB用VGG16,光流图用AlexNet提取feature。
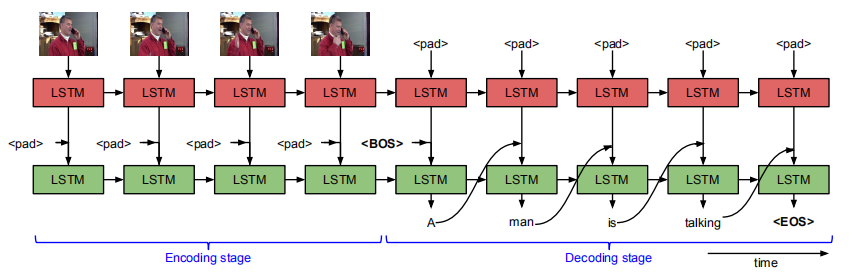
训练时,之前由CNN提取的不定长的feature,在编码阶段逐步送进图像层,在图像输入结束后,给文字层提供<BOS>标志开始预测文字,预测到文字层输出<EOS>结束。这样实现了输入和输出都能不定长度。文字层的输入由图像层的输出结合文字输入得到(这里的结合是在hid之前那个维度上的拼接)。
由于要保持格式不变,在图像输入结束之前,给文字层提供的文字数据是<pad>,在图像输入之后,给图像层提供的图像数据是<pad>。<pad>在实现中简单填充为0.
注意实现的时候这两层的输入大小不同,得分成两个CNN。
实验结果:
MSVD数据集 METEOR 29.8%,M-VAD数据集 METEOR 6.7%,MPII-MD数据集 METEOR 7.1%。
Multimodal Memory Modelling
Wang J, Wang W, Huang Y, et al. M3: Multimodal memory modelling for video captioning. CVPR, IEEE 2018
论文简介:
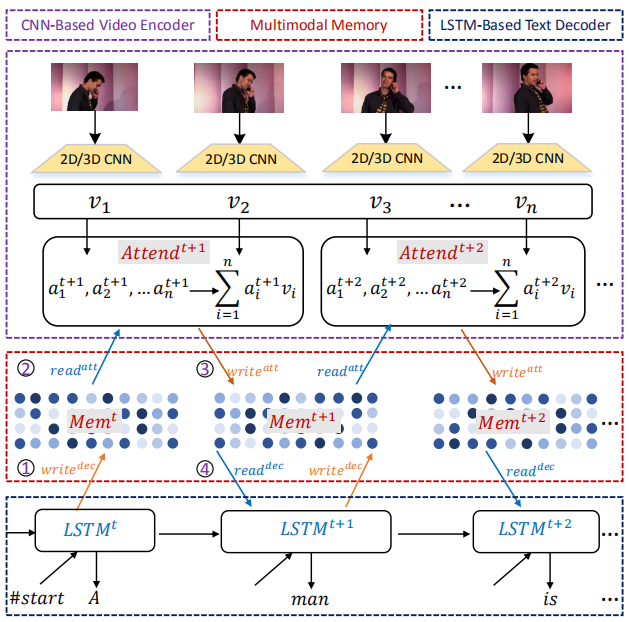
对记忆建模(Memory Modeling),主要处理长视频,比较复杂,没深入研究。
实验结果:
MSVD数据集 METEOR 33.3%,MSR-VTT数据集 METEOR 26.58%。
MRS(Multi-Representation Switching)
Heechan Kim, Soowon Lee. A Video Captioning Method Based on Multi-Representation Switching for Sustainable Computing. Sustainability 2021
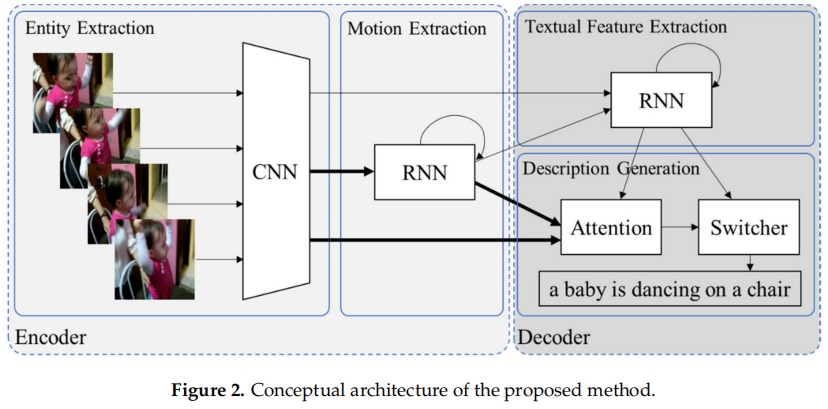
比较新的一篇论文,在Sustainability上发的,所以注重可持续计算,网络不大。
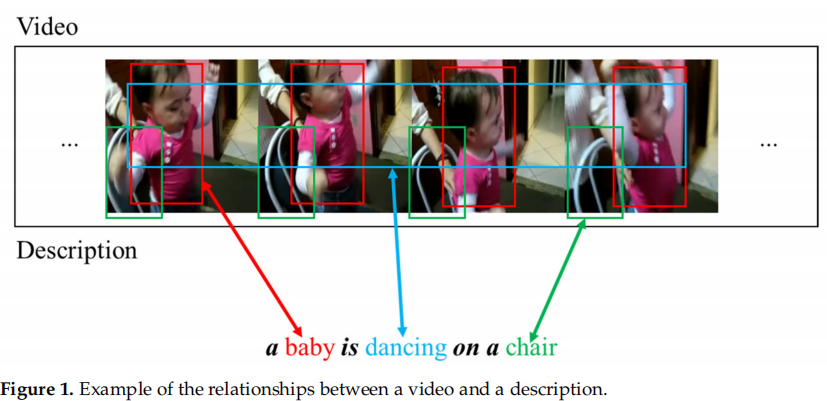
作者的思想就是认为在Video Caption生成的句子中,有的单词是要依靠画面来生成的,而有的单词只是语法需要,比如图中“a baby is dancing on a chair”,只有标了颜色的那几个单词是要从画面中提取的,其余都是语法上的要求。
所以作者分别弄了行为特征模块和文字特征模块,通过一个switcher来学习使用哪个模块。
实验结果:
MSVD数据集 METEOR 34.0%。
RecNet
Bairui Wang, Lin Ma, Wei Zhang, Wei Liu. Reconstruction Network for Video Captioning. arxiv 1803.11438
Reconstruction Network for Video Captioning - 知乎 (zhihu.com)
论文简介
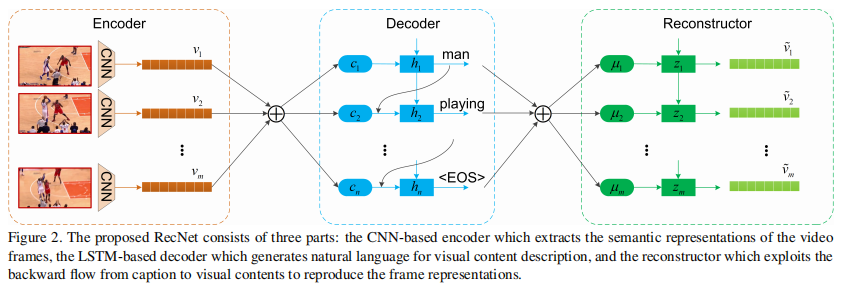
腾讯AI实验室的一篇论文,在解码器后面新增了一个Reconstructor。Encoder和Decoder不是重点,可以用注意力机制的模型,也可以用S2VT。
重点是Reconstructor,Reconstructor是搭建在解码器之上的,旨在根据解码器的隐状态h,恢复原视频信息。但是考虑到原视频帧的多样性以及较高的维度,这种方案较为棘手。因此重建为由编码器得到的视觉特征也是个很好的选择。Reconstructor可以加强视觉序列和caption之间的关系,有望于改善video caption的质量。在具体实现上,Reconstructor是一个LSTM,文中提供两种结构的Reconstructor,分别是侧重于原始视频的全局结构和局部结构。
(这一部分还待更仔细看一看论文,预计会专门写一篇感想。)
实验结果:
MSVD数据集 METEOR 34.1%。
OA-BTG
Junchao Zhang and Yuxin Peng, Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning, 2019 CVPR.
使用双向时空图做视频描述(video captioning) - 知乎 (zhihu.com)
论文简介:
太复杂了,不适用于我目前的研究。但是这篇论文是目前找到的效果最好的。(但是有点作弊的是它输入数据还手动分隔了对象的区域)
实验结果:
MSVD数据集 METEOR 36.2%, MSR-VTT数据集 METEOR 28.2%。
multirate GRU
Linchao Zhu, Zhongwen Xu, Yi Yang. Bidirectional Multirate Reconstruction for Temporal Modeling in Videos. 2016, arxiv 1611.09053v1.
论文简介:
不是专门弄video caption的,论文中提到的很少。论文主要是用到了多速率GRU的技术,即让GRU有的一个一个读,有的隔一个读,有的隔两个,这样形成不同的速率。没有仔细读这篇论文,仅记录下效果。
实验结果:
MSVD数据集 METEOR 33.4%
GRU-EVE
Nayyer Aafaq, Naveed Akhtar et. Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video Captioning. 2019, arxiv 1902.10322v2.
论文简介:
挺复杂的,结合了2D-CNN 3D-CNN和对象识别三个数据来源,还用了一个什么傅里叶变换.第一就是用层级的短时傅里叶变换对卷积网络提取出来的特征进行浓缩,把时间信息融入其中;第二就是用物体检测模型从视频中提取高层的语义信息,丰富编码器提炼的视频表示。
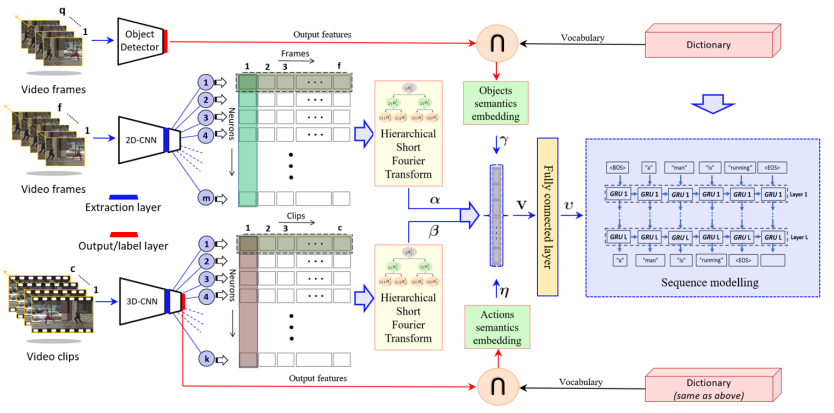
实验结果:
MSVD数据集 METEOR 35.0%, MSR-VTT数据集 METEOR 28.4%
SibNet
Sheng Liu, Zhou Ren, Junsong Yuan. SibNet: Sibling Convolutional Encoder for Video Captioning. https://doi.org/10.1145/3240508.3240667
论文简介:
重点在于encode videos。编码分成两部分,一部分用自编码器,另一部分用一种视觉语义互相组合embed的编码(目前理解也是非监督学习)。然后这两个编码再解码生成caption,这三部分都有train_loss。
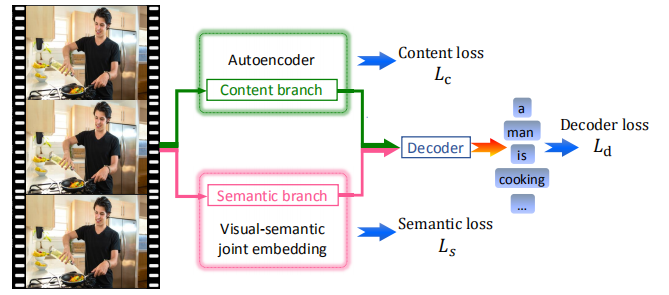
实验结果:
MSVD数据集 METEOR 34.8%, MSR-VTT数据集 METEOR 27.5%
MSVD数据集汇总
| 模型名字 | METEOR |
|---|---|
| S2VT | 29.8 |
| M3-C3D+InceptionV3 | 33.3 |
| MRS-ew+ | 34.0 |
| RecNetlocal(SA-LSTM) | 34.1 |
| OA-BTG | 36.2 |
| mGRU | 34.5 |
| GRU-EVE | 35.0 |
| SibNet | 34.8 |
MSR-VTT数据集汇总
| 模型名字 | METEOR |
|---|---|
| M3 | 26.6 |
| OA-BTG | 28.2 |
| RecNet | 26.6 |
| GRU-EVE | 28.4 |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!