Python多线程详解(真的很详细)
本文最后更新于:2021年10月22日 下午
Python多线程详解
使用多线程,可以同时进行多项任务,可以使用户界面更友好,还可以后台执行某些用时长的任务,同时具有易于通信的优点。(对于GIL以及Python多线程对于效率的影响讨论可看知乎为什么有人说 Python 的多线程是鸡肋呢? - 知乎 (zhihu.com))
Python3中使用的是threading模块。
创建和执行一个线程
一般我们有两种方法来创建线程,一种是以某个函数来作为起点,另一种是继承Thread类。
方法一
获取一个Thread对象,构造参数中target是起点函数,注意不要加括号。假如起点函数有参数,则可以通过args输入元组参数或者kwargs输入字典参数。
1 | |

方法二
1 | |
正式介绍threading模块
关于线程信息的函数:
threading.active_count():返回当前存活的Thread对象数量。threading.current_thread():返回当前线程的Thread对象。threading.enumerate():列表形式返回所有存活的Thread对象。threading.main_thread():返回主Thread对象。
Thread对象的方法及属性:
Thread.name:线程的名字,没有语义,可以相同名称。Thread.ident:线程标识符,非零整数。Thread.Daemon:是否为守护线程。Thread.is_alive():是否存活。Thread.start():开始线程活动。若多次调用抛出RuntimeError。Thread.run():用来重载的,Thread.join(timeout=None):等待直到线程正常或异常结束。尚未开始抛出RuntimeErrorThread(group=None, target=None, name=None, args=(), kwargs={}, *, deamon=None):构造函数。
守护线程 Daemon
如果某个线程是守护线程,那么这个线程会在主线程运行完毕后结束。主线程运行完毕指的是主线程的进程内所有非守护线程全部运行完毕,所以可以理解为守护进程是不那么重要的进程。
设置守护线程用Thread.setDaemon(bool)
1 | |
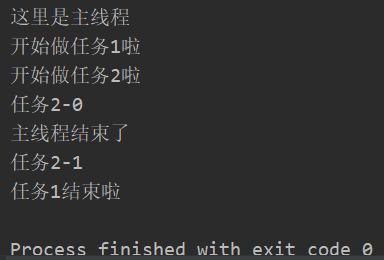
运行这段代码用IDLE可能出现守护进程未结束的bug,所以用pycharm或者在命令行里运行可看见真实效果。
让主线程等待子线程结束 join
假如要让主线程等子线程,那么可以使用Thread.join()方法。
join可以让运行这条语句的主线程在此阻塞(等待),直到子线程结束,再放行。
1 | |

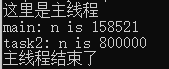
由于线程共享资源而引发的bug
1 | |

你的结果很可能与我不同,多次执行这个代码的结果也很可能不同。由于这种不确定性,程序有可能出现致命错误,我们称之为线程不安全。
这个问题出现的原因是这样的:t1线程启动后,循环很多次,每次将全局变量n加1,但是加这么多次是要时间的,在t1没有将n加完时,t2线程就对n进行了访问,从而访问到的值可能不是期望值。
线程安全的类应该具有以下特征:
- 该类的对象可以被多个线程安全地访问
- 每个线程在调用该对象的任意方法后,都将得到正确的结果
- 每个线程在调用该对象的任意方法后,该对象都依然保持合理的状态
接下来我们将采取一定的方法来使线程安全。
锁 Lock 重入锁 RLock
锁是保证线程安全的一种途径,你可以想象全局变量都存放在一个房间里,只有进入这个房间的人(线程)才能操作全局变量,在许多人进房间的时候,就可能出现混乱。因此他们约定,在门口挂一个牌子,一面写着有人,另一面写着没人,每当有人进出的时候就把牌子翻一面,别人看见这牌子是有人就在门口等着。(这就是锁的获取与释放)。然而既然是约定,就能被打破,有的人可能不知道这个约定,牌子上写着有人他也会进去。(这就是执行没有写锁部分的的方法的线程)
Python的threading模块中有Lock和RLock两个类。他们都有这两个方法
Lock.acquire(blocking=True, timeout=-1) 获取锁。
- 获取成功返回True,超时或其他返回False
-
timeout参数指定获取不到锁时等待的时间,单位为秒。
-
blocking参数指定是否阻塞调用,默认获取不到锁就阻塞。
Lock.release() 释放锁。
-
对于Lock,可以从任何线程调用,不一定是上锁的那个线程才能解锁。
-
对于RLock,只能从上锁的线程调用。
- 对未锁定的锁调用release会引发RuntimeError
RLock的R表示Reentrant,如果用RLock,那么在同一个线程中可以对它多次acquire,同时也要用相同数目的release来释放锁。这个东西的意义在于避免死锁。
死锁(Deadlock)是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
举个例子,假如你要使用递归函数,这个递归函数中需要对某个全局变量修改,于是你加上了Lock,然而在递归的过程中,第二层递归的acquire就获取不到锁了,于是第一层递归在等待第二层结束,而第二层在等待第一层的release,这就造成了死锁。
使用锁可能导致执行速度慢,但是保证了线程安全
无论是Lock还是RLock,acquire和release都要成对出现,所以一般用这种形式写语句
1 | |
使用Lock改进上一次代码的例子:
1 | |
队列 Queue
Python的queue模块为单独的一个模块,并不在threading里。Queue模拟各种不同的队列,使不同线程之间实现松耦合,并且提高效率,经常使用它。
Python中的queue有三种队列,分别是queue.Queue() queue.LifoQueue() queue.PriorityQueue()
Queue就是FIFO(First In First Out)先入先出队列。
LifoQueue是LIFO(Last In First Out)后入先出队列,对应栈数据结构。
PriorityQueue需要你指定添加进队列的数据的重要性,然后队列根据重要性排序,更小的先出。
官方文档:
最小值先被取出( 最小值条目是由
sorted(list(entries))[0]返回的条目)。条目的典型模式是一个以下形式的元组:(priority_number, data)。
也就是说你向PriorityQueue中添加数据时,推荐采用 (priority_number, data) 格式,元组的第一个数据代表优先级,数字越小越先(可以是负数),假如优先级相同,会比较第二个数据,假如不可比较会报错。假如前两个数据都相等,则顺序随机。
Queue是父类,下面介绍Queue的方法:
Queue(maxsize) 实例化Queue类可提供队列最大值的参数。到达最大值之后的put操作会阻塞。
Queue.put(block=True, timeout=None) 向队列中添加一个数据,同样可以设置阻塞等待时长。超时直接抛出queue.Full错误。
Queue.get(block=True, timeout=None) 从队列中获取一个数据,并从中删除这个数据,超时抛出queue.Empty错误。不设置超时会一直堵塞。
Queue.qsize() 返回队列中数据的量,不怎么可靠,因为获取的同时,其他线程可能进行操作。
Queue.join() 队列还存在未完成任务时阻塞,等待知道队列无未完成任务。注意是任务完成而不是队列为空,需要与task_done联合使用
Queue.task_done() 每put一个数据就会让未完成任务+1,但是get不会-1,只有task_done才会-1
队列为空时报错ValueError
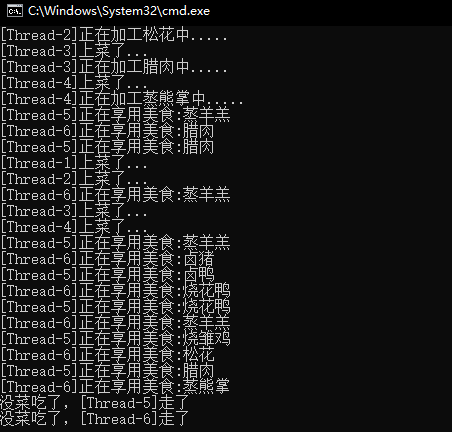
用Queue完成生产者-消费者模型(吃货版)
生产者消费者模型是一种松耦合模型,生产者互相之间不需要沟通,消费者之间也不需要沟通,生产者和消费者只关系仓库,也就是这里的queue。生产者将数据放入容器,数据流向消费者,消费者从容器中取出数据。
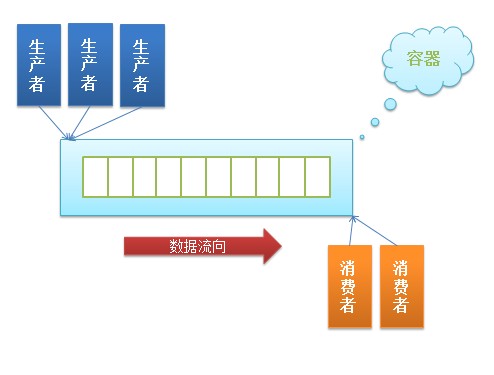
1 | |
线程池 thread pool
虽然线程比进程简单许多,但是系统启动一个新线程的成本依旧很高。线程池创建时会自动创建一定空闲的线程,我们将一个函数(任务)提交给线程池,线程池就会调用一个空闲的进程来执行它,当函数结束时,线程不死亡,而是返回到线程池中等待执行下一个函数(任务)。
当程序中需要创建大量生存期短暂的线程时,可考虑线程池
当程序中需要控制并发线程时,可考虑线程池
python中有concurrent.futures模块,线程池的基类是Executor,其有两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
Exectuor 提供了如下常用方法:
submit(fn, *args, **kwargs):将 fn 函数提交给线程池。*args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。超时抛出TimeoutError错误。返回每个函数的结果,注意不是返回future。shutdown(wait=True):关闭线程池。关闭之后线程池不再接受新任务,但会将之前提交的任务完成。
程序将task函数submit给线程池后,会返回一个Future对象,Future主要用来获取task的返回值。
由于结果不确定,对于当时是的未来的对象,所以取名future。
Future 提供了如下方法:
cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。cancelled():返回 Future 代表的线程任务是否被成功取消。running():如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True。done():如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True。result(timeout=None):获取该 Future 代表的线程任务最后返回的结果。如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒。超时抛出TimeoutError,取消抛出CancelledError。exception(timeout=None):获取该 Future 代表的线程任务所引发的异常。如果该任务成功完成,没有异常,则该方法返回 None。add_done_callback(fn):为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数,参数是future。
使用线程池来执行线程任务的步骤如下:
- 调用 ThreadPoolExecutor 类的构造器创建一个线程池。
- 定义一个普通函数作为线程任务。
- 调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
1 | |
下列程序使用 Executor 的 map() 方法来启动线程,并收集线程任务的返回值:
1 | |
上面程序使用 map() 方法来启动 3 个线程,但是线程池最多两个线程,所以在输出中你可以看到,刚开始是两个线程都在输出,到后面线程1先被执行完毕,接了action(150)的活,于是后面输出的都是线程1了。
通过上面程序可以看出,使用 map() 方法来启动线程,并收集线程的执行结果,不仅具有代码简单的优点,而且虽然程序会以并发方式来执行 action() 函数,但最后收集的 action() 函数的执行结果,依然与传入参数的结果保持一致。也就是说,上面 results 的第一个元素是 action(50) 的结果,第二个元素是 action(100) 的结果,第三个元素是 action(150) 的结果。
信号量 semaphore
信号量和线程池非常相似。信号量也可以用来控制并发的线程数,它初始化时设定一个计数器,每次acquire()让计数器-1,release()让计数器+1,这个计数器不会小于零,当它为零时,下一个acquire()要等待另一个线程的release(),从而控制实际工作的线程数量。
可以把它理解为多把相同的锁Locks。
信号量与线程池的区别:
- 信号量需要手动创建线程,线程池自动创建线程。
- 信号量需要手动通过
acquire()和release()来限流,线程池只用指定任务,其他自动。 - 信号量你创建了多少个线程就有多少个线程,没有获得(acquire)信号(semaphore)的线程等待,可能造成内存开销增大。
信号量类的函数介绍
acquire(blocking=True, timeout=None):返回是否成功调用,超时返回falserelease():释放一个信号量Semaphore(value=1):构造函数,只有一个参数。
下列代码介绍了信号量的使用以及与线程池的使用方法不同
1 | |
结果统计了时间,发现在线程池中线程数量和信号量相同时,耗时也几乎相同。
事件 event
假如其他线程知道另一个线程的某种状态才能进行下一步操作,就可以使用事件event来处理。这几乎是最简单的一个机制。
函数介绍:
is_set():当事件发生时(内部标志为True时)返回Trueset():通告事件发生(将内部标志设为True)clear():重置为未发生(将内部标志设为False)wait(timeout=None):阻塞线程直到事件发生,超时返回False。
下列代码通过考试的例子说明事件的使用:
1 | |

条件变量 Condition
这玩意我看了各种博主的各种教程,发现都看不懂,于是钻研了下官方文档,也是一知半解。
下面介绍我理解的某种条件下使用条件变量的方法。
Condition和某种锁相关联,但是他可以自动创建锁,服从上下文管理协议,用with方便,
acquire()和release()用来请求底层锁,像我这种不懂的就不要用了
wait(timeout=None):等待直到被通知(notify),超时返回False。wait_for(predicate, timeout=None):等待直到条件为真。predicate是一个可调用对象且返回值是布尔类型。这个方法会重复调用wait()直到满足判断。超时返回Falsenotify(n=1):唤醒处于wait状态(等待这个条件)的n个线程notify_all():唤醒处于wait状态(等待这个条件)的所有线程
使用条件变量的典型情况是将锁用于同步某些共享状态的权限,那些对某些状态的特定改变感兴趣的线程,它们应该重复调用wait(),直到看到所期望的改变发生;而对于修改某个状态的线程,修改完后调用notify()。
1 | |
定时器 Timer
是Thread的子类,像一个自定义线程一样。
定时器的函数介绍:
-
Timer(interval, function, args, kwargs):指定延时的事件和要执行的函数和参数。 -
Timer.start():开启定时器,经过一定事件后执行。 -
Timer.cancel():取消定时器。
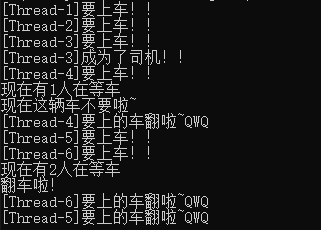
栅栏 Barrier
与其叫栅栏,不如叫开车对象。这个类的功能是等人齐就发车。并且一趟车走之后自动开启下一趟车,
翻车条件:超时、强行abort。
抛出错误条件:wait的时候翻车,wait的时候发新车。
下面介绍Barrier的函数和属性:
Barrier(parties, action=None, timeout=None):parties是数量,当阻塞的线程到达这个数量是就放行(当乘客到达这个数字时就发车)。action是随机抽取一个幸运线程,发车时让这个线程先执行action函数再干自己的事。超时后翻车。wait(timeout=None):线程上车,等开车,这里的timeout会覆盖Barrier的timeout,超时会强行发车。返回一个范围在0到parties-1的整数,每个线程都不同,可用于从所有线程中选择唯一的一个线程执行一些特别的工作。如果车翻了抛出BrokenBarrierError错误。
1 | |
reset():重置Barrier的状态,即再发一辆新车。假如有人上了旧车,那些人会抛出BrokenBarrierError错误abort():一般用来防止死锁,强行翻车。通常给Barrier设置超时时间而不用这个。parties:发车需要的人数量。n_waiting:正在车上的人的数量。broken:布尔值,栅栏有没有烂,即车有没有翻。
1 | |
参考资料
http://c.biancheng.net/view/2617.html
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!